 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDual Prototype-Conditioned Diffusion Model for Scalable Multi-Class Unsupervised Anomaly Detection in Large Category Spaces
May 23, 2026Multi-class anomaly detection aims to build unified models across diverse product categories. However, as the number of categories grows, its performance often degrades due to increasingly complex and heterogeneous normal distributions. To address this challenge, we propose DPDiff-AD, a Dual Prototype-conditioned Diffusion model for large-scale multi-class Anomaly Detection. DPDiff-AD models heterogeneous normal distributions through complementary local and global prototypes. Local prototypes capture representative fine-grained structural patterns via nearest-prototype aggregation, while global prototypes regulate holistic feature geometry through optimal transport regularization. Together, these dual-scale representations define a structured normality space. This space is refined through diffusion-based reconstruction conditioned on both local and global prototypes via prototype-aware attention. By jointly leveraging dual prototypes during generation, DPDiff-AD achieves precise normality modeling, preserves structured separability as category cardinality grows, and enables scalable anomaly discrimination. Extensive experiments across five benchmarks demonstrate the effectiveness and scalability of DPDiff-AD. On the 160-category large-scale dataset, it improves image- and pixel-level AUROC by 5.3 and 2.9 points over the previous state-of-the-art method Dinomaly+, while maintaining stable performance as category cardinality increases.
OpenCompass: A Universal Evaluation Platform for Large Language Models
May 19, 2026In recent years, the field of artificial intelligence has undergone a paradigm shift from task-specific small-scale models to general-purpose large language models (LLMs). With the rapid iteration of LLMs, objective, quantitative, and comprehensive evaluation of their capabilities has become a critical link in advancing technological development. Currently, the mainstream static benchmark dataset-based evaluation methods face challenges such as the diversity of task types, inconsistent evaluation criteria, and fragmentation of data and processing workflows, making it difficult to efficiently conduct cross-domain and large-scale model evaluation. To address the aforementioned issues, this paper proposes and open-sources OpenCompass, a one-stop, scalable, and high-concurrency-supported general-purpose LLM evaluation platform. Adhering to the design philosophy of modularization and component decoupling, the platform boasts three core advantages: high compatibility, flexibility, and high concurrency. The core architecture of OpenCompass comprises five key components: the Configuration System, Task Partitioning Module, Execution and Scheduling Module, Task Execution Unit, and Result Visualization Module. Its workflow provides rule-based, LLM-as-a-Judge, and cascaded evaluators to adapt to the requirements of different task scenarios. Supporting mainstream benchmark datasets across multiple domains, including knowledge, reasoning, computation, science, language, code, etc., the platform offers a unified and efficient LLM evaluation tool for both academia and industry, facilitating the accurate identification of strengths and weaknesses of LLMs as well as their subsequent optimization.
Discover Fast Power Allocation Solution for Multi-Target Tracking via AlphaEvolve Evolution
May 03, 2026Efficient radar resource allocation is a fundamental yet computationally challenging problem, as optimal solutions typically require iterative optimization with high complexity. Motivated by the need for real-time scheduling, robust generalization, and low data dependency, this paper proposes a novel paradigm that leverages large language model (LLM)-guided evolutionary search (AlphaEvolve) to autonomously discover a closed-form power allocation solution for multi-target tracking. The approach encodes high-dimensional radar states into physically inspired features, then evolves a compact and interpretable scoring function, which is transformed to feasible power allocations via a deterministic constraint-satisfying transformation. Extensive experiments demonstrate that the discovered closed-form solution achieves near-optimal tracking accuracy (average relative performance loss of only $1.51\%$), reliable generalization across diverse scenarios and target counts, and over three orders of magnitude speedup compared to conventional iterative solvers. These results highlight the potential of LLM-guided symbolic search to revolutionize not only radar resource management but also broader classes of engineering optimization problems.
Intern-S1-Pro: Scientific Multimodal Foundation Model at Trillion Scale
Mar 26, 2026We introduce Intern-S1-Pro, the first one-trillion-parameter scientific multimodal foundation model. Scaling to this unprecedented size, the model delivers a comprehensive enhancement across both general and scientific domains. Beyond stronger reasoning and image-text understanding capabilities, its intelligence is augmented with advanced agent capabilities. Simultaneously, its scientific expertise has been vastly expanded to master over 100 specialized tasks across critical science fields, including chemistry, materials, life sciences, and earth sciences. Achieving this massive scale is made possible by the robust infrastructure support of XTuner and LMDeploy, which facilitates highly efficient Reinforcement Learning (RL) training at the 1-trillion parameter level while ensuring strict precision consistency between training and inference. By seamlessly integrating these advancements, Intern-S1-Pro further fortifies the fusion of general and specialized intelligence, working as a Specializable Generalist, demonstrating its position in the top tier of open-source models for general capabilities, while outperforming proprietary models in the depth of specialized scientific tasks.
