 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMinor DPO reject penalty to increase training robustness
Aug 22, 2024



Learning from human preference is a paradigm used in large-scale language model (LLM) fine-tuning step to better align pretrained LLM to human preference for downstream task. In the past it uses reinforcement learning from human feedback (RLHF) algorithm to optimize the LLM policy to align with these preferences and not to draft too far from the original model. Recently, Direct Preference Optimization (DPO) has been proposed to solve the alignment problem with a simplified RL-free method. Using preference pairs of chosen and reject data, DPO models the relative log probability as implicit reward function and optimize LLM policy using a simple binary cross entropy objective directly. DPO is quite straight forward and easy to be understood. It perform efficiently and well in most cases. In this article, we analyze the working mechanism of $\beta$ in DPO, disclose its syntax difference between RL algorithm and DPO, and understand the potential shortage brought by the DPO simplification. With these insights, we propose MinorDPO, which is better aligned to the original RL algorithm, and increase the stability of preference optimization process.
CIBench: Evaluating Your LLMs with a Code Interpreter Plugin
Jul 15, 2024

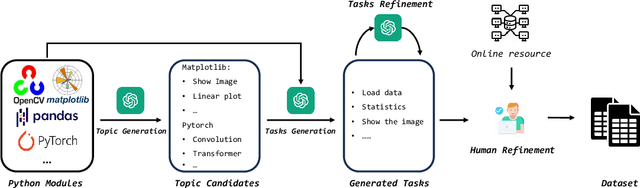

While LLM-Based agents, which use external tools to solve complex problems, have made significant progress, benchmarking their ability is challenging, thereby hindering a clear understanding of their limitations. In this paper, we propose an interactive evaluation framework, named CIBench, to comprehensively assess LLMs' ability to utilize code interpreters for data science tasks. Our evaluation framework includes an evaluation dataset and two evaluation modes. The evaluation dataset is constructed using an LLM-human cooperative approach and simulates an authentic workflow by leveraging consecutive and interactive IPython sessions. The two evaluation modes assess LLMs' ability with and without human assistance. We conduct extensive experiments to analyze the ability of 24 LLMs on CIBench and provide valuable insights for future LLMs in code interpreter utilization.
InternLM2 Technical Report
Mar 26, 2024



The evolution of Large Language Models (LLMs) like ChatGPT and GPT-4 has sparked discussions on the advent of Artificial General Intelligence (AGI). However, replicating such advancements in open-source models has been challenging. This paper introduces InternLM2, an open-source LLM that outperforms its predecessors in comprehensive evaluations across 6 dimensions and 30 benchmarks, long-context modeling, and open-ended subjective evaluations through innovative pre-training and optimization techniques. The pre-training process of InternLM2 is meticulously detailed, highlighting the preparation of diverse data types including text, code, and long-context data. InternLM2 efficiently captures long-term dependencies, initially trained on 4k tokens before advancing to 32k tokens in pre-training and fine-tuning stages, exhibiting remarkable performance on the 200k ``Needle-in-a-Haystack" test. InternLM2 is further aligned using Supervised Fine-Tuning (SFT) and a novel Conditional Online Reinforcement Learning from Human Feedback (COOL RLHF) strategy that addresses conflicting human preferences and reward hacking. By releasing InternLM2 models in different training stages and model sizes, we provide the community with insights into the model's evolution.