 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQualiSpeech: A Speech Quality Assessment Dataset with Natural Language Reasoning and Descriptions
Mar 26, 2025



This paper explores a novel perspective to speech quality assessment by leveraging natural language descriptions, offering richer, more nuanced insights than traditional numerical scoring methods. Natural language feedback provides instructive recommendations and detailed evaluations, yet existing datasets lack the comprehensive annotations needed for this approach. To bridge this gap, we introduce QualiSpeech, a comprehensive low-level speech quality assessment dataset encompassing 11 key aspects and detailed natural language comments that include reasoning and contextual insights. Additionally, we propose the QualiSpeech Benchmark to evaluate the low-level speech understanding capabilities of auditory large language models (LLMs). Experimental results demonstrate that finetuned auditory LLMs can reliably generate detailed descriptions of noise and distortion, effectively identifying their types and temporal characteristics. The results further highlight the potential for incorporating reasoning to enhance the accuracy and reliability of quality assessments. The dataset will be released at https://huggingface.co/datasets/tsinghua-ee/QualiSpeech.
SALMONN-omni: A Codec-free LLM for Full-duplex Speech Understanding and Generation
Nov 27, 2024



Full-duplex multimodal large language models (LLMs) provide a unified framework for addressing diverse speech understanding and generation tasks, enabling more natural and seamless human-machine conversations. Unlike traditional modularised conversational AI systems, which separate speech recognition, understanding, and text-to-speech generation into distinct components, multimodal LLMs operate as single end-to-end models. This streamlined design eliminates error propagation across components and fully leverages the rich non-verbal information embedded in input speech signals. We introduce SALMONN-omni, a codec-free, full-duplex speech understanding and generation model capable of simultaneously listening to its own generated speech and background sounds while speaking. To support this capability, we propose a novel duplex spoken dialogue framework incorporating a ``thinking'' mechanism that facilitates asynchronous text and speech generation relying on embeddings instead of codecs (quantized speech and audio tokens). Experimental results demonstrate SALMONN-omni's versatility across a broad range of streaming speech tasks, including speech recognition, speech enhancement, and spoken question answering. Additionally, SALMONN-omni excels at managing turn-taking, barge-in, and echo cancellation scenarios, establishing its potential as a robust prototype for full-duplex conversational AI systems. To the best of our knowledge, SALMONN-omni is the first codec-free model of its kind. A full technical report along with model checkpoints will be released soon.
Adaptive Conditional Expert Selection Network for Multi-domain Recommendation
Nov 11, 2024Mixture-of-Experts (MOE) has recently become the de facto standard in Multi-domain recommendation (MDR) due to its powerful expressive ability. However, such MOE-based method typically employs all experts for each instance, leading to scalability issue and low-discriminability between domains and experts. Furthermore, the design of commonly used domain-specific networks exacerbates the scalability issues. To tackle the problems, We propose a novel method named CESAA consists of Conditional Expert Selection (CES) Module and Adaptive Expert Aggregation (AEA) Module to tackle these challenges. Specifically, CES first combines a sparse gating strategy with domain-shared experts. Then AEA utilizes mutual information loss to strengthen the correlations between experts and specific domains, and significantly improve the distinction between experts. As a result, only domain-shared experts and selected domain-specific experts are activated for each instance, striking a balance between computational efficiency and model performance. Experimental results on both public ranking and industrial retrieval datasets verify the effectiveness of our method in MDR tasks.
Enabling Auditory Large Language Models for Automatic Speech Quality Evaluation
Sep 25, 2024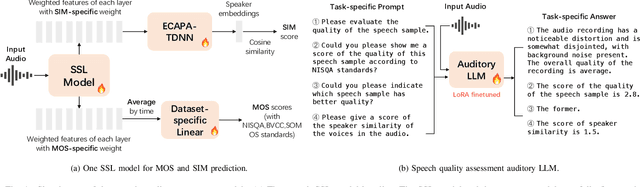
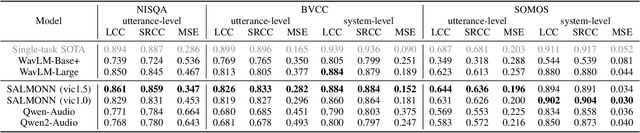


