 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOne Brain, Omni Modalities: Towards Unified Non-Invasive Brain Decoding with Large Language Models
Feb 25, 2026Deciphering brain function through non-invasive recordings requires synthesizing complementary high-frequency electromagnetic (EEG/MEG) and low-frequency metabolic (fMRI) signals. However, despite their shared neural origins, extreme discrepancies have traditionally confined these modalities to isolated analysis pipelines, hindering a holistic interpretation of brain activity. To bridge this fragmentation, we introduce \textbf{NOBEL}, a \textbf{n}euro-\textbf{o}mni-modal \textbf{b}rain-\textbf{e}ncoding \textbf{l}arge language model (LLM) that unifies these heterogeneous signals within the LLM's semantic embedding space. Our architecture integrates a unified encoder for EEG and MEG with a novel dual-path strategy for fMRI, aligning non-invasive brain signals and external sensory stimuli into a shared token space, then leverages an LLM as a universal backbone. Extensive evaluations demonstrate that NOBEL serves as a robust generalist across standard single-modal tasks. We also show that the synergistic fusion of electromagnetic and metabolic signals yields higher decoding accuracy than unimodal baselines, validating the complementary nature of multiple neural modalities. Furthermore, NOBEL exhibits strong capabilities in stimulus-aware decoding, effectively interpreting visual semantics from multi-subject fMRI data on the NSD and HAD datasets while uniquely leveraging direct stimulus inputs to verify causal links between sensory signals and neural responses. NOBEL thus takes a step towards unifying non-invasive brain decoding, demonstrating the promising potential of omni-modal brain understanding.
D-ORCA: Dialogue-Centric Optimization for Robust Audio-Visual Captioning
Feb 08, 2026Spoken dialogue is a primary source of information in videos; therefore, accurately identifying who spoke what and when is essential for deep video understanding. We introduce D-ORCA, a \textbf{d}ialogue-centric \textbf{o}mni-modal large language model optimized for \textbf{r}obust audio-visual \textbf{ca}ptioning. We further curate DVD, a large-scale, high-quality bilingual dataset comprising nearly 40,000 multi-party dialogue videos for training and 2000 videos for evaluation in English and Mandarin, addressing a critical gap in the open-source ecosystem. To ensure fine-grained captioning accuracy, we adopt group relative policy optimization with three novel reward functions that assess speaker attribution accuracy, global speech content accuracy, and sentence-level temporal boundary alignment. These rewards are derived from evaluation metrics widely used in speech processing and, to our knowledge, are applied for the first time as reinforcement learning objectives for audio-visual captioning. Extensive experiments demonstrate that D-ORCA substantially outperforms existing open-source models in speaker identification, speech recognition, and temporal grounding. Notably, despite having only 8 billion parameters, D-ORCA achieves performance competitive with Qwen3-Omni across several general-purpose audio-visual understanding benchmarks. Demos are available at \href{https://d-orca-llm.github.io/}{https://d-orca-llm.github.io/}. Our code, data, and checkpoints will be available at \href{https://github.com/WeChatCV/D-ORCA/}{https://github.com/WeChatCV/D-ORCA/}.
OCR-Enhanced Multimodal ASR Can Read While Listening
Jan 26, 2026Visual information, such as subtitles in a movie, often helps automatic speech recognition. In this paper, we propose Donut-Whisper, an audio-visual ASR model with dual encoder to leverage visual information to improve speech recognition performance in both English and Chinese. Donut-Whisper combines the advantage of the linear and the Q-Former-based modality alignment structures via a cross-attention module, generating more powerful audio-visual features. Meanwhile, we propose a lightweight knowledge distillation scheme showcasing the potential of using audio-visual models to teach audio-only models to achieve better performance. Moreover, we propose a new multilingual audio-visual speech recognition dataset based on movie clips containing both Chinese and English partitions. As a result, Donut-Whisper achieved significantly better performance on both English and Chinese partition of the dataset compared to both Donut and Whisper large V3 baselines. In particular, an absolute 5.75% WER reduction and a 16.5% absolute CER reduction were achieved on the English and Chinese sets respectively compared to the Whisper ASR baseline.
