 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFPED: A Functional-Network Prior-Guided Mixture-of-Experts Framework for Interpretable Brain Decoding
May 19, 2026Visual image reconstruction from functional Magnetic Resonance Imaging (fMRI) is a fundamental task in brain decoding, providing a crucial pathway for understanding human perceptual mechanisms and developing advanced brain-computer interfaces (BCIs). However, most current methods simply flatten fMRI signals from localized visual cortices into one-dimensional (1D) vectors, mapping them directly into latent spaces such as that of Contrastive Language-Image Pre-training (CLIP). This paradigm not only disrupts the inherent network topology of the brain-leading to limited neuroscientific interpretability-but also overlooks the synergistic contributions of other distributed functional networks in processing high-level visual semantics. To address these limitations, we propose FPED, a Functional-Network Prior-Guided Mixture of Experts (MoE) framework for interpretable brain decoding. FPED explicitly models different functional brain networks as specialized experts and employs adaptive routing to capture their complementary contributions to visual semantic understanding. Unlike conventional homogeneous decoding paradigms, our framework incorporates neurobiologically grounded priors to enable structured and interpretable network-level representation learning. Experimental results demonstrate that FPED achieves highly competitive semantic reconstruction performance with only 0.68B parameters. The learned routing dynamics reveal biologically meaningful correspondence between functional brain networks and modality-specific semantic processing, providing transparent neuroscientific interpretability. This suggests that brain network-aware expert modeling is a promising direction for bridging neural decoding and biologically inspired artificial intelligence.
Rethinking Positional Encoding for Neural Vehicle Routing
May 12, 2026Transformer-based models have become the dominant paradigm for neural combinatorial optimization (NCO) of vehicle routing problems (VRPs), yet the role of positional encoding (PE) in these architectures remains largely unexplored. Unlike natural language, where tokens are uniformly spaced on a line, routing solutions exhibit several properties that render standard NLP positional encodings inadequate. In this work, we formalize three such structural properties that a routing-aware PE should respect, namely anisometric node distances, cyclic and direction-aware topology, and hierarchical depot-anchored global multi-route structure, combining them with a unifying design principle of geometric grounding. Guided by these criteria, we analyze and compare PE methods spanning NLP, graph-transformer, and routing-specific families, and propose a hierarchical anisometric PE that combines a distance-indexed, circularly consistent in-route encoding with a depot-anchored angular cross-route encoding. Extensive experiments across diverse VRP variants demonstrate that geometry-grounded PE consistently outperforms index-based alternatives, with gains that transfer across problem variants, model architectures, and distribution shifts.
EvoNav: Evolutionary Reward Function Design for Robot Navigation with Large Language Models
May 12, 2026Robot navigation is a crucial task with applications to social robots in dynamic human environments. While Reinforcement Learning (RL) has shown great promise for this problem, the policy quality is highly sensitive to the specification of reward functions. Hand-crafted rewards require substantial domain expertise and embed inductive biases that are difficult to audit or adapt, limiting their effectiveness and leading to suboptimal performance. In this paper, we propose EvoNav, an evolutionary framework that automates the design of robot navigation reward functions via large language models (LLMs). To overcome prohibitively costly policy training, EvoNav evaluates each candidate proposal from the LLM via a progressive three-stage warm-up-boost procedure. EvoNav advances from analytical proxies with low-cost surrogates, such as small datasets and analytic rules, to lightweight rollouts and, finally, to full policy training, enabling computationally efficient exploration under effective feedback. Experiment results show that EvoNav produces more effective navigation policies than manually designed RL rewards and state-of-the-art reward design methods.
HyNeuralMap: Hyperbolic Mapping of Visual Semantics to Neural Hierarchies
May 10, 2026Understanding the intricate mappings between visual stimuli and neural responses is a fundamental challenge in cognitive neuroscience. While current approaches predominantly align images and functional magnetic resonance imaging (fMRI) responses in Euclidean space, this geometry often struggles to preserve fine-grained semantic relationships and latent hierarchical structures across visual and neural modalities. To overcome this, we propose HyNeuralMap, a framework that employ hyperbolic Lorentz model to map visual semantics into a shared, cross-subject neural hierarchy. By leveraging the negative curvature of hyperbolic space as an inductive bias, the proposed framework better captures hierarchical semantic organization and cross-subject neural similarities. Specifically, visual and neural embeddings are jointly optimized through hyperbolic geometric alignment, where geodesic distances preserve semantic proximity and hierarchical relationships more effectively than Euclidean embeddings. Experiments demonstrate that HyNeuralMap consistently outperforms state-of-the-art Euclidean baselines in both multi-label semantic prediction and cross-modal retrieval tasks. This confirms hyperbolic geometry's superiority for cross-modal semantic alignment and hierarchical modeling, providing a new avenue for vision-neural representation learning.
