 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnabling Auditory Large Language Models for Automatic Speech Quality Evaluation
Paper and Code
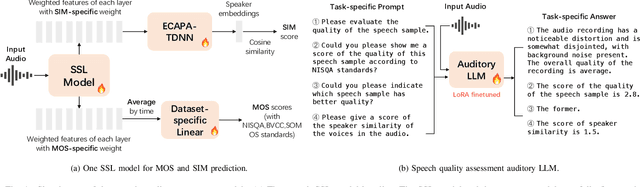
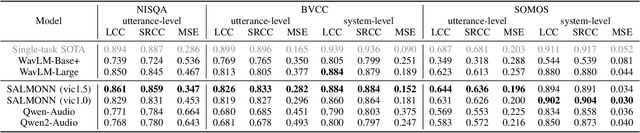


Speech quality assessment typically requires evaluating audio from multiple aspects, such as mean opinion score (MOS) and speaker similarity (SIM) etc., which can be challenging to cover using one small model designed for a single task. In this paper, we propose leveraging recently introduced auditory large language models (LLMs) for automatic speech quality assessment. By employing task-specific prompts, auditory LLMs are finetuned to predict MOS, SIM and A/B testing results, which are commonly used for evaluating text-to-speech systems. Additionally, the finetuned auditory LLM is able to generate natural language descriptions assessing aspects like noisiness, distortion, discontinuity, and overall quality, providing more interpretable outputs. Extensive experiments have been performed on the NISQA, BVCC, SOMOS and VoxSim speech quality datasets, using open-source auditory LLMs such as SALMONN, Qwen-Audio, and Qwen2-Audio. For the natural language descriptions task, a commercial model Google Gemini 1.5 Pro is also evaluated. The results demonstrate that auditory LLMs achieve competitive performance compared to state-of-the-art task-specific small models in predicting MOS and SIM, while also delivering promising results in A/B testing and natural language descriptions. Our data processing scripts and finetuned model checkpoints will be released upon acceptance.