WAVE: Learning Unified & Versatile Audio-Visual Embeddings with Multimodal LLM
Sep 26, 2025



While embeddings from multimodal large language models (LLMs) excel as general-purpose representations, their application to dynamic modalities like audio and video remains underexplored. We introduce WAVE (\textbf{u}nified \& \textbf{v}ersatile \textbf{a}udio-\textbf{v}isual \textbf{e}mbeddings), the first LLM-based embedding that creates a unified representation space for text, audio, and video modalities. WAVE employs a novel hierarchical feature fusion strategy and a joint multi-modal, multi-task training approach to enable two key capabilities: any-to-any cross-modal retrieval and the generation of prompt-aware embeddings tailored to user instructions. Experimentally, WAVE sets a new state-of-the-art on the MMEB-v2 video benchmark and achieves superior results in audio and video-to-audio retrieval. Its prompt-aware nature also yields remarkable performance in multimodal question answering, significantly outperforming existing embedding models. Ablation studies validate our joint training strategy, demonstrating improved performance across all modalities. With a newly introduced benchmark for versatile audio-visual learning, WAVE opens up broad possibilities for cross-modal, any-to-any applications. Our code, checkpoints, and data will be released.
video-SALMONN 2: Captioning-Enhanced Audio-Visual Large Language Models
Jun 18, 2025Videos contain a wealth of information, and generating detailed and accurate descriptions in natural language is a key aspect of video understanding. In this paper, we present video-SALMONN 2, an advanced audio-visual large language model (LLM) with low-rank adaptation (LoRA) designed for enhanced video (with paired audio) captioning through directed preference optimisation (DPO). We propose new metrics to evaluate the completeness and accuracy of video descriptions, which are optimised using DPO. To further improve training, we propose a novel multi-round DPO (MrDPO) approach, which involves periodically updating the DPO reference model, merging and re-initialising the LoRA module as a proxy for parameter updates after each training round (1,000 steps), and incorporating guidance from ground-truth video captions to stabilise the process. Experimental results show that MrDPO significantly enhances video-SALMONN 2's captioning accuracy, reducing the captioning error rates by 28\%. The final video-SALMONN 2 model, with just 7 billion parameters, surpasses leading models such as GPT-4o and Gemini-1.5-Pro in video captioning tasks, while maintaining highly competitive performance to the state-of-the-art on widely used video question-answering benchmarks among models of similar size. Codes are available at \href{https://github.com/bytedance/video-SALMONN-2}{https://github.com/bytedance/video-SALMONN-2}.
ACVUBench: Audio-Centric Video Understanding Benchmark
Mar 25, 2025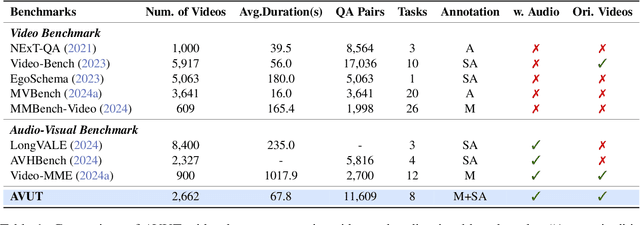
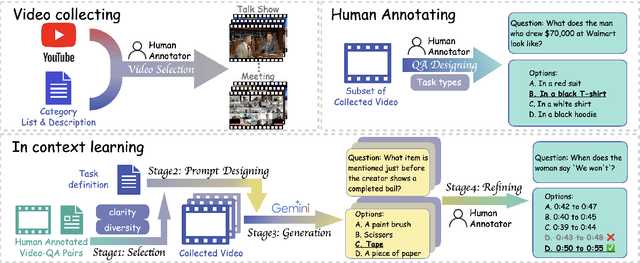
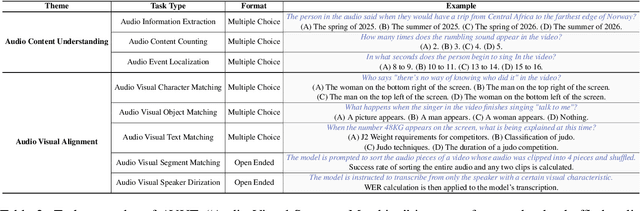

Audio often serves as an auxiliary modality in video understanding tasks of audio-visual large language models (LLMs), merely assisting in the comprehension of visual information. However, a thorough understanding of videos significantly depends on auditory information, as audio offers critical context, emotional cues, and semantic meaning that visual data alone often lacks. This paper proposes an audio-centric video understanding benchmark (ACVUBench) to evaluate the video comprehension capabilities of multimodal LLMs with a particular focus on auditory information. Specifically, ACVUBench incorporates 2,662 videos spanning 18 different domains with rich auditory information, together with over 13k high-quality human annotated or validated question-answer pairs. Moreover, ACVUBench introduces a suite of carefully designed audio-centric tasks, holistically testing the understanding of both audio content and audio-visual interactions in videos. A thorough evaluation across a diverse range of open-source and proprietary multimodal LLMs is performed, followed by the analyses of deficiencies in audio-visual LLMs. Demos are available at https://github.com/lark-png/ACVUBench.
