 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTWIN-GPT: Digital Twins for Clinical Trials via Large Language Model
Paper and Code
Apr 01, 2024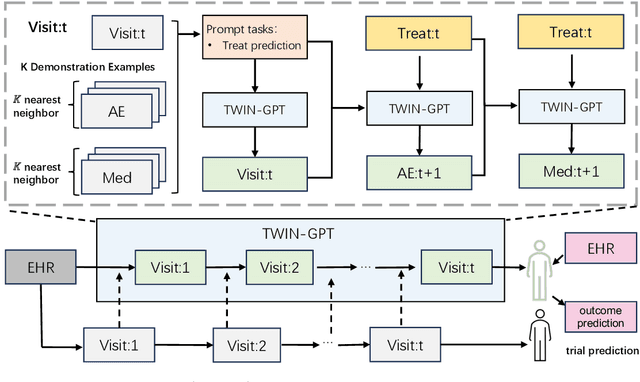


Recently, there has been a burgeoning interest in virtual clinical trials, which simulate real-world scenarios and hold the potential to significantly enhance patient safety, expedite development, reduce costs, and contribute to the broader scientific knowledge in healthcare. Existing research often focuses on leveraging electronic health records (EHRs) to support clinical trial outcome prediction. Yet, trained with limited clinical trial outcome data, existing approaches frequently struggle to perform accurate predictions. Some research has attempted to generate EHRs to augment model development but has fallen short in personalizing the generation for individual patient profiles. Recently, the emergence of large language models has illuminated new possibilities, as their embedded comprehensive clinical knowledge has proven beneficial in addressing medical issues. In this paper, we propose a large language model-based digital twin creation approach, called TWIN-GPT. TWIN-GPT can establish cross-dataset associations of medical information given limited data, generating unique personalized digital twins for different patients, thereby preserving individual patient characteristics. Comprehensive experiments show that using digital twins created by TWIN-GPT can boost clinical trial outcome prediction, exceeding various previous prediction approaches. Besides, we also demonstrate that TWIN-GPT can generate high-fidelity trial data that closely approximate specific patients, aiding in more accurate result predictions in data-scarce situations. Moreover, our study provides practical evidence for the application of digital twins in healthcare, highlighting its potential significance.