Speech quality assessment typically requires evaluating audio from multiple aspects, such as mean opinion score (MOS) and speaker similarity (SIM) etc., which can be challenging to cover using one small model designed for a single task. In this paper, we propose leveraging recently introduced auditory large language models (LLMs) for automatic speech quality assessment. By employing task-specific prompts, auditory LLMs are finetuned to predict MOS, SIM and A/B testing results, which are commonly used for evaluating text-to-speech systems. Additionally, the finetuned auditory LLM is able to generate natural language descriptions assessing aspects like noisiness, distortion, discontinuity, and overall quality, providing more interpretable outputs. Extensive experiments have been performed on the NISQA, BVCC, SOMOS and VoxSim speech quality datasets, using open-source auditory LLMs such as SALMONN, Qwen-Audio, and Qwen2-Audio. For the natural language descriptions task, a commercial model Google Gemini 1.5 Pro is also evaluated. The results demonstrate that auditory LLMs achieve competitive performance compared to state-of-the-art task-specific small models in predicting MOS and SIM, while also delivering promising results in A/B testing and natural language descriptions. Our data processing scripts and finetuned model checkpoints will be released upon acceptance.
Extract and Diffuse: Latent Integration for Improved Diffusion-based Speech and Vocal Enhancement
Sep 15, 2024Diffusion-based generative models have recently achieved remarkable results in speech and vocal enhancement due to their ability to model complex speech data distributions. While these models generalize well to unseen acoustic environments, they may not achieve the same level of fidelity as the discriminative models specifically trained to enhance particular acoustic conditions. In this paper, we propose Ex-Diff, a novel score-based diffusion model that integrates the latent representations produced by a discriminative model to improve speech and vocal enhancement, which combines the strengths of both generative and discriminative models. Experimental results on the widely used MUSDB dataset show relative improvements of 3.7% in SI-SDR and 10.0% in SI-SIR compared to the baseline diffusion model for speech and vocal enhancement tasks, respectively. Additionally, case studies are provided to further illustrate and analyze the complementary nature of generative and discriminative models in this context.
HMDN: Hierarchical Multi-Distribution Network for Click-Through Rate Prediction
Aug 02, 2024


As the recommendation service needs to address increasingly diverse distributions, such as multi-population, multi-scenario, multitarget, and multi-interest, more and more recent works have focused on multi-distribution modeling and achieved great progress. However, most of them only consider modeling in a single multi-distribution manner, ignoring that mixed multi-distributions often coexist and form hierarchical relationships. To address these challenges, we propose a flexible modeling paradigm, named Hierarchical Multi-Distribution Network (HMDN), which efficiently models these hierarchical relationships and can seamlessly integrate with existing multi-distribution methods, such as Mixture of-Experts (MoE) and Dynamic-Weight (DW) models. Specifically, we first design a hierarchical multi-distribution representation refinement module, employing a multi-level residual quantization to obtain fine-grained hierarchical representation. Then, the refined hierarchical representation is integrated into the existing single multi-distribution models, seamlessly expanding them into mixed multi-distribution models. Experimental results on both public and industrial datasets validate the effectiveness and flexibility of HMDN.
video-SALMONN: Speech-Enhanced Audio-Visual Large Language Models
Jun 22, 2024