Improving LLM Video Understanding with 16 Frames Per Second
Mar 18, 2025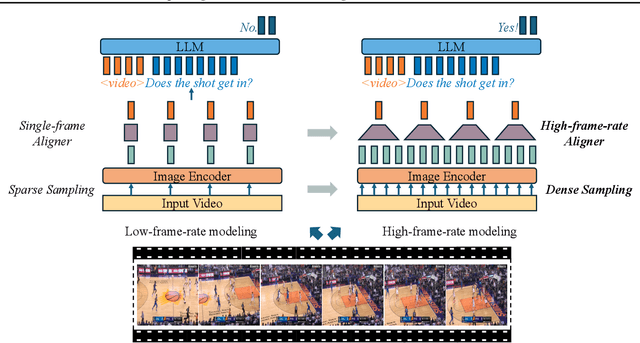
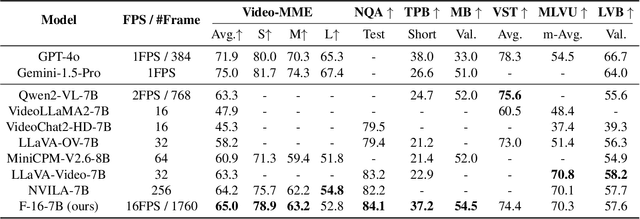
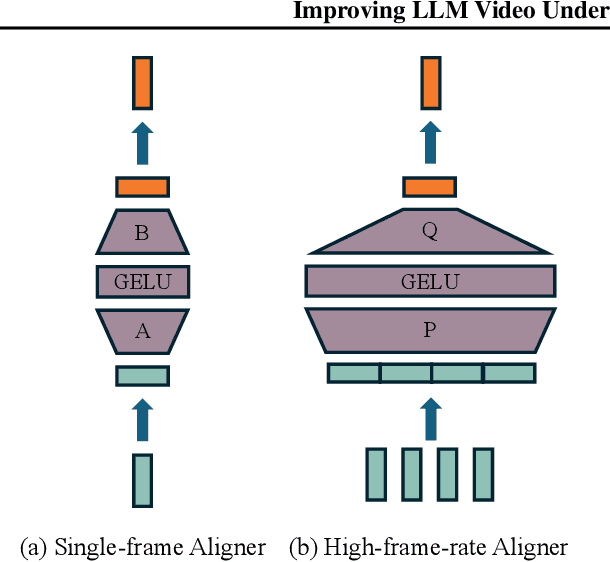
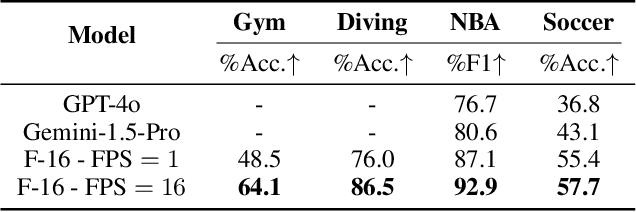
Human vision is dynamic and continuous. However, in video understanding with multimodal large language models (LLMs), existing methods primarily rely on static features extracted from images sampled at a fixed low frame rate of frame-per-second (FPS) $\leqslant$2, leading to critical visual information loss. In this paper, we introduce F-16, the first multimodal LLM designed for high-frame-rate video understanding. By increasing the frame rate to 16 FPS and compressing visual tokens within each 1-second clip, F-16 efficiently captures dynamic visual features while preserving key semantic information. Experimental results demonstrate that higher frame rates considerably enhance video understanding across multiple benchmarks, providing a new approach to improving video LLMs beyond scaling model size or training data. F-16 achieves state-of-the-art performance among 7-billion-parameter video LLMs on both general and fine-grained video understanding benchmarks, such as Video-MME and TemporalBench. Furthermore, F-16 excels in complex spatiotemporal tasks, including high-speed sports analysis (\textit{e.g.}, basketball, football, gymnastics, and diving), outperforming SOTA proprietary visual models like GPT-4o and Gemini-1.5-pro. Additionally, we introduce a novel decoding method for F-16 that enables highly efficient low-frame-rate inference without requiring model retraining. Upon acceptance, we will release the source code, model checkpoints, and data.
