 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQualiSpeech: A Speech Quality Assessment Dataset with Natural Language Reasoning and Descriptions
Mar 26, 2025



This paper explores a novel perspective to speech quality assessment by leveraging natural language descriptions, offering richer, more nuanced insights than traditional numerical scoring methods. Natural language feedback provides instructive recommendations and detailed evaluations, yet existing datasets lack the comprehensive annotations needed for this approach. To bridge this gap, we introduce QualiSpeech, a comprehensive low-level speech quality assessment dataset encompassing 11 key aspects and detailed natural language comments that include reasoning and contextual insights. Additionally, we propose the QualiSpeech Benchmark to evaluate the low-level speech understanding capabilities of auditory large language models (LLMs). Experimental results demonstrate that finetuned auditory LLMs can reliably generate detailed descriptions of noise and distortion, effectively identifying their types and temporal characteristics. The results further highlight the potential for incorporating reasoning to enhance the accuracy and reliability of quality assessments. The dataset will be released at https://huggingface.co/datasets/tsinghua-ee/QualiSpeech.
SALMONN-omni: A Codec-free LLM for Full-duplex Speech Understanding and Generation
Nov 27, 2024



Full-duplex multimodal large language models (LLMs) provide a unified framework for addressing diverse speech understanding and generation tasks, enabling more natural and seamless human-machine conversations. Unlike traditional modularised conversational AI systems, which separate speech recognition, understanding, and text-to-speech generation into distinct components, multimodal LLMs operate as single end-to-end models. This streamlined design eliminates error propagation across components and fully leverages the rich non-verbal information embedded in input speech signals. We introduce SALMONN-omni, a codec-free, full-duplex speech understanding and generation model capable of simultaneously listening to its own generated speech and background sounds while speaking. To support this capability, we propose a novel duplex spoken dialogue framework incorporating a ``thinking'' mechanism that facilitates asynchronous text and speech generation relying on embeddings instead of codecs (quantized speech and audio tokens). Experimental results demonstrate SALMONN-omni's versatility across a broad range of streaming speech tasks, including speech recognition, speech enhancement, and spoken question answering. Additionally, SALMONN-omni excels at managing turn-taking, barge-in, and echo cancellation scenarios, establishing its potential as a robust prototype for full-duplex conversational AI systems. To the best of our knowledge, SALMONN-omni is the first codec-free model of its kind. A full technical report along with model checkpoints will be released soon.
Enabling Auditory Large Language Models for Automatic Speech Quality Evaluation
Sep 25, 2024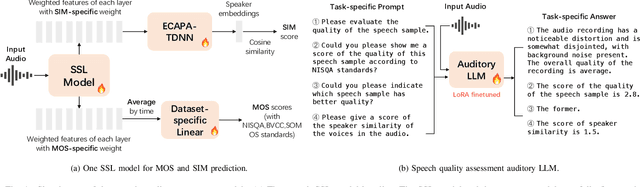
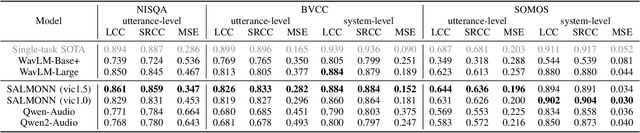


Speech quality assessment typically requires evaluating audio from multiple aspects, such as mean opinion score (MOS) and speaker similarity (SIM) etc., which can be challenging to cover using one small model designed for a single task. In this paper, we propose leveraging recently introduced auditory large language models (LLMs) for automatic speech quality assessment. By employing task-specific prompts, auditory LLMs are finetuned to predict MOS, SIM and A/B testing results, which are commonly used for evaluating text-to-speech systems. Additionally, the finetuned auditory LLM is able to generate natural language descriptions assessing aspects like noisiness, distortion, discontinuity, and overall quality, providing more interpretable outputs. Extensive experiments have been performed on the NISQA, BVCC, SOMOS and VoxSim speech quality datasets, using open-source auditory LLMs such as SALMONN, Qwen-Audio, and Qwen2-Audio. For the natural language descriptions task, a commercial model Google Gemini 1.5 Pro is also evaluated. The results demonstrate that auditory LLMs achieve competitive performance compared to state-of-the-art task-specific small models in predicting MOS and SIM, while also delivering promising results in A/B testing and natural language descriptions. Our data processing scripts and finetuned model checkpoints will be released upon acceptance.
video-SALMONN: Speech-Enhanced Audio-Visual Large Language Models
Jun 22, 2024

