 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLong-horizon Reasoning Agent for Olympiad-Level Mathematical Problem Solving
Dec 12, 2025Large Reasoning Models (LRMs) have expanded the mathematical reasoning frontier through Chain-of-Thought (CoT) techniques and Reinforcement Learning with Verifiable Rewards (RLVR), capable of solving AIME-level problems. However, the performance of LRMs is heavily dependent on the extended reasoning context length. For solving ultra-hard problems like those in the International Mathematical Olympiad (IMO), the required reasoning complexity surpasses the space that an LRM can explore in a single round. Previous works attempt to extend the reasoning context of LRMs but remain prompt-based and built upon proprietary models, lacking systematic structures and training pipelines. Therefore, this paper introduces Intern-S1-MO, a long-horizon math agent that conducts multi-round hierarchical reasoning, composed of an LRM-based multi-agent system including reasoning, summary, and verification. By maintaining a compact memory in the form of lemmas, Intern-S1-MO can more freely explore the lemma-rich reasoning spaces in multiple reasoning stages, thereby breaking through the context constraints for IMO-level math problems. Furthermore, we propose OREAL-H, an RL framework for training the LRM using the online explored trajectories to simultaneously bootstrap the reasoning ability of LRM and elevate the overall performance of Intern-S1-MO. Experiments show that Intern-S1-MO can obtain 26 out of 35 points on the non-geometry problems of IMO2025, matching the performance of silver medalists. It also surpasses the current advanced LRMs on inference benchmarks such as HMMT2025, AIME2025, and CNMO2025. In addition, our agent officially participates in CMO2025 and achieves a score of 102/126 under the judgment of human experts, reaching the gold medal level.
Achieving Olympia-Level Geometry Large Language Model Agent via Complexity Boosting Reinforcement Learning
Dec 12, 2025Large language model (LLM) agents exhibit strong mathematical problem-solving abilities and can even solve International Mathematical Olympiad (IMO) level problems with the assistance of formal proof systems. However, due to weak heuristics for auxiliary constructions, AI for geometry problem solving remains dominated by expert models such as AlphaGeometry 2, which rely heavily on large-scale data synthesis and search for both training and evaluation. In this work, we make the first attempt to build a medalist-level LLM agent for geometry and present InternGeometry. InternGeometry overcomes the heuristic limitations in geometry by iteratively proposing propositions and auxiliary constructions, verifying them with a symbolic engine, and reflecting on the engine's feedback to guide subsequent proposals. A dynamic memory mechanism enables InternGeometry to conduct more than two hundred interactions with the symbolic engine per problem. To further accelerate learning, we introduce Complexity-Boosting Reinforcement Learning (CBRL), which gradually increases the complexity of synthesized problems across training stages. Built on InternThinker-32B, InternGeometry solves 44 of 50 IMO geometry problems (2000-2024), exceeding the average gold medalist score (40.9), using only 13K training examples, just 0.004% of the data used by AlphaGeometry 2, demonstrating the potential of LLM agents on expert-level geometry tasks. InternGeometry can also propose novel auxiliary constructions for IMO problems that do not appear in human solutions. We will release the model, data, and symbolic engine to support future research.
