 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHumanOrbit: 3D Human Reconstruction as 360° Orbit Generation
Feb 27, 2026We present a method for generating a full 360° orbit video around a person from a single input image. Existing methods typically adapt image-based diffusion models for multi-view synthesis, but yield inconsistent results across views and with the original identity. In contrast, recent video diffusion models have demonstrated their ability in generating photorealistic results that align well with the given prompts. Inspired by these results, we propose HumanOrbit, a video diffusion model for multi-view human image generation. Our approach enables the model to synthesize continuous camera rotations around the subject, producing geometrically consistent novel views while preserving the appearance and identity of the person. Using the generated multi-view frames, we further propose a reconstruction pipeline that recovers a textured mesh of the subject. Experimental results validate the effectiveness of HumanOrbit for multi-view image generation and that the reconstructed 3D models exhibit superior completeness and fidelity compared to those from state-of-the-art baselines.
AirHunt: Bridging VLM Semantics and Continuous Planning for Efficient Aerial Object Navigation
Jan 19, 2026Recent advances in large Vision-Language Models (VLMs) have provided rich semantic understanding that empowers drones to search for open-set objects via natural language instructions. However, prior systems struggle to integrate VLMs into practical aerial systems due to orders-of-magnitude frequency mismatch between VLM inference and real-time planning, as well as VLMs' limited 3D scene understanding. They also lack a unified mechanism to balance semantic guidance with motion efficiency in large-scale environments. To address these challenges, we present AirHunt, an aerial object navigation system that efficiently locates open-set objects with zero-shot generalization in outdoor environments by seamlessly fusing VLM semantic reasoning with continuous path planning. AirHunt features a dual-pathway asynchronous architecture that establishes a synergistic interface between VLM reasoning and path planning, enabling continuous flight with adaptive semantic guidance that evolves through motion. Moreover, we propose an active dual-task reasoning module that exploits geometric and semantic redundancy to enable selective VLM querying, and a semantic-geometric coherent planning module that dynamically reconciles semantic priorities and motion efficiency in a unified framework, enabling seamless adaptation to environmental heterogeneity. We evaluate AirHunt across diverse object navigation tasks and environments, demonstrating a higher success rate with lower navigation error and reduced flight time compared to state-of-the-art methods. Real-world experiments further validate AirHunt's practical capability in complex and challenging environments. Code and dataset will be made publicly available before publication.
DynaGSLAM: Real-Time Gaussian-Splatting SLAM for Online Rendering, Tracking, Motion Predictions of Moving Objects in Dynamic Scenes
Mar 15, 2025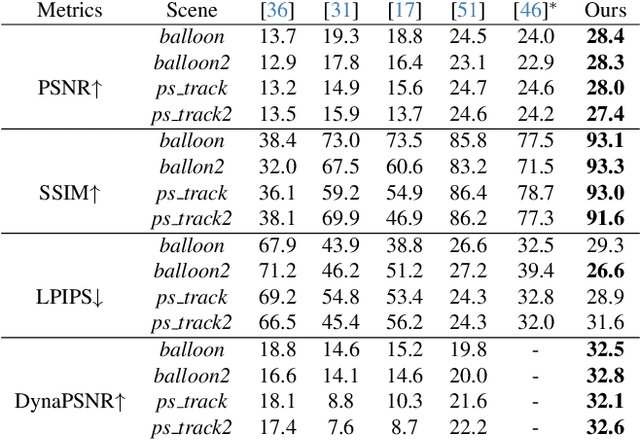

