 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLikeBench: Evaluating Subjective Likability in LLMs for Personalization
Dec 15, 2025A personalized LLM should remember user facts, apply them correctly, and adapt over time to provide responses that the user prefers. Existing LLM personalization benchmarks are largely centered on two axes: accurately recalling user information and accurately applying remembered information in downstream tasks. We argue that a third axis, likability, is both subjective and central to user experience, yet under-measured by current benchmarks. To measure likability holistically, we introduce LikeBench, a multi-session, dynamic evaluation framework that measures likability across multiple dimensions by how much an LLM can adapt over time to a user's preferences to provide more likable responses. In LikeBench, the LLMs engage in conversation with a simulated user and learn preferences only from the ongoing dialogue. As the interaction unfolds, models try to adapt to responses, and after each turn, they are evaluated for likability across seven dimensions by the same simulated user. To the best of our knowledge, we are the first to decompose likability into multiple diagnostic metrics: emotional adaptation, formality matching, knowledge adaptation, reference understanding, conversation length fit, humor fit, and callback, which makes it easier to pinpoint where a model falls short. To make the simulated user more realistic and discriminative, LikeBench uses fine-grained, psychologically grounded descriptive personas rather than the coarse high/low trait rating based personas used in prior work. Our benchmark shows that strong memory performance does not guarantee high likability: DeepSeek R1, with lower memory accuracy (86%, 17 facts/profile), outperformed Qwen3 by 28% on likability score despite Qwen3's higher memory accuracy (93%, 43 facts/profile). Even SOTA models like GPT-5 adapt well in short exchanges but show only limited robustness in longer, noisier interactions.
Not All Documents Are What You Need for Extracting Instruction Tuning Data
May 18, 2025Instruction tuning improves the performance of large language models (LLMs), but it heavily relies on high-quality training data. Recently, LLMs have been used to synthesize instruction data using seed question-answer (QA) pairs. However, these synthesized instructions often lack diversity and tend to be similar to the input seeds, limiting their applicability in real-world scenarios. To address this, we propose extracting instruction tuning data from web corpora that contain rich and diverse knowledge. A naive solution is to retrieve domain-specific documents and extract all QA pairs from them, but this faces two key challenges: (1) extracting all QA pairs using LLMs is prohibitively expensive, and (2) many extracted QA pairs may be irrelevant to the downstream tasks, potentially degrading model performance. To tackle these issues, we introduce EQUAL, an effective and scalable data extraction framework that iteratively alternates between document selection and high-quality QA pair extraction to enhance instruction tuning. EQUAL first clusters the document corpus based on embeddings derived from contrastive learning, then uses a multi-armed bandit strategy to efficiently identify clusters that are likely to contain valuable QA pairs. This iterative approach significantly reduces computational cost while boosting model performance. Experiments on AutoMathText and StackOverflow across four downstream tasks show that EQUAL reduces computational costs by 5-10x and improves accuracy by 2.5 percent on LLaMA-3.1-8B and Mistral-7B
Seed-ASR: Understanding Diverse Speech and Contexts with LLM-based Speech Recognition
Jul 05, 2024



Modern automatic speech recognition (ASR) model is required to accurately transcribe diverse speech signals (from different domains, languages, accents, etc) given the specific contextual information in various application scenarios. Classic end-to-end models fused with extra language models perform well, but mainly in data matching scenarios and are gradually approaching a bottleneck. In this work, we introduce Seed-ASR, a large language model (LLM) based speech recognition model. Seed-ASR is developed based on the framework of audio conditioned LLM (AcLLM), leveraging the capabilities of LLMs by inputting continuous speech representations together with contextual information into the LLM. Through stage-wise large-scale training and the elicitation of context-aware capabilities in LLM, Seed-ASR demonstrates significant improvement over end-to-end models on comprehensive evaluation sets, including multiple domains, accents/dialects and languages. Additionally, Seed-ASR can be further deployed to support specific needs in various scenarios without requiring extra language models. Compared to recently released large ASR models, Seed-ASR achieves 10%-40% reduction in word (or character, for Chinese) error rates on Chinese and English public test sets, further demonstrating its powerful performance.
video-SALMONN: Speech-Enhanced Audio-Visual Large Language Models
Jun 22, 2024

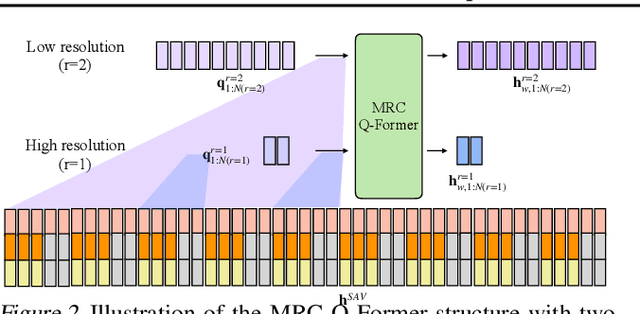

Speech understanding as an element of the more generic video understanding using audio-visual large language models (av-LLMs) is a crucial yet understudied aspect. This paper proposes video-SALMONN, a single end-to-end av-LLM for video processing, which can understand not only visual frame sequences, audio events and music, but speech as well. To obtain fine-grained temporal information required by speech understanding, while keeping efficient for other video elements, this paper proposes a novel multi-resolution causal Q-Former (MRC Q-Former) structure to connect pre-trained audio-visual encoders and the backbone large language model. Moreover, dedicated training approaches including the diversity loss and the unpaired audio-visual mixed training scheme are proposed to avoid frames or modality dominance. On the introduced speech-audio-visual evaluation benchmark, video-SALMONN achieves more than 25\% absolute accuracy improvements on the video-QA task and over 30\% absolute accuracy improvements on audio-visual QA tasks with human speech. In addition, video-SALMONN demonstrates remarkable video comprehension and reasoning abilities on tasks that are unprecedented by other av-LLMs. Our training code and model checkpoints are available at \texttt{\url{https://github.com/bytedance/SALMONN/}}.
Text-aware Speech Separation for Multi-talker Keyword Spotting
Jun 18, 2024



For noisy environments, ensuring the robustness of keyword spotting (KWS) systems is essential. While much research has focused on noisy KWS, less attention has been paid to multi-talker mixed speech scenarios. Unlike the usual cocktail party problem where multi-talker speech is separated using speaker clues, the key challenge here is to extract the target speech for KWS based on text clues. To address it, this paper proposes a novel Text-aware Permutation Determinization Training method for multi-talker KWS with a clue-based Speech Separation front-end (TPDT-SS). Our research highlights the critical role of SS front-ends and shows that incorporating keyword-specific clues into these models can greatly enhance the effectiveness. TPDT-SS shows remarkable success in addressing permutation problems in mixed keyword speech, thereby greatly boosting the performance of the backend. Additionally, fine-tuning our system on unseen mixed speech results in further performance improvement.
Can Large Language Models Understand Spatial Audio?
Jun 12, 2024This paper explores enabling large language models (LLMs) to understand spatial information from multichannel audio, a skill currently lacking in auditory LLMs. By leveraging LLMs' advanced cognitive and inferential abilities, the aim is to enhance understanding of 3D environments via audio. We study 3 spatial audio tasks: sound source localization (SSL), far-field speech recognition (FSR), and localisation-informed speech extraction (LSE), achieving notable progress in each task. For SSL, our approach achieves an MAE of $2.70^{\circ}$ on the Spatial LibriSpeech dataset, substantially surpassing the prior benchmark of about $6.60^{\circ}$. Moreover, our model can employ spatial cues to improve FSR accuracy and execute LSE by selectively attending to sounds originating from a specified direction via text prompts, even amidst overlapping speech. These findings highlight the potential of adapting LLMs to grasp physical audio concepts, paving the way for LLM-based agents in 3D environments.
SALMONN: Towards Generic Hearing Abilities for Large Language Models
Oct 20, 2023



Hearing is arguably an essential ability of artificial intelligence (AI) agents in the physical world, which refers to the perception and understanding of general auditory information consisting of at least three types of sounds: speech, audio events, and music. In this paper, we propose SALMONN, a speech audio language music open neural network, built by integrating a pre-trained text-based large language model (LLM) with speech and audio encoders into a single multimodal model. SALMONN enables the LLM to directly process and understand general audio inputs and achieve competitive performances on a number of speech and audio tasks used in training, such as automatic speech recognition and translation, auditory-information-based question answering, emotion recognition, speaker verification, and music and audio captioning \textit{etc.} SALMONN also has a diverse set of emergent abilities unseen in the training, which includes but is not limited to speech translation to untrained languages, speech-based slot filling, spoken-query-based question answering, audio-based storytelling, and speech audio co-reasoning \textit{etc}. The presence of the cross-modal emergent abilities is studied, and a novel few-shot activation tuning approach is proposed to activate such abilities of SALMONN. To our knowledge, SALMONN is the first model of its type and can be regarded as a step towards AI with generic hearing abilities. An interactive demo of SALMONN is available at \texttt{\url{https://github.com/bytedance/SALMONN}}, and the training code and model checkpoints will be released upon acceptance.
Fine-grained Audio-Visual Joint Representations for Multimodal Large Language Models
Oct 10, 2023Audio-visual large language models (LLM) have drawn significant attention, yet the fine-grained combination of both input streams is rather under-explored, which is challenging but necessary for LLMs to understand general video inputs. To this end, a fine-grained audio-visual joint representation (FAVOR) learning framework for multimodal LLMs is proposed in this paper, which extends a text-based LLM to simultaneously perceive speech and audio events in the audio input stream and images or videos in the visual input stream, at the frame level. To fuse the audio and visual feature streams into joint representations and to align the joint space with the LLM input embedding space, we propose a causal Q-Former structure with a causal attention module to enhance the capture of causal relations of the audio-visual frames across time. An audio-visual evaluation benchmark (AVEB) is also proposed which comprises six representative single-modal tasks with five cross-modal tasks reflecting audio-visual co-reasoning abilities. While achieving competitive single-modal performance on audio, speech and image tasks in AVEB, FAVOR achieved over 20% accuracy improvements on the video question-answering task when fine-grained information or temporal causal reasoning is required. FAVOR, in addition, demonstrated remarkable video comprehension and reasoning abilities on tasks that are unprecedented by other multimodal LLMs. An interactive demo of FAVOR is available at https://github.com/BriansIDP/AudioVisualLLM.git, and the training code and model checkpoints will be released soon.
Connecting Speech Encoder and Large Language Model for ASR
Sep 26, 2023



The impressive capability and versatility of large language models (LLMs) have aroused increasing attention in automatic speech recognition (ASR), with several pioneering studies attempting to build integrated ASR models by connecting a speech encoder with an LLM. This paper presents a comparative study of three commonly used structures as connectors, including fully connected layers, multi-head cross-attention, and Q-Former. Speech encoders from the Whisper model series as well as LLMs from the Vicuna model series with different model sizes were studied. Experiments were performed on the commonly used LibriSpeech, Common Voice, and GigaSpeech datasets, where the LLMs with Q-Formers demonstrated consistent and considerable word error rate (WER) reductions over LLMs with other connector structures. Q-Former-based LLMs can generalise well to out-of-domain datasets, where 12% relative WER reductions over the Whisper baseline ASR model were achieved on the Eval2000 test set without using any in-domain training data from Switchboard. Moreover, a novel segment-level Q-Former is proposed to enable LLMs to recognise speech segments with a duration exceeding the limitation of the encoders, which results in 17% relative WER reductions over other connector structures on 90-second-long speech data.
Incorporating Class-based Language Model for Named Entity Recognition in Factorized Neural Transducer
Sep 14, 2023In spite of the excellent strides made by end-to-end (E2E) models in speech recognition in recent years, named entity recognition is still challenging but critical for semantic understanding. In order to enhance the ability to recognize named entities in E2E models, previous studies mainly focus on various rule-based or attention-based contextual biasing algorithms. However, their performance might be sensitive to the biasing weight or degraded by excessive attention to the named entity list, along with a risk of false triggering. Inspired by the success of the class-based language model (LM) in named entity recognition in conventional hybrid systems and the effective decoupling of acoustic and linguistic information in the factorized neural Transducer (FNT), we propose a novel E2E model to incorporate class-based LMs into FNT, which is referred as C-FNT. In C-FNT, the language model score of named entities can be associated with the name class instead of its surface form. The experimental results show that our proposed C-FNT presents significant error reduction in named entities without hurting performance in general word recognition.