Semi-off-Policy Reinforcement Learning for Vision-Language Slow-thinking Reasoning
Jul 22, 2025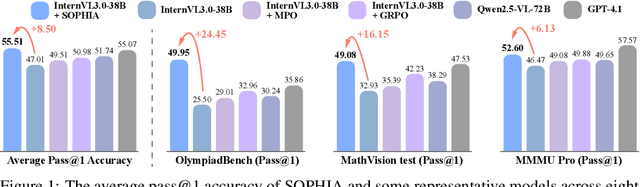
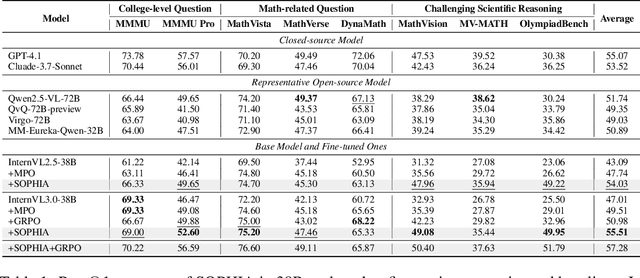
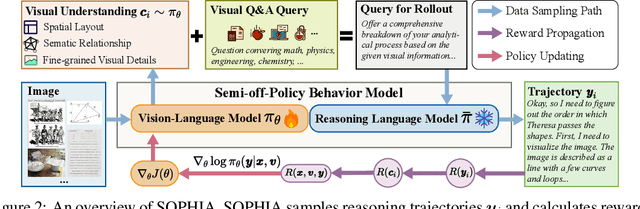
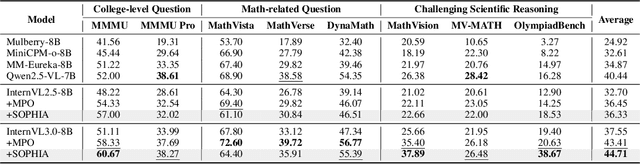
Enhancing large vision-language models (LVLMs) with visual slow-thinking reasoning is crucial for solving complex multimodal tasks. However, since LVLMs are mainly trained with vision-language alignment, it is difficult to adopt on-policy reinforcement learning (RL) to develop the slow thinking ability because the rollout space is restricted by its initial abilities. Off-policy RL offers a way to go beyond the current policy, but directly distilling trajectories from external models may cause visual hallucinations due to mismatched visual perception abilities across models. To address these issues, this paper proposes SOPHIA, a simple and scalable Semi-Off-Policy RL for vision-language slow-tHInking reAsoning. SOPHIA builds a semi-off-policy behavior model by combining on-policy visual understanding from a trainable LVLM with off-policy slow-thinking reasoning from a language model, assigns outcome-based rewards to reasoning, and propagates visual rewards backward. Then LVLM learns slow-thinking reasoning ability from the obtained reasoning trajectories using propagated rewards via off-policy RL algorithms. Extensive experiments with InternVL2.5 and InternVL3.0 with 8B and 38B sizes show the effectiveness of SOPHIA. Notably, SOPHIA improves InternVL3.0-38B by 8.50% in average, reaching state-of-the-art performance among open-source LVLMs on multiple multimodal reasoning benchmarks, and even outperforms some closed-source models (e.g., GPT-4.1) on the challenging MathVision and OlympiadBench, achieving 49.08% and 49.95% pass@1 accuracy, respectively. Analysis shows SOPHIA outperforms supervised fine-tuning and direct on-policy RL methods, offering a better policy initialization for further on-policy training.
The Imitation Game: Turing Machine Imitator is Length Generalizable Reasoner
Jul 17, 2025Length generalization, the ability to solve problems of longer sequences than those observed during training, poses a core challenge of Transformer-based large language models (LLM). Although existing studies have predominantly focused on data-driven approaches for arithmetic operations and symbolic manipulation tasks, these approaches tend to be task-specific with limited overall performance. To pursue a more general solution, this paper focuses on a broader case of reasoning problems that are computable, i.e., problems that algorithms can solve, thus can be solved by the Turing Machine. From this perspective, this paper proposes Turing MAchine Imitation Learning (TAIL) to improve the length generalization ability of LLMs. TAIL synthesizes chain-of-thoughts (CoT) data that imitate the execution process of a Turing Machine by computer programs, which linearly expands the reasoning steps into atomic states to alleviate shortcut learning and explicit memory fetch mechanism to reduce the difficulties of dynamic and long-range data access in elementary operations. To validate the reliability and universality of TAIL, we construct a challenging synthetic dataset covering 8 classes of algorithms and 18 tasks. Without bells and whistles, TAIL significantly improves the length generalization ability as well as the performance of Qwen2.5-7B on various tasks using only synthetic data, surpassing previous methods and DeepSeek-R1. The experimental results reveal that the key concepts in the Turing Machine, instead of the thinking styles, are indispensable for TAIL for length generalization, through which the model exhibits read-and-write behaviors consistent with the properties of the Turing Machine in their attention layers. This work provides a promising direction for future research in the learning of LLM reasoning from synthetic data.