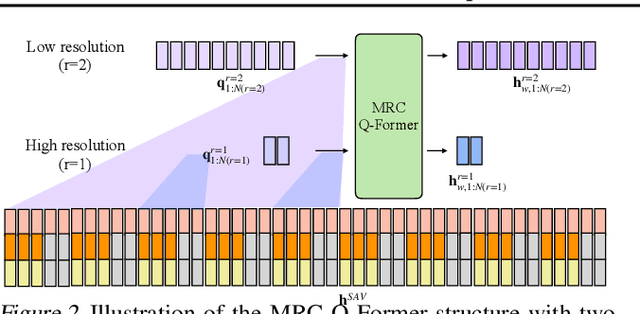

Speech understanding as an element of the more generic video understanding using audio-visual large language models (av-LLMs) is a crucial yet understudied aspect. This paper proposes video-SALMONN, a single end-to-end av-LLM for video processing, which can understand not only visual frame sequences, audio events and music, but speech as well. To obtain fine-grained temporal information required by speech understanding, while keeping efficient for other video elements, this paper proposes a novel multi-resolution causal Q-Former (MRC Q-Former) structure to connect pre-trained audio-visual encoders and the backbone large language model. Moreover, dedicated training approaches including the diversity loss and the unpaired audio-visual mixed training scheme are proposed to avoid frames or modality dominance. On the introduced speech-audio-visual evaluation benchmark, video-SALMONN achieves more than 25\% absolute accuracy improvements on the video-QA task and over 30\% absolute accuracy improvements on audio-visual QA tasks with human speech. In addition, video-SALMONN demonstrates remarkable video comprehension and reasoning abilities on tasks that are unprecedented by other av-LLMs. Our training code and model checkpoints are available at \texttt{\url{https://github.com/bytedance/SALMONN/}}.
Can Large Language Models Understand Spatial Audio?
Jun 12, 2024This paper explores enabling large language models (LLMs) to understand spatial information from multichannel audio, a skill currently lacking in auditory LLMs. By leveraging LLMs' advanced cognitive and inferential abilities, the aim is to enhance understanding of 3D environments via audio. We study 3 spatial audio tasks: sound source localization (SSL), far-field speech recognition (FSR), and localisation-informed speech extraction (LSE), achieving notable progress in each task. For SSL, our approach achieves an MAE of $2.70^{\circ}$ on the Spatial LibriSpeech dataset, substantially surpassing the prior benchmark of about $6.60^{\circ}$. Moreover, our model can employ spatial cues to improve FSR accuracy and execute LSE by selectively attending to sounds originating from a specified direction via text prompts, even amidst overlapping speech. These findings highlight the potential of adapting LLMs to grasp physical audio concepts, paving the way for LLM-based agents in 3D environments.
SALMONN: Towards Generic Hearing Abilities for Large Language Models
Oct 20, 2023