SAMoE-VLA: A Scene Adaptive Mixture-of-Experts Vision-Language-Action Model for Autonomous Driving
Mar 09, 2026Recent advances in Vision-Language-Action (VLA) models have shown promising capabilities in autonomous driving by leveraging the understanding and reasoning strengths of Large Language Models(LLMs).However, our empirical analysis reveals that directly applying existing token-level MoE mechanisms--which are inherited from LLM architectures--to VLA models results in unstable performance and safety degradation in autonomous driving, highlighting a misalignment between token-based expert specialization and scene-level decision-making.To address this, we propose SAMoE-VLA, a scene-adaptive Vision-Language-Action framework that conditions expert selection on structured scene representations instead of token embeddings. Our key idea is to derive the MoE routing signal from bird's-eye-view (BEV) features that encapsulates traffic scene context, enabling scenario-dependent expert weighting and merging tailored to distinct driving conditions. Furthermore, to support temporally consistent reasoning across world-knowledge, perception, language, and action, we introduce a Conditional Cross-Modal Causal Attention mechanism that integrates world state, linguistic intent, and action history into a unified causal reasoning process. Extensive experiments on the nuScenes open loop planning dataset and LangAuto closed-loop benchmark demonstrate that SAMoE-VLA achieves state-of-the-art performance, outperforming prior VLA-based and world-model-based approaches with fewer parameters.Our code will be released soon.
Root Cause Analysis Method Based on Large Language Models with Residual Connection Structures
Feb 09, 2026Root cause localization remain challenging in complex and large-scale microservice architectures. The complex fault propagation among microservices and the high dimensionality of telemetry data, including metrics, logs, and traces, limit the effectiveness of existing root cause analysis (RCA) methods. In this paper, a residual-connection-based RCA method using large language model (LLM), named RC-LLM, is proposed. A residual-like hierarchical fusion structure is designed to integrate multi-source telemetry data, while the contextual reasoning capability of large language models is leveraged to model temporal and cross-microservice causal dependencies. Experimental results on CCF-AIOps microservice datasets demonstrate that RC-LLM achieves strong accuracy and efficiency in root cause analysis.
ATLAS: A High-Difficulty, Multidisciplinary Benchmark for Frontier Scientific Reasoning
Nov 18, 2025The rapid advancement of Large Language Models (LLMs) has led to performance saturation on many established benchmarks, questioning their ability to distinguish frontier models. Concurrently, existing high-difficulty benchmarks often suffer from narrow disciplinary focus, oversimplified answer formats, and vulnerability to data contamination, creating a fidelity gap with real-world scientific inquiry. To address these challenges, we introduce ATLAS (AGI-Oriented Testbed for Logical Application in Science), a large-scale, high-difficulty, and cross-disciplinary evaluation suite composed of approximately 800 original problems. Developed by domain experts (PhD-level and above), ATLAS spans seven core scientific fields: mathematics, physics, chemistry, biology, computer science, earth science, and materials science. Its key features include: (1) High Originality and Contamination Resistance, with all questions newly created or substantially adapted to prevent test data leakage; (2) Cross-Disciplinary Focus, designed to assess models' ability to integrate knowledge and reason across scientific domains; (3) High-Fidelity Answers, prioritizing complex, open-ended answers involving multi-step reasoning and LaTeX-formatted expressions over simple multiple-choice questions; and (4) Rigorous Quality Control, employing a multi-stage process of expert peer review and adversarial testing to ensure question difficulty, scientific value, and correctness. We also propose a robust evaluation paradigm using a panel of LLM judges for automated, nuanced assessment of complex answers. Preliminary results on leading models demonstrate ATLAS's effectiveness in differentiating their advanced scientific reasoning capabilities. We plan to develop ATLAS into a long-term, open, community-driven platform to provide a reliable "ruler" for progress toward Artificial General Intelligence.
