 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDropletVideo: A Dataset and Approach to Explore Integral Spatio-Temporal Consistent Video Generation
Mar 08, 2025Spatio-temporal consistency is a critical research topic in video generation. A qualified generated video segment must ensure plot plausibility and coherence while maintaining visual consistency of objects and scenes across varying viewpoints. Prior research, especially in open-source projects, primarily focuses on either temporal or spatial consistency, or their basic combination, such as appending a description of a camera movement after a prompt without constraining the outcomes of this movement. However, camera movement may introduce new objects to the scene or eliminate existing ones, thereby overlaying and affecting the preceding narrative. Especially in videos with numerous camera movements, the interplay between multiple plots becomes increasingly complex. This paper introduces and examines integral spatio-temporal consistency, considering the synergy between plot progression and camera techniques, and the long-term impact of prior content on subsequent generation. Our research encompasses dataset construction through to the development of the model. Initially, we constructed a DropletVideo-10M dataset, which comprises 10 million videos featuring dynamic camera motion and object actions. Each video is annotated with an average caption of 206 words, detailing various camera movements and plot developments. Following this, we developed and trained the DropletVideo model, which excels in preserving spatio-temporal coherence during video generation. The DropletVideo dataset and model are accessible at https://dropletx.github.io.
Deep