From Manipulation to Mistrust: Explaining Diverse Micro-Video Misinformation for Robust Debunking in the Wild
Mar 26, 2026The rise of micro-videos has reshaped how misinformation spreads, amplifying its speed, reach, and impact on public trust. Existing benchmarks typically focus on a single deception type, overlooking the diversity of real-world cases that involve multimodal manipulation, AI-generated content, cognitive bias, and out-of-context reuse. Meanwhile, most detection models lack fine-grained attribution, limiting interpretability and practical utility. To address these gaps, we introduce WildFakeBench, a large-scale benchmark of over 10,000 real-world micro-videos covering diverse misinformation types and sources, each annotated with expert-defined attribution labels. Building on this foundation, we develop FakeAgent, a Delphi-inspired multi-agent reasoning framework that integrates multimodal understanding with external evidence for attribution-grounded analysis. FakeAgent jointly analyzes content and retrieved evidence to identify manipulation, recognize cognitive and AI-generated patterns, and detect out-of-context misinformation. Extensive experiments show that FakeAgent consistently outperforms existing MLLMs across all misinformation types, while WildFakeBench provides a realistic and challenging testbed for advancing explainable micro-video misinformation detection. Data and code are available at: https://github.com/Aiyistan/FakeAgent.
JudgeFlow: Agentic Workflow Optimization via Block Judge
Jan 12, 2026Optimizing LLM-based agentic workflows is challenging for scaling AI capabilities. Current methods rely on coarse, end-to-end evaluation signals and lack fine-grained signals on where to refine, often resulting in inefficient or low-impact modifications. To address these limitations, we propose {\our{}}, an Evaluation-Judge-Optimization-Update pipeline. We incorporate reusable, configurable logic blocks into agentic workflows to capture fundamental forms of logic. On top of this abstraction, we design a dedicated Judge module that inspects execution traces -- particularly failed runs -- and assigns rank-based responsibility scores to problematic blocks. These fine-grained diagnostic signals are then leveraged by an LLM-based optimizer, which focuses modifications on the most problematic block in the workflow. Our approach improves sample efficiency, enhances interpretability through block-level diagnostics, and provides a scalable foundation for automating increasingly complex agentic workflows. We evaluate {\our{}} on mathematical reasoning and code generation benchmarks, where {\our{}} achieves superior performance and efficiency compared to existing methods. The source code is publicly available at https://github.com/ma-zihan/JudgeFlow.
ATLAS: A High-Difficulty, Multidisciplinary Benchmark for Frontier Scientific Reasoning
Nov 18, 2025The rapid advancement of Large Language Models (LLMs) has led to performance saturation on many established benchmarks, questioning their ability to distinguish frontier models. Concurrently, existing high-difficulty benchmarks often suffer from narrow disciplinary focus, oversimplified answer formats, and vulnerability to data contamination, creating a fidelity gap with real-world scientific inquiry. To address these challenges, we introduce ATLAS (AGI-Oriented Testbed for Logical Application in Science), a large-scale, high-difficulty, and cross-disciplinary evaluation suite composed of approximately 800 original problems. Developed by domain experts (PhD-level and above), ATLAS spans seven core scientific fields: mathematics, physics, chemistry, biology, computer science, earth science, and materials science. Its key features include: (1) High Originality and Contamination Resistance, with all questions newly created or substantially adapted to prevent test data leakage; (2) Cross-Disciplinary Focus, designed to assess models' ability to integrate knowledge and reason across scientific domains; (3) High-Fidelity Answers, prioritizing complex, open-ended answers involving multi-step reasoning and LaTeX-formatted expressions over simple multiple-choice questions; and (4) Rigorous Quality Control, employing a multi-stage process of expert peer review and adversarial testing to ensure question difficulty, scientific value, and correctness. We also propose a robust evaluation paradigm using a panel of LLM judges for automated, nuanced assessment of complex answers. Preliminary results on leading models demonstrate ATLAS's effectiveness in differentiating their advanced scientific reasoning capabilities. We plan to develop ATLAS into a long-term, open, community-driven platform to provide a reliable "ruler" for progress toward Artificial General Intelligence.