RIG: Synergizing Reasoning and Imagination in End-to-End Generalist Policy
Mar 31, 2025Reasoning before action and imagining potential outcomes (i.e., world models) are essential for embodied agents operating in complex open-world environments. Yet, prior work either incorporates only one of these abilities in an end-to-end agent or integrates multiple specialized models into an agent system, limiting the learning efficiency and generalization of the policy. Thus, this paper makes the first attempt to synergize Reasoning and Imagination in an end-to-end Generalist policy, termed RIG. To train RIG in an end-to-end manner, we construct a data pipeline that progressively integrates and enriches the content of imagination and reasoning in the trajectories collected from existing agents. The joint learning of reasoning and next image generation explicitly models the inherent correlation between reasoning, action, and dynamics of environments, and thus exhibits more than $17\times$ sample efficiency improvements and generalization in comparison with previous works. During inference, RIG first reasons about the next action, produces potential action, and then predicts the action outcomes, which offers the agent a chance to review and self-correct based on the imagination before taking real actions. Experimental results show that the synergy of reasoning and imagination not only improves the robustness, generalization, and interoperability of generalist policy but also enables test-time scaling to enhance overall performance.
Exploring the Limit of Outcome Reward for Learning Mathematical Reasoning
Feb 10, 2025Reasoning abilities, especially those for solving complex math problems, are crucial components of general intelligence. Recent advances by proprietary companies, such as o-series models of OpenAI, have made remarkable progress on reasoning tasks. However, the complete technical details remain unrevealed, and the techniques that are believed certainly to be adopted are only reinforcement learning (RL) and the long chain of thoughts. This paper proposes a new RL framework, termed OREAL, to pursue the performance limit that can be achieved through \textbf{O}utcome \textbf{RE}w\textbf{A}rd-based reinforcement \textbf{L}earning for mathematical reasoning tasks, where only binary outcome rewards are easily accessible. We theoretically prove that behavior cloning on positive trajectories from best-of-N (BoN) sampling is sufficient to learn the KL-regularized optimal policy in binary feedback environments. This formulation further implies that the rewards of negative samples should be reshaped to ensure the gradient consistency between positive and negative samples. To alleviate the long-existing difficulties brought by sparse rewards in RL, which are even exacerbated by the partial correctness of the long chain of thought for reasoning tasks, we further apply a token-level reward model to sample important tokens in reasoning trajectories for learning. With OREAL, for the first time, a 7B model can obtain 94.0 pass@1 accuracy on MATH-500 through RL, being on par with 32B models. OREAL-32B also surpasses previous 32B models trained by distillation with 95.0 pass@1 accuracy on MATH-500. Our investigation also indicates the importance of initial policy models and training queries for RL. Code, models, and data will be released to benefit future research\footnote{https://github.com/InternLM/OREAL}.
Are Your LLMs Capable of Stable Reasoning?