Hearing is arguably an essential ability of artificial intelligence (AI) agents in the physical world, which refers to the perception and understanding of general auditory information consisting of at least three types of sounds: speech, audio events, and music. In this paper, we propose SALMONN, a speech audio language music open neural network, built by integrating a pre-trained text-based large language model (LLM) with speech and audio encoders into a single multimodal model. SALMONN enables the LLM to directly process and understand general audio inputs and achieve competitive performances on a number of speech and audio tasks used in training, such as automatic speech recognition and translation, auditory-information-based question answering, emotion recognition, speaker verification, and music and audio captioning \textit{etc.} SALMONN also has a diverse set of emergent abilities unseen in the training, which includes but is not limited to speech translation to untrained languages, speech-based slot filling, spoken-query-based question answering, audio-based storytelling, and speech audio co-reasoning \textit{etc}. The presence of the cross-modal emergent abilities is studied, and a novel few-shot activation tuning approach is proposed to activate such abilities of SALMONN. To our knowledge, SALMONN is the first model of its type and can be regarded as a step towards AI with generic hearing abilities. An interactive demo of SALMONN is available at \texttt{\url{https://github.com/bytedance/SALMONN}}, and the training code and model checkpoints will be released upon acceptance.
Fine-grained Audio-Visual Joint Representations for Multimodal Large Language Models
Oct 10, 2023Audio-visual large language models (LLM) have drawn significant attention, yet the fine-grained combination of both input streams is rather under-explored, which is challenging but necessary for LLMs to understand general video inputs. To this end, a fine-grained audio-visual joint representation (FAVOR) learning framework for multimodal LLMs is proposed in this paper, which extends a text-based LLM to simultaneously perceive speech and audio events in the audio input stream and images or videos in the visual input stream, at the frame level. To fuse the audio and visual feature streams into joint representations and to align the joint space with the LLM input embedding space, we propose a causal Q-Former structure with a causal attention module to enhance the capture of causal relations of the audio-visual frames across time. An audio-visual evaluation benchmark (AVEB) is also proposed which comprises six representative single-modal tasks with five cross-modal tasks reflecting audio-visual co-reasoning abilities. While achieving competitive single-modal performance on audio, speech and image tasks in AVEB, FAVOR achieved over 20% accuracy improvements on the video question-answering task when fine-grained information or temporal causal reasoning is required. FAVOR, in addition, demonstrated remarkable video comprehension and reasoning abilities on tasks that are unprecedented by other multimodal LLMs. An interactive demo of FAVOR is available at https://github.com/BriansIDP/AudioVisualLLM.git, and the training code and model checkpoints will be released soon.
Connecting Speech Encoder and Large Language Model for ASR
Sep 26, 2023



The impressive capability and versatility of large language models (LLMs) have aroused increasing attention in automatic speech recognition (ASR), with several pioneering studies attempting to build integrated ASR models by connecting a speech encoder with an LLM. This paper presents a comparative study of three commonly used structures as connectors, including fully connected layers, multi-head cross-attention, and Q-Former. Speech encoders from the Whisper model series as well as LLMs from the Vicuna model series with different model sizes were studied. Experiments were performed on the commonly used LibriSpeech, Common Voice, and GigaSpeech datasets, where the LLMs with Q-Formers demonstrated consistent and considerable word error rate (WER) reductions over LLMs with other connector structures. Q-Former-based LLMs can generalise well to out-of-domain datasets, where 12% relative WER reductions over the Whisper baseline ASR model were achieved on the Eval2000 test set without using any in-domain training data from Switchboard. Moreover, a novel segment-level Q-Former is proposed to enable LLMs to recognise speech segments with a duration exceeding the limitation of the encoders, which results in 17% relative WER reductions over other connector structures on 90-second-long speech data.
Improving Frame-level Classifier for Word Timings with Non-peaky CTC in End-to-End Automatic Speech Recognition
Jun 09, 2023



End-to-end (E2E) systems have shown comparable performance to hybrid systems for automatic speech recognition (ASR). Word timings, as a by-product of ASR, are essential in many applications, especially for subtitling and computer-aided pronunciation training. In this paper, we improve the frame-level classifier for word timings in E2E system by introducing label priors in connectionist temporal classification (CTC) loss, which is adopted from prior works, and combining low-level Mel-scale filter banks with high-level ASR encoder output as input feature. On the internal Chinese corpus, the proposed method achieves 95.68%/94.18% compared to the hybrid system 93.0%/90.22% on the word timing accuracy metrics. It also surpass a previous E2E approach with an absolute increase of 4.80%/8.02% on the metrics on 7 languages. In addition, we further improve word timing accuracy by delaying CTC peaks with frame-wise knowledge distillation, though only experimenting on LibriSpeech.