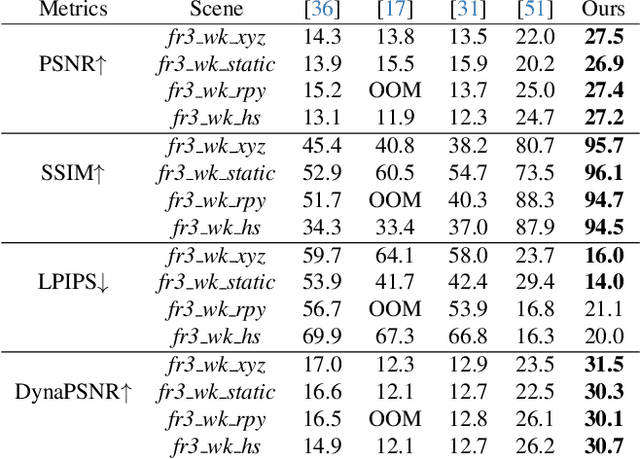
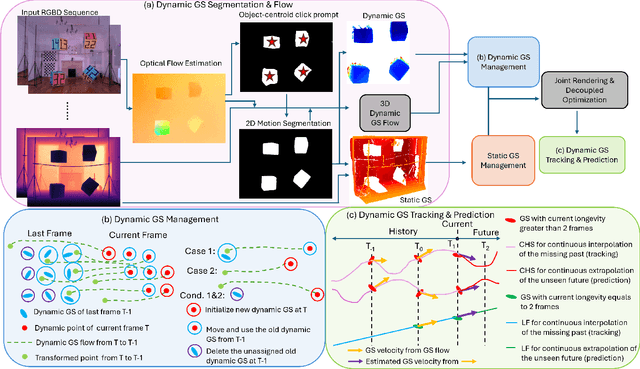
Simultaneous Localization and Mapping (SLAM) is one of the most important environment-perception and navigation algorithms for computer vision, robotics, and autonomous cars/drones. Hence, high quality and fast mapping becomes a fundamental problem. With the advent of 3D Gaussian Splatting (3DGS) as an explicit representation with excellent rendering quality and speed, state-of-the-art (SOTA) works introduce GS to SLAM. Compared to classical pointcloud-SLAM, GS-SLAM generates photometric information by learning from input camera views and synthesize unseen views with high-quality textures. However, these GS-SLAM fail when moving objects occupy the scene that violate the static assumption of bundle adjustment. The failed updates of moving GS affects the static GS and contaminates the full map over long frames. Although some efforts have been made by concurrent works to consider moving objects for GS-SLAM, they simply detect and remove the moving regions from GS rendering ("anti'' dynamic GS-SLAM), where only the static background could benefit from GS. To this end, we propose the first real-time GS-SLAM, "DynaGSLAM'', that achieves high-quality online GS rendering, tracking, motion predictions of moving objects in dynamic scenes while jointly estimating accurate ego motion. Our DynaGSLAM outperforms SOTA static & "Anti'' dynamic GS-SLAM on three dynamic real datasets, while keeping speed and memory efficiency in practice.
Open-Vocabulary Semantic Part Segmentation of 3D Human
Feb 27, 20253D part segmentation is still an open problem in the field of 3D vision and AR/VR. Due to limited 3D labeled data, traditional supervised segmentation methods fall short in generalizing to unseen shapes and categories. Recently, the advancement in vision-language models' zero-shot abilities has brought a surge in open-world 3D segmentation methods. While these methods show promising results for 3D scenes or objects, they do not generalize well to 3D humans. In this paper, we present the first open-vocabulary segmentation method capable of handling 3D human. Our framework can segment the human category into desired fine-grained parts based on the textual prompt. We design a simple segmentation pipeline, leveraging SAM to generate multi-view proposals in 2D and proposing a novel HumanCLIP model to create unified embeddings for visual and textual inputs. Compared with existing pre-trained CLIP models, the HumanCLIP model yields more accurate embeddings for human-centric contents. We also design a simple-yet-effective MaskFusion module, which classifies and fuses multi-view features into 3D semantic masks without complex voting and grouping mechanisms. The design of decoupling mask proposals and text input also significantly boosts the efficiency of per-prompt inference. Experimental results on various 3D human datasets show that our method outperforms current state-of-the-art open-vocabulary 3D segmentation methods by a large margin. In addition, we show that our method can be directly applied to various 3D representations including meshes, point clouds, and 3D Gaussian Splatting.