A Multi-Level Framework for Multi-Objective Hypergraph Partitioning: Combining Minimum Spanning Tree and Proximal Gradient
Sep 26, 2025
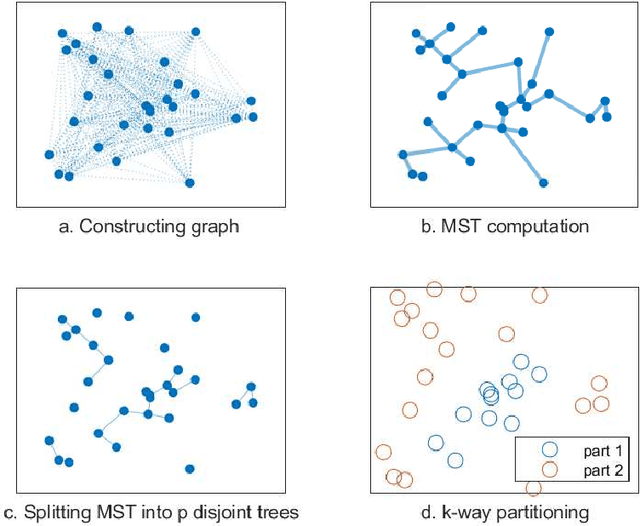

This paper proposes an efficient hypergraph partitioning framework based on a novel multi-objective non-convex constrained relaxation model. A modified accelerated proximal gradient algorithm is employed to generate diverse $k$-dimensional vertex features to avoid local optima and enhance partition quality. Two MST-based strategies are designed for different data scales: for small-scale data, the Prim algorithm constructs a minimum spanning tree followed by pruning and clustering; for large-scale data, a subset of representative nodes is selected to build a smaller MST, while the remaining nodes are assigned accordingly to reduce complexity. To further improve partitioning results, refinement strategies including greedy migration, swapping, and recursive MST-based clustering are introduced for partitions. Experimental results on public benchmark sets demonstrate that the proposed algorithm achieves reductions in cut size of approximately 2\%--5\% on average compared to KaHyPar in 2, 3, and 4-way partitioning, with improvements of up to 35\% on specific instances. Particularly on weighted vertex sets, our algorithm outperforms state-of-the-art partitioners including KaHyPar, hMetis, Mt-KaHyPar, and K-SpecPart, highlighting its superior partitioning quality and competitiveness. Furthermore, the proposed refinement strategy improves hMetis partitions by up to 16\%. A comprehensive evaluation based on virtual instance methodology and parameter sensitivity analysis validates the algorithm's competitiveness and characterizes its performance trade-offs.
GLM-4.5: Agentic, Reasoning, and Coding (ARC) Foundation Models
Aug 08, 2025We present GLM-4.5, an open-source Mixture-of-Experts (MoE) large language model with 355B total parameters and 32B activated parameters, featuring a hybrid reasoning method that supports both thinking and direct response modes. Through multi-stage training on 23T tokens and comprehensive post-training with expert model iteration and reinforcement learning, GLM-4.5 achieves strong performance across agentic, reasoning, and coding (ARC) tasks, scoring 70.1% on TAU-Bench, 91.0% on AIME 24, and 64.2% on SWE-bench Verified. With much fewer parameters than several competitors, GLM-4.5 ranks 3rd overall among all evaluated models and 2nd on agentic benchmarks. We release both GLM-4.5 (355B parameters) and a compact version, GLM-4.5-Air (106B parameters), to advance research in reasoning and agentic AI systems. Code, models, and more information are available at https://github.com/zai-org/GLM-4.5.
Deciphering Trajectory-Aided LLM Reasoning: An Optimization Perspective
May 26, 2025We propose a novel framework for comprehending the reasoning capabilities of large language models (LLMs) through the perspective of meta-learning. By conceptualizing reasoning trajectories as pseudo-gradient descent updates to the LLM's parameters, we identify parallels between LLM reasoning and various meta-learning paradigms. We formalize the training process for reasoning tasks as a meta-learning setup, with each question treated as an individual task, and reasoning trajectories serving as the inner loop optimization for adapting model parameters. Once trained on a diverse set of questions, the LLM develops fundamental reasoning capabilities that can generalize to previously unseen questions. Extensive empirical evaluations substantiate the strong connection between LLM reasoning and meta-learning, exploring several issues of significant interest from a meta-learning standpoint. Our work not only enhances the understanding of LLM reasoning but also provides practical insights for improving these models through established meta-learning techniques.