video-SALMONN-o1: Reasoning-enhanced Audio-visual Large Language Model
Feb 17, 2025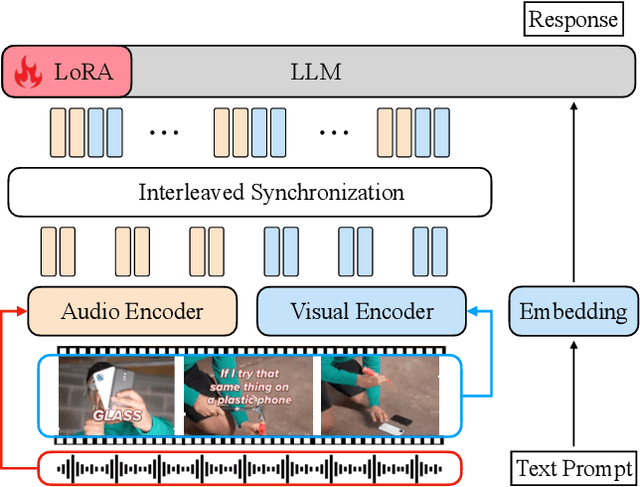
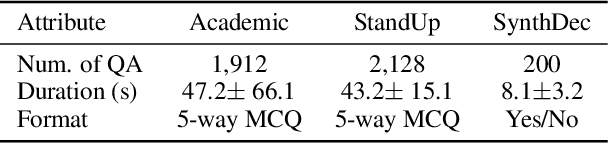
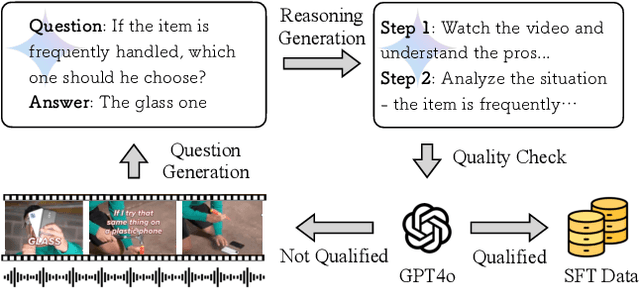
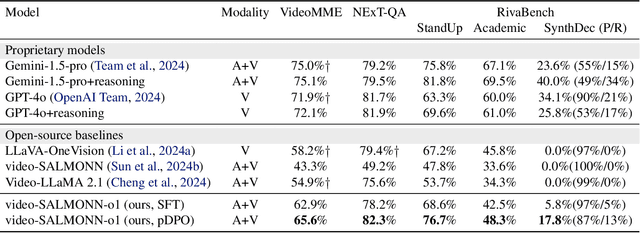
While recent advancements in reasoning optimization have significantly enhanced the capabilities of large language models (LLMs), existing efforts to improve reasoning have been limited to solving mathematical problems and focusing on visual graphical inputs, neglecting broader applications in general video understanding.This paper proposes video-SALMONN-o1, the first open-source reasoning-enhanced audio-visual LLM designed for general video understanding tasks. To enhance its reasoning abilities, we develop a reasoning-intensive dataset featuring challenging audio-visual questions with step-by-step solutions. We also propose process direct preference optimization (pDPO), which leverages contrastive step selection to achieve efficient step-level reward modelling tailored for multimodal inputs. Additionally, we introduce RivaBench, the first reasoning-intensive video understanding benchmark, featuring over 4,000 high-quality, expert-curated question-answer pairs across scenarios such as standup comedy, academic presentations, and synthetic video detection. video-SALMONN-o1 achieves 3-8% accuracy improvements over the LLaVA-OneVision baseline across different video reasoning benchmarks. Besides, pDPO achieves 6-8% improvements compared to the supervised fine-tuning model on RivaBench. Enhanced reasoning enables video-SALMONN-o1 zero-shot synthetic video detection capabilities.