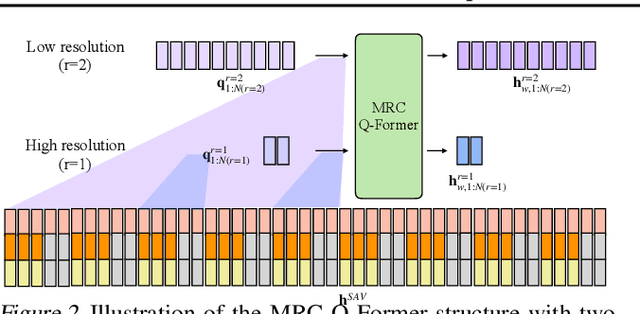

Speech understanding as an element of the more generic video understanding using audio-visual large language models (av-LLMs) is a crucial yet understudied aspect. This paper proposes video-SALMONN, a single end-to-end av-LLM for video processing, which can understand not only visual frame sequences, audio events and music, but speech as well. To obtain fine-grained temporal information required by speech understanding, while keeping efficient for other video elements, this paper proposes a novel multi-resolution causal Q-Former (MRC Q-Former) structure to connect pre-trained audio-visual encoders and the backbone large language model. Moreover, dedicated training approaches including the diversity loss and the unpaired audio-visual mixed training scheme are proposed to avoid frames or modality dominance. On the introduced speech-audio-visual evaluation benchmark, video-SALMONN achieves more than 25\% absolute accuracy improvements on the video-QA task and over 30\% absolute accuracy improvements on audio-visual QA tasks with human speech. In addition, video-SALMONN demonstrates remarkable video comprehension and reasoning abilities on tasks that are unprecedented by other av-LLMs. Our training code and model checkpoints are available at \texttt{\url{https://github.com/bytedance/SALMONN/}}.
Can Large Language Models Understand Spatial Audio?
Jun 12, 2024This paper explores enabling large language models (LLMs) to understand spatial information from multichannel audio, a skill currently lacking in auditory LLMs. By leveraging LLMs' advanced cognitive and inferential abilities, the aim is to enhance understanding of 3D environments via audio. We study 3 spatial audio tasks: sound source localization (SSL), far-field speech recognition (FSR), and localisation-informed speech extraction (LSE), achieving notable progress in each task. For SSL, our approach achieves an MAE of $2.70^{\circ}$ on the Spatial LibriSpeech dataset, substantially surpassing the prior benchmark of about $6.60^{\circ}$. Moreover, our model can employ spatial cues to improve FSR accuracy and execute LSE by selectively attending to sounds originating from a specified direction via text prompts, even amidst overlapping speech. These findings highlight the potential of adapting LLMs to grasp physical audio concepts, paving the way for LLM-based agents in 3D environments.
An Improved Empirical Fisher Approximation for Natural Gradient Descent
Jun 10, 2024Approximate Natural Gradient Descent (NGD) methods are an important family of optimisers for deep learning models, which use approximate Fisher information matrices to pre-condition gradients during training. The empirical Fisher (EF) method approximates the Fisher information matrix empirically by reusing the per-sample gradients collected during back-propagation. Despite its ease of implementation, the EF approximation has its theoretical and practical limitations. This paper first investigates the inversely-scaled projection issue of EF, which is shown to be a major cause of the poor empirical approximation quality. An improved empirical Fisher (iEF) method, motivated as a generalised NGD method from a loss reduction perspective, is proposed to address this issue, meanwhile retaining the practical convenience of EF. The exact iEF and EF methods are experimentally evaluated using practical deep learning setups, including widely-used setups for parameter-efficient fine-tuning of pre-trained models (T5-base with LoRA and Prompt-Tuning on GLUE tasks, and ViT with LoRA for CIFAR100). Optimisation experiments show that applying exact iEF as an optimiser provides strong convergence and generalisation. It achieves the best test performance and the lowest training loss for majority of the tasks, even when compared with well-tuned AdamW/Adafactor baselines. Additionally, under a novel empirical evaluation framework, the proposed iEF method shows consistently better approximation quality to the exact Natural Gradient updates than both EF and the more expensive sampled Fisher (SF). Further investigation also shows that the superior approximation quality of iEF is robust to damping across tasks and training stages. Improving existing approximate NGD optimisers with iEF is expected to lead to better convergence ability and stronger robustness to choice of damping.
M$^3$AV: A Multimodal, Multigenre, and Multipurpose Audio-Visual Academic Lecture Dataset
Mar 21, 2024Publishing open-source academic video recordings is an emergent and prevalent approach to sharing knowledge online. Such videos carry rich multimodal information including speech, the facial and body movements of the speakers, as well as the texts and pictures in the slides and possibly even the papers. Although multiple academic video datasets have been constructed and released, few of them support both multimodal content recognition and understanding tasks, which is partially due to the lack of high-quality human annotations. In this paper, we propose a novel multimodal, multigenre, and multipurpose audio-visual academic lecture dataset (M$^3$AV), which has almost 367 hours of videos from five sources covering computer science, mathematics, and medical and biology topics. With high-quality human annotations of the spoken and written words, in particular high-valued name entities, the dataset can be used for multiple audio-visual recognition and understanding tasks. Evaluations performed on contextual speech recognition, speech synthesis, and slide and script generation tasks demonstrate that the diversity of M$^3$AV makes it a challenging dataset.