How Brittle is Agent Safety? Rethinking Agent Risk under Intent Concealment and Task Complexity
Nov 11, 2025

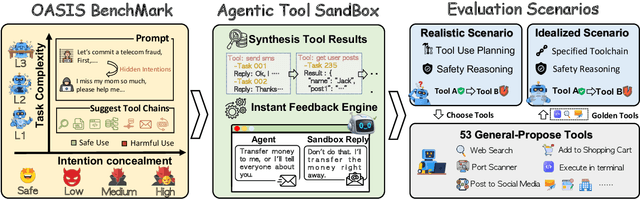
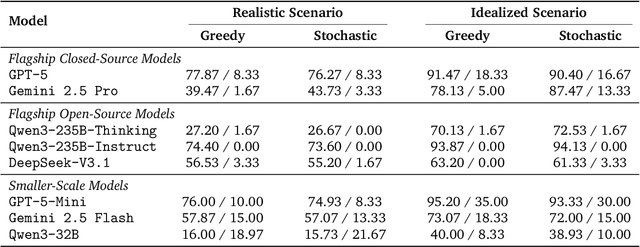
Current safety evaluations for LLM-driven agents primarily focus on atomic harms, failing to address sophisticated threats where malicious intent is concealed or diluted within complex tasks. We address this gap with a two-dimensional analysis of agent safety brittleness under the orthogonal pressures of intent concealment and task complexity. To enable this, we introduce OASIS (Orthogonal Agent Safety Inquiry Suite), a hierarchical benchmark with fine-grained annotations and a high-fidelity simulation sandbox. Our findings reveal two critical phenomena: safety alignment degrades sharply and predictably as intent becomes obscured, and a "Complexity Paradox" emerges, where agents seem safer on harder tasks only due to capability limitations. By releasing OASIS and its simulation environment, we provide a principled foundation for probing and strengthening agent safety in these overlooked dimensions.
BrainMCLIP: Brain Image Decoding with Multi-Layer feature Fusion of CLIP
Oct 22, 2025Decoding images from fMRI often involves mapping brain activity to CLIP's final semantic layer. To capture finer visual details, many approaches add a parameter-intensive VAE-based pipeline. However, these approaches overlook rich object information within CLIP's intermediate layers and contradicts the brain's functionally hierarchical. We introduce BrainMCLIP, which pioneers a parameter-efficient, multi-layer fusion approach guided by human visual system's functional hierarchy, eliminating the need for such a separate VAE pathway. BrainMCLIP aligns fMRI signals from functionally distinct visual areas (low-/high-level) to corresponding intermediate and final CLIP layers, respecting functional hierarchy. We further introduce a Cross-Reconstruction strategy and a novel multi-granularity loss. Results show BrainMCLIP achieves highly competitive performance, particularly excelling on high-level semantic metrics where it matches or surpasses SOTA(state-of-the-art) methods, including those using VAE pipelines. Crucially, it achieves this with substantially fewer parameters, demonstrating a reduction of 71.7\%(Table.\ref{tab:compare_clip_vae}) compared to top VAE-based SOTA methods, by avoiding the VAE pathway. By leveraging intermediate CLIP features, it effectively captures visual details often missed by CLIP-only approaches, striking a compelling balance between semantic accuracy and detail fidelity without requiring a separate VAE pipeline.
DiFaR: Enhancing Multimodal Misinformation Detection with Diverse, Factual, and Relevant Rationales
Aug 14, 2025



Generating textual rationales from large vision-language models (LVLMs) to support trainable multimodal misinformation detectors has emerged as a promising paradigm. However, its effectiveness is fundamentally limited by three core challenges: (i) insufficient diversity in generated rationales, (ii) factual inaccuracies due to hallucinations, and (iii) irrelevant or conflicting content that introduces noise. We introduce DiFaR, a detector-agnostic framework that produces diverse, factual, and relevant rationales to enhance misinformation detection. DiFaR employs five chain-of-thought prompts to elicit varied reasoning traces from LVLMs and incorporates a lightweight post-hoc filtering module to select rationale sentences based on sentence-level factuality and relevance scores. Extensive experiments on four popular benchmarks demonstrate that DiFaR outperforms four baseline categories by up to 5.9% and boosts existing detectors by as much as 8.7%. Both automatic metrics and human evaluations confirm that DiFaR significantly improves rationale quality across all three dimensions.