Enhancing Multimodal LLM for Detailed and Accurate Video Captioning using Multi-Round Preference Optimization
Oct 09, 2024



Videos contain a wealth of information, and generating detailed and accurate descriptions in natural language is a key aspect of video understanding. In this paper, we present video-SALMONN 2, an advanced audio-visual large language model (LLM) with low-rank adaptation (LoRA) designed for enhanced video (with paired audio) captioning through directed preference optimization (DPO). We propose new metrics to evaluate the completeness and accuracy of video descriptions, which are optimized using DPO. To further improve training, we introduce a novel multi-round DPO (mrDPO) approach, which involves periodically updating the DPO reference model, merging and re-initializing the LoRA module as a proxy for parameter updates after each training round (1,000 steps), and incorporating guidance from ground-truth video captions to stabilize the process. To address potential catastrophic forgetting of non-captioning abilities due to mrDPO, we propose rebirth tuning, which finetunes the pre-DPO LLM by using the captions generated by the mrDPO-trained model as supervised labels. Experiments show that mrDPO significantly enhances video-SALMONN 2's captioning accuracy, reducing global and local error rates by 40\% and 20\%, respectively, while decreasing the repetition rate by 35\%. The final video-SALMONN 2 model, with just 7 billion parameters, surpasses leading models such as GPT-4o and Gemini-1.5-Pro in video captioning tasks, while maintaining competitive performance to the state-of-the-art on widely used video question-answering benchmark among models of similar size. Upon acceptance, we will release the code, model checkpoints, and training and test data. Demos are available at \href{https://video-salmonn-2.github.io}{https://video-salmonn-2.github.io}.
Enabling Auditory Large Language Models for Automatic Speech Quality Evaluation
Sep 25, 2024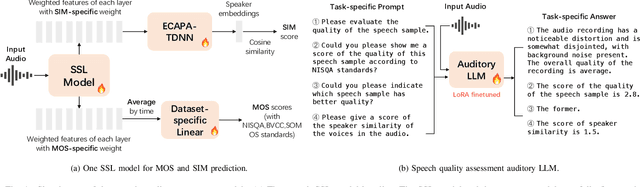
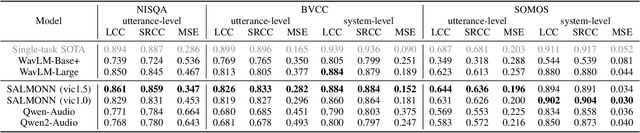


Speech quality assessment typically requires evaluating audio from multiple aspects, such as mean opinion score (MOS) and speaker similarity (SIM) etc., which can be challenging to cover using one small model designed for a single task. In this paper, we propose leveraging recently introduced auditory large language models (LLMs) for automatic speech quality assessment. By employing task-specific prompts, auditory LLMs are finetuned to predict MOS, SIM and A/B testing results, which are commonly used for evaluating text-to-speech systems. Additionally, the finetuned auditory LLM is able to generate natural language descriptions assessing aspects like noisiness, distortion, discontinuity, and overall quality, providing more interpretable outputs. Extensive experiments have been performed on the NISQA, BVCC, SOMOS and VoxSim speech quality datasets, using open-source auditory LLMs such as SALMONN, Qwen-Audio, and Qwen2-Audio. For the natural language descriptions task, a commercial model Google Gemini 1.5 Pro is also evaluated. The results demonstrate that auditory LLMs achieve competitive performance compared to state-of-the-art task-specific small models in predicting MOS and SIM, while also delivering promising results in A/B testing and natural language descriptions. Our data processing scripts and finetuned model checkpoints will be released upon acceptance.