 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeACVUBench: Audio-Centric Video Understanding Benchmark
Paper and Code
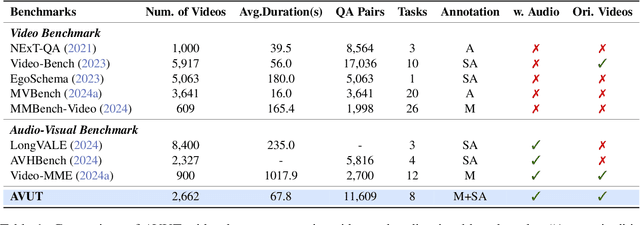
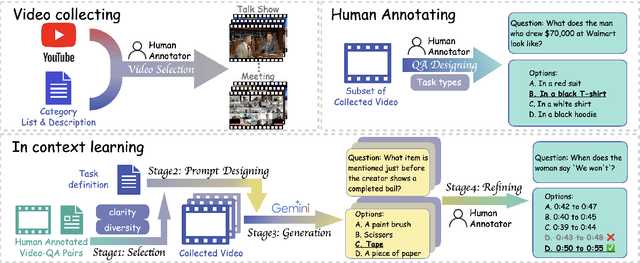
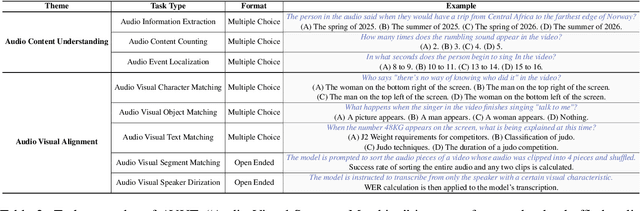

Audio often serves as an auxiliary modality in video understanding tasks of audio-visual large language models (LLMs), merely assisting in the comprehension of visual information. However, a thorough understanding of videos significantly depends on auditory information, as audio offers critical context, emotional cues, and semantic meaning that visual data alone often lacks. This paper proposes an audio-centric video understanding benchmark (ACVUBench) to evaluate the video comprehension capabilities of multimodal LLMs with a particular focus on auditory information. Specifically, ACVUBench incorporates 2,662 videos spanning 18 different domains with rich auditory information, together with over 13k high-quality human annotated or validated question-answer pairs. Moreover, ACVUBench introduces a suite of carefully designed audio-centric tasks, holistically testing the understanding of both audio content and audio-visual interactions in videos. A thorough evaluation across a diverse range of open-source and proprietary multimodal LLMs is performed, followed by the analyses of deficiencies in audio-visual LLMs. Demos are available at https://github.com/lark-png/ACVUBench.