GlossGau: Efficient Inverse Rendering for Glossy Surface with Anisotropic Spherical Gaussian
Feb 19, 2025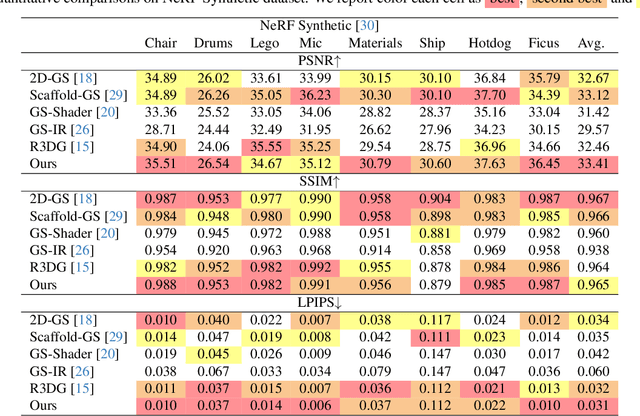
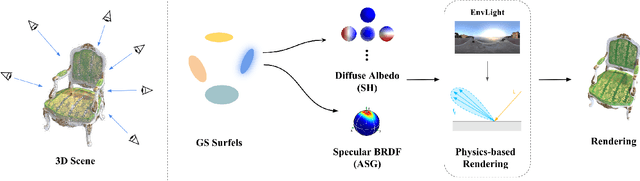
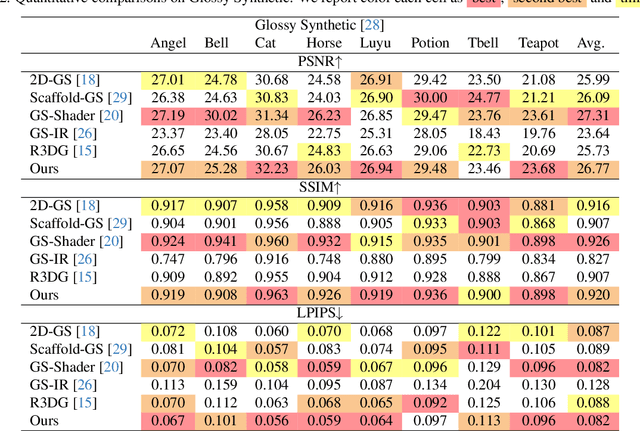

The reconstruction of 3D objects from calibrated photographs represents a fundamental yet intricate challenge in the domains of computer graphics and vision. Although neural reconstruction approaches based on Neural Radiance Fields (NeRF) have shown remarkable capabilities, their processing costs remain substantial. Recently, the advent of 3D Gaussian Splatting (3D-GS) largely improves the training efficiency and facilitates to generate realistic rendering in real-time. However, due to the limited ability of Spherical Harmonics (SH) to represent high-frequency information, 3D-GS falls short in reconstructing glossy objects. Researchers have turned to enhance the specular expressiveness of 3D-GS through inverse rendering. Yet these methods often struggle to maintain the training and rendering efficiency, undermining the benefits of Gaussian Splatting techniques. In this paper, we introduce GlossGau, an efficient inverse rendering framework that reconstructs scenes with glossy surfaces while maintaining training and rendering speeds comparable to vanilla 3D-GS. Specifically, we explicitly model the surface normals, Bidirectional Reflectance Distribution Function (BRDF) parameters, as well as incident lights and use Anisotropic Spherical Gaussian (ASG) to approximate the per-Gaussian Normal Distribution Function under the microfacet model. We utilize 2D Gaussian Splatting (2D-GS) as foundational primitives and apply regularization to significantly alleviate the normal estimation challenge encountered in related works. Experiments demonstrate that GlossGau achieves competitive or superior reconstruction on datasets with glossy surfaces. Compared with previous GS-based works that address the specular surface, our optimization time is considerably less.
Generation of Drug-Induced Cardiac Reactions towards Virtual Clinical Trials
Feb 11, 2025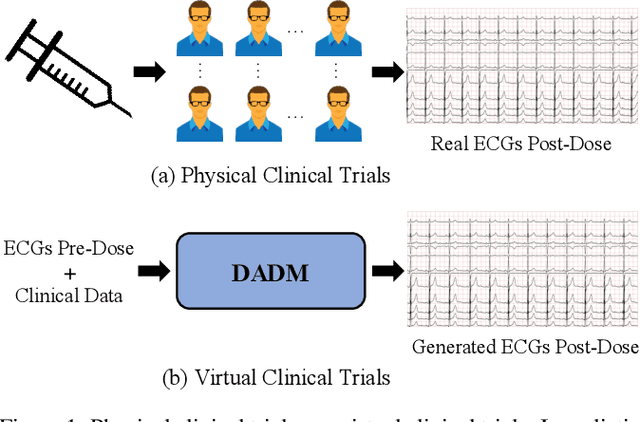
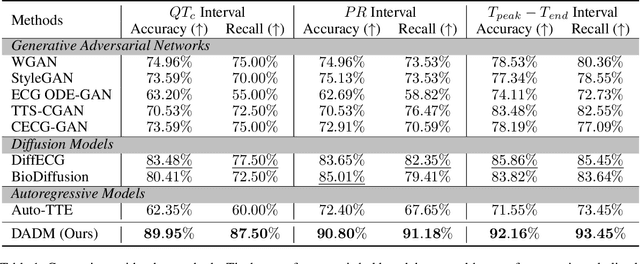
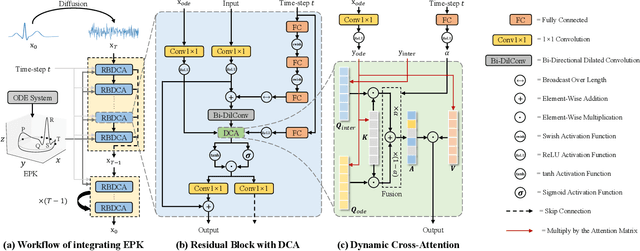
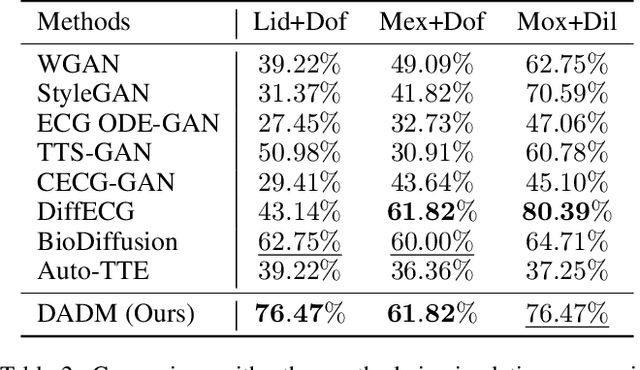