Dec 17, 2024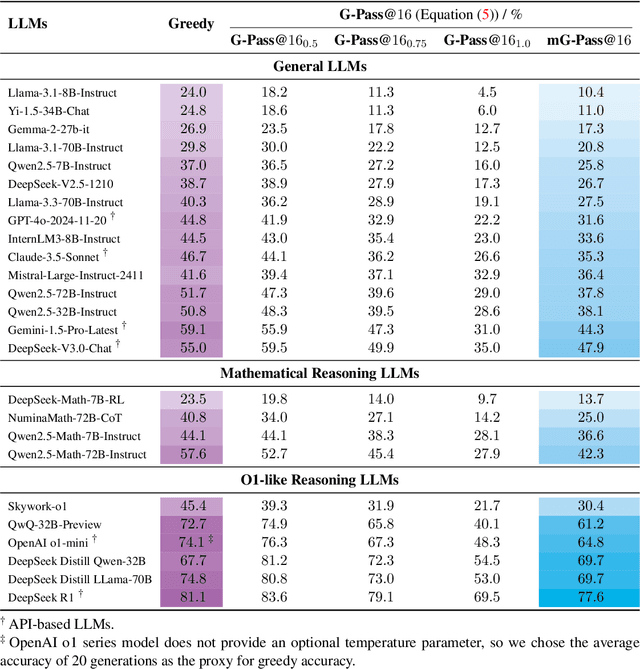
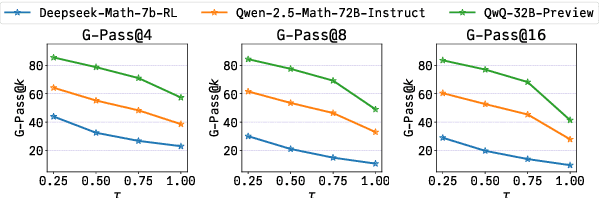
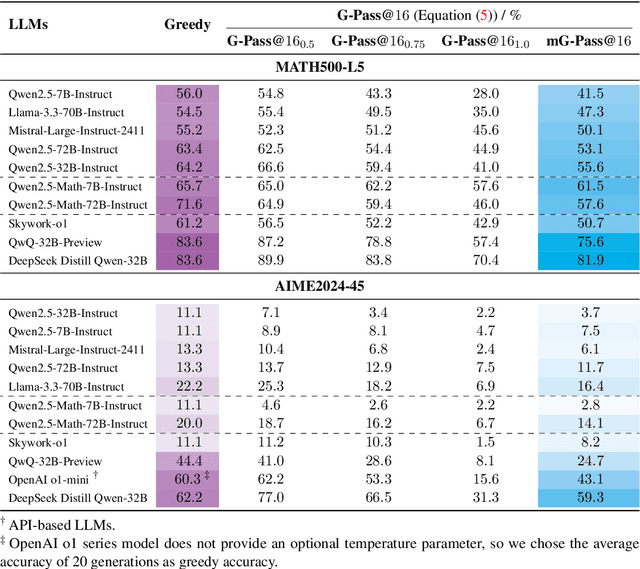
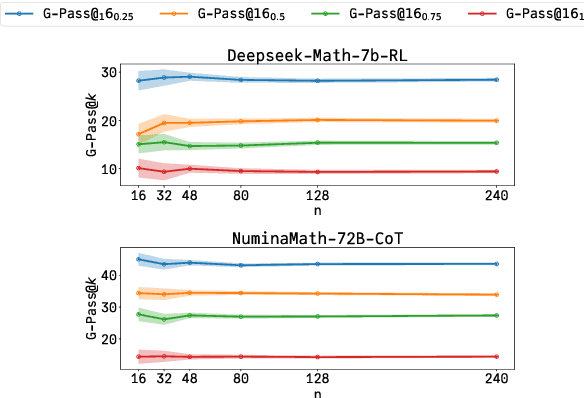
The rapid advancement of Large Language Models (LLMs) has demonstrated remarkable progress in complex reasoning tasks. However, a significant discrepancy persists between benchmark performances and real-world applications. We identify this gap as primarily stemming from current evaluation protocols and metrics, which inadequately capture the full spectrum of LLM capabilities, particularly in complex reasoning tasks where both accuracy and consistency are crucial. This work makes two key contributions. First, we introduce G-Pass@k, a novel evaluation metric that provides a continuous assessment of model performance across multiple sampling attempts, quantifying both the model's peak performance potential and its stability. Second, we present LiveMathBench, a dynamic benchmark comprising challenging, contemporary mathematical problems designed to minimize data leakage risks during evaluation. Through extensive experiments using G-Pass@k on state-of-the-art LLMs with LiveMathBench, we provide comprehensive insights into both their maximum capabilities and operational consistency. Our findings reveal substantial room for improvement in LLMs' "realistic" reasoning capabilities, highlighting the need for more robust evaluation methods. The benchmark and detailed results are available at: https://github.com/open-compass/GPassK.
