 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNot All Documents Are What You Need for Extracting Instruction Tuning Data
May 18, 2025Instruction tuning improves the performance of large language models (LLMs), but it heavily relies on high-quality training data. Recently, LLMs have been used to synthesize instruction data using seed question-answer (QA) pairs. However, these synthesized instructions often lack diversity and tend to be similar to the input seeds, limiting their applicability in real-world scenarios. To address this, we propose extracting instruction tuning data from web corpora that contain rich and diverse knowledge. A naive solution is to retrieve domain-specific documents and extract all QA pairs from them, but this faces two key challenges: (1) extracting all QA pairs using LLMs is prohibitively expensive, and (2) many extracted QA pairs may be irrelevant to the downstream tasks, potentially degrading model performance. To tackle these issues, we introduce EQUAL, an effective and scalable data extraction framework that iteratively alternates between document selection and high-quality QA pair extraction to enhance instruction tuning. EQUAL first clusters the document corpus based on embeddings derived from contrastive learning, then uses a multi-armed bandit strategy to efficiently identify clusters that are likely to contain valuable QA pairs. This iterative approach significantly reduces computational cost while boosting model performance. Experiments on AutoMathText and StackOverflow across four downstream tasks show that EQUAL reduces computational costs by 5-10x and improves accuracy by 2.5 percent on LLaMA-3.1-8B and Mistral-7B
InternLM2 Technical Report
Mar 26, 2024



The evolution of Large Language Models (LLMs) like ChatGPT and GPT-4 has sparked discussions on the advent of Artificial General Intelligence (AGI). However, replicating such advancements in open-source models has been challenging. This paper introduces InternLM2, an open-source LLM that outperforms its predecessors in comprehensive evaluations across 6 dimensions and 30 benchmarks, long-context modeling, and open-ended subjective evaluations through innovative pre-training and optimization techniques. The pre-training process of InternLM2 is meticulously detailed, highlighting the preparation of diverse data types including text, code, and long-context data. InternLM2 efficiently captures long-term dependencies, initially trained on 4k tokens before advancing to 32k tokens in pre-training and fine-tuning stages, exhibiting remarkable performance on the 200k ``Needle-in-a-Haystack" test. InternLM2 is further aligned using Supervised Fine-Tuning (SFT) and a novel Conditional Online Reinforcement Learning from Human Feedback (COOL RLHF) strategy that addresses conflicting human preferences and reward hacking. By releasing InternLM2 models in different training stages and model sizes, we provide the community with insights into the model's evolution.
WanJuan-CC: A Safe and High-Quality Open-sourced English Webtext Dataset
Mar 12, 2024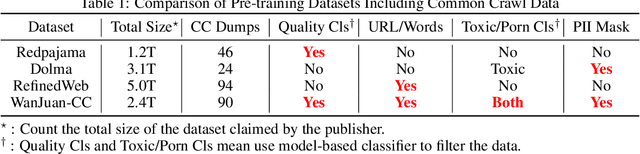
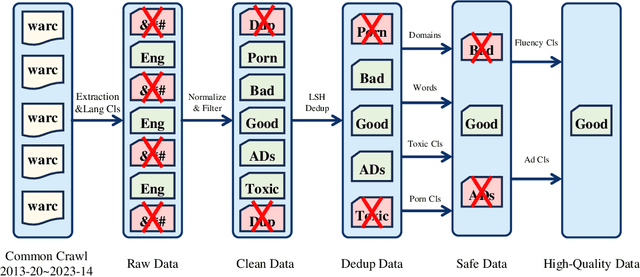
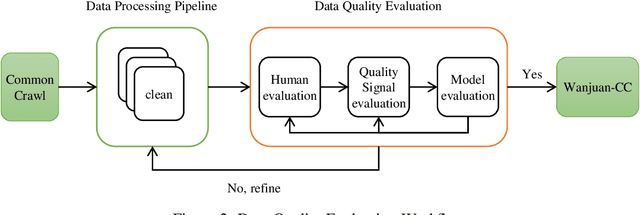