Clinical trials are pivotal in cardiac drug development, yet they often fail due to inadequate efficacy and unexpected safety issues, leading to significant financial losses. Using in-silico trials to replace a part of physical clinical trials, e.g., leveraging advanced generative models to generate drug-influenced electrocardiograms (ECGs), seems an effective method to reduce financial risk and potential harm to trial participants. While existing generative models have demonstrated progress in ECG generation, they fall short in modeling drug reactions due to limited fidelity and inability to capture individualized drug response patterns. In this paper, we propose a Drug-Aware Diffusion Model (DADM), which could simulate individualized drug reactions while ensuring fidelity. To ensure fidelity, we construct a set of ordinary differential equations to provide external physical knowledge (EPK) of the realistic ECG morphology. The EPK is used to adaptively constrain the morphology of the generated ECGs through a dynamic cross-attention (DCA) mechanism. Furthermore, we propose an extension of ControlNet to incorporate demographic and drug data, simulating individual drug reactions. We compare DADM with the other eight state-of-the-art ECG generative models on two real-world databases covering 8 types of drug regimens. The results demonstrate that DADM can more accurately simulate drug-induced changes in ECGs, improving the accuracy by at least 5.79% and recall by 8%.
Take Your Steps: Hierarchically Efficient Pulmonary Disease Screening via CT Volume Compression
Dec 03, 2024Deep learning models are widely used to process Computed Tomography (CT) data in the automated screening of pulmonary diseases, significantly reducing the workload of physicians. However, the three-dimensional nature of CT volumes involves an excessive number of voxels, which significantly increases the complexity of model processing. Previous screening approaches often overlook this issue, which undoubtedly reduces screening efficiency. Towards efficient and effective screening, we design a hierarchical approach to reduce the computational cost of pulmonary disease screening. The new approach re-organizes the screening workflows into three steps. First, we propose a Computed Tomography Volume Compression (CTVC) method to select a small slice subset that comprehensively represents the whole CT volume. Second, the selected CT slices are used to detect pulmonary diseases coarsely via a lightweight classification model. Third, an uncertainty measurement strategy is applied to identify samples with low diagnostic confidence, which are re-detected by radiologists. Experiments on two public pulmonary disease datasets demonstrate that our approach achieves comparable accuracy and recall while reducing the time by 50%-70% compared with the counterparts using full CT volumes. Besides, we also found that our approach outperforms previous cutting-edge CTVC methods in retaining important indications after compression.
SplatSDF: Boosting Neural Implicit SDF via Gaussian Splatting Fusion
Nov 23, 2024



A signed distance function (SDF) is a useful representation for continuous-space geometry and many related operations, including rendering, collision checking, and mesh generation. Hence, reconstructing SDF from image observations accurately and efficiently is a fundamental problem. Recently, neural implicit SDF (SDF-NeRF) techniques, trained using volumetric rendering, have gained a lot of attention. Compared to earlier truncated SDF (TSDF) fusion algorithms that rely on depth maps and voxelize continuous space, SDF-NeRF enables continuous-space SDF reconstruction with better geometric and photometric accuracy. However, the accuracy and convergence speed of scene-level SDF reconstruction require further improvements for many applications. With the advent of 3D Gaussian Splatting (3DGS) as an explicit representation with excellent rendering quality and speed, several works have focused on improving SDF-NeRF by introducing consistency losses on depth and surface normals between 3DGS and SDF-NeRF. However, loss-level connections alone lead to incremental improvements. We propose a novel neural implicit SDF called "SplatSDF" to fuse 3DGSandSDF-NeRF at an architecture level with significant boosts to geometric and photometric accuracy and convergence speed. Our SplatSDF relies on 3DGS as input only during training, and keeps the same complexity and efficiency as the original SDF-NeRF during inference. Our method outperforms state-of-the-art SDF-NeRF models on geometric and photometric evaluation by the time of submission.
TWIN-GPT: Digital Twins for Clinical Trials via Large Language Model
Apr 01, 2024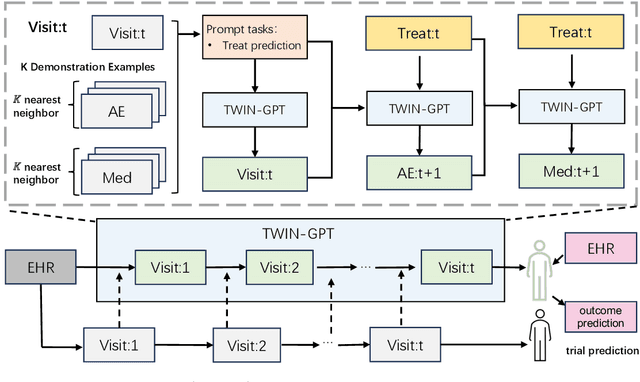


Recently, there has been a burgeoning interest in virtual clinical trials, which simulate real-world scenarios and hold the potential to significantly enhance patient safety, expedite development, reduce costs, and contribute to the broader scientific knowledge in healthcare. Existing research often focuses on leveraging electronic health records (EHRs) to support clinical trial outcome prediction. Yet, trained with limited clinical trial outcome data, existing approaches frequently struggle to perform accurate predictions. Some research has attempted to generate EHRs to augment model development but has fallen short in personalizing the generation for individual patient profiles. Recently, the emergence of large language models has illuminated new possibilities, as their embedded comprehensive clinical knowledge has proven beneficial in addressing medical issues. In this paper, we propose a large language model-based digital twin creation approach, called TWIN-GPT. TWIN-GPT can establish cross-dataset associations of medical information given limited data, generating unique personalized digital twins for different patients, thereby preserving individual patient characteristics. Comprehensive experiments show that using digital twins created by TWIN-GPT can boost clinical trial outcome prediction, exceeding various previous prediction approaches. Besides, we also demonstrate that TWIN-GPT can generate high-fidelity trial data that closely approximate specific patients, aiding in more accurate result predictions in data-scarce situations. Moreover, our study provides practical evidence for the application of digital twins in healthcare, highlighting its potential significance.
Deep Rib Fracture Instance Segmentation and Classification from CT on the RibFrac Challenge
Feb 14, 2024Rib fractures are a common and potentially severe injury that can be challenging and labor-intensive to detect in CT scans. While there have been efforts to address this field, the lack of large-scale annotated datasets and evaluation benchmarks has hindered the development and validation of deep learning algorithms. To address this issue, the RibFrac Challenge was introduced, providing a benchmark dataset of over 5,000 rib fractures from 660 CT scans, with voxel-level instance mask annotations and diagnosis labels for four clinical categories (buckle, nondisplaced, displaced, or segmental). The challenge includes two tracks: a detection (instance segmentation) track evaluated by an FROC-style metric and a classification track evaluated by an F1-style metric. During the MICCAI 2020 challenge period, 243 results were evaluated, and seven teams were invited to participate in the challenge summary. The analysis revealed that several top rib fracture detection solutions achieved performance comparable or even better than human experts. Nevertheless, the current rib fracture classification solutions are hardly clinically applicable, which can be an interesting area in the future. As an active benchmark and research resource, the data and online evaluation of the RibFrac Challenge are available at the challenge website. As an independent contribution, we have also extended our previous internal baseline by incorporating recent advancements in large-scale pretrained networks and point-based rib segmentation techniques. The resulting FracNet+ demonstrates competitive performance in rib fracture detection, which lays a foundation for further research and development in AI-assisted rib fracture detection and diagnosis.