MindSearch: Mimicking Human Minds Elicits Deep AI Searcher
Jul 29, 2024



Information seeking and integration is a complex cognitive task that consumes enormous time and effort. Inspired by the remarkable progress of Large Language Models, recent works attempt to solve this task by combining LLMs and search engines. However, these methods still obtain unsatisfying performance due to three challenges: (1) complex requests often cannot be accurately and completely retrieved by the search engine once (2) corresponding information to be integrated is spread over multiple web pages along with massive noise, and (3) a large number of web pages with long contents may quickly exceed the maximum context length of LLMs. Inspired by the cognitive process when humans solve these problems, we introduce MindSearch to mimic the human minds in web information seeking and integration, which can be instantiated by a simple yet effective LLM-based multi-agent framework. The WebPlanner models the human mind of multi-step information seeking as a dynamic graph construction process: it decomposes the user query into atomic sub-questions as nodes in the graph and progressively extends the graph based on the search result from WebSearcher. Tasked with each sub-question, WebSearcher performs hierarchical information retrieval with search engines and collects valuable information for WebPlanner. The multi-agent design of MindSearch enables the whole framework to seek and integrate information parallelly from larger-scale (e.g., more than 300) web pages in 3 minutes, which is worth 3 hours of human effort. MindSearch demonstrates significant improvement in the response quality in terms of depth and breadth, on both close-set and open-set QA problems. Besides, responses from MindSearch based on InternLM2.5-7B are preferable by humans to ChatGPT-Web and Perplexity.ai applications, which implies that MindSearch can already deliver a competitive solution to the proprietary AI search engine.
CIBench: Evaluating Your LLMs with a Code Interpreter Plugin
Jul 15, 2024

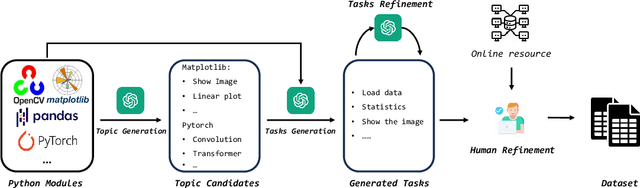

While LLM-Based agents, which use external tools to solve complex problems, have made significant progress, benchmarking their ability is challenging, thereby hindering a clear understanding of their limitations. In this paper, we propose an interactive evaluation framework, named CIBench, to comprehensively assess LLMs' ability to utilize code interpreters for data science tasks. Our evaluation framework includes an evaluation dataset and two evaluation modes. The evaluation dataset is constructed using an LLM-human cooperative approach and simulates an authentic workflow by leveraging consecutive and interactive IPython sessions. The two evaluation modes assess LLMs' ability with and without human assistance. We conduct extensive experiments to analyze the ability of 24 LLMs on CIBench and provide valuable insights for future LLMs in code interpreter utilization.
AlchemistCoder: Harmonizing and Eliciting Code Capability by Hindsight Tuning on Multi-source Data
May 29, 2024Open-source Large Language Models (LLMs) and their specialized variants, particularly Code LLMs, have recently delivered impressive performance. However, previous Code LLMs are typically fine-tuned on single-source data with limited quality and diversity, which may insufficiently elicit the potential of pre-trained Code LLMs. In this paper, we present AlchemistCoder, a series of Code LLMs with enhanced code generation and generalization capabilities fine-tuned on multi-source data. To achieve this, we pioneer to unveil inherent conflicts among the various styles and qualities in multi-source code corpora and introduce data-specific prompts with hindsight relabeling, termed AlchemistPrompts, to harmonize different data sources and instruction-response pairs. Additionally, we propose incorporating the data construction process into the fine-tuning data as code comprehension tasks, including instruction evolution, data filtering, and code review. Extensive experiments demonstrate that AlchemistCoder holds a clear lead among all models of the same size (6.7B/7B) and rivals or even surpasses larger models (15B/33B/70B), showcasing the efficacy of our method in refining instruction-following capabilities and advancing the boundaries of code intelligence.