This paper presents WanJuan-CC, a safe and high-quality open-sourced English webtext dataset derived from Common Crawl data. The study addresses the challenges of constructing large-scale pre-training datasets for language models, which require vast amounts of high-quality data. A comprehensive process was designed to handle Common Crawl data, including extraction, heuristic rule filtering, fuzzy deduplication, content safety filtering, and data quality filtering. From approximately 68 billion original English documents, we obtained 2.22T Tokens of safe data and selected 1.0T Tokens of high-quality data as part of WanJuan-CC. We have open-sourced 100B Tokens from this dataset. The paper also provides statistical information related to data quality, enabling users to select appropriate data according to their needs. To evaluate the quality and utility of the dataset, we trained 1B-parameter and 3B-parameter models using WanJuan-CC and another dataset, RefinedWeb. Results show that WanJuan-CC performs better on validation datasets and downstream tasks.
InternLM-Math: Open Math Large Language Models Toward Verifiable Reasoning
Feb 09, 2024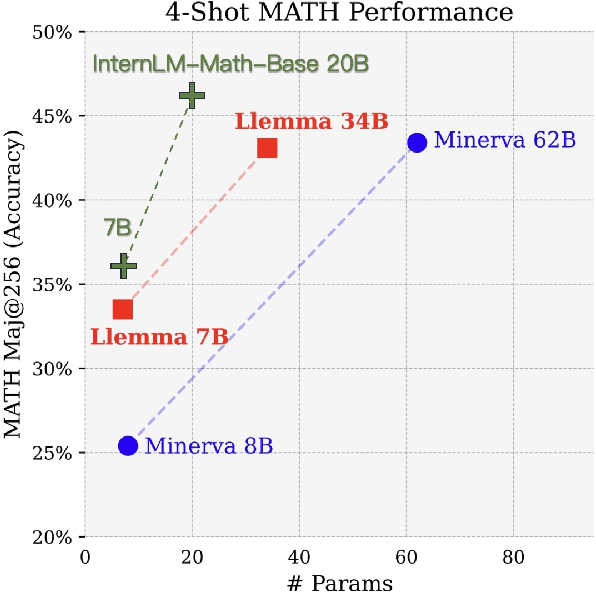
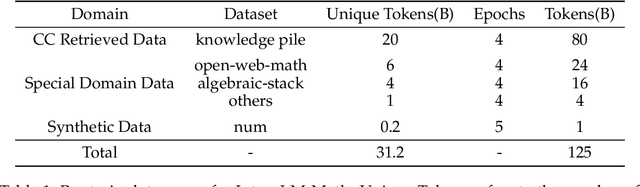
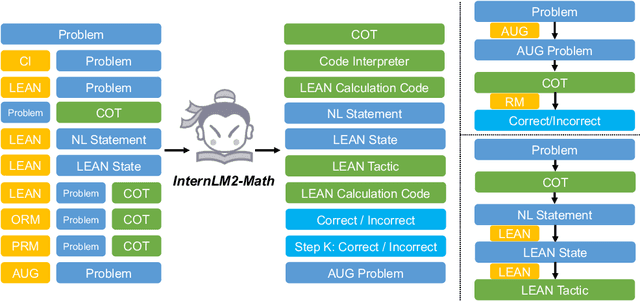
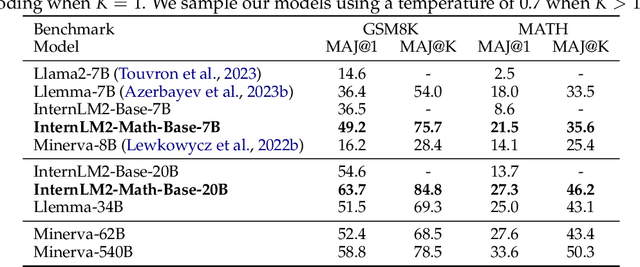
The math abilities of large language models can represent their abstract reasoning ability. In this paper, we introduce and open-source our math reasoning LLMs InternLM-Math which is continue pre-trained from InternLM2. We unify chain-of-thought reasoning, reward modeling, formal reasoning, data augmentation, and code interpreter in a unified seq2seq format and supervise our model to be a versatile math reasoner, verifier, prover, and augmenter. These abilities can be used to develop the next math LLMs or self-iteration. InternLM-Math obtains open-sourced state-of-the-art performance under the setting of in-context learning, supervised fine-tuning, and code-assisted reasoning in various informal and formal benchmarks including GSM8K, MATH, Hungary math exam, MathBench-ZH, and MiniF2F. Our pre-trained model achieves 30.3 on the MiniF2F test set without fine-tuning. We further explore how to use LEAN to solve math problems and study its performance under the setting of multi-task learning which shows the possibility of using LEAN as a unified platform for solving and proving in math. Our models, codes, and data are released at \url{https://github.com/InternLM/InternLM-Math}.
CoLLiE: Collaborative Training of Large Language Models in an Efficient Way
Dec 01, 2023



Large language models (LLMs) are increasingly pivotal in a wide range of natural language processing tasks. Access to pre-trained models, courtesy of the open-source community, has made it possible to adapt these models to specific applications for enhanced performance. However, the substantial resources required for training these models necessitate efficient solutions. This paper introduces CoLLiE, an efficient library that facilitates collaborative training of large language models using 3D parallelism, parameter-efficient fine-tuning (PEFT) methods, and optimizers such as Lion, Adan, Sophia, LOMO and AdaLomo. With its modular design and comprehensive functionality, CoLLiE offers a balanced blend of efficiency, ease of use, and customization. CoLLiE has proven superior training efficiency in comparison with prevalent solutions in pre-training and fine-tuning scenarios. Furthermore, we provide an empirical evaluation of the correlation between model size and GPU memory consumption under different optimization methods, as well as an analysis of the throughput. Lastly, we carry out a comprehensive comparison of various optimizers and PEFT methods within the instruction-tuning context. CoLLiE is available at https://github.com/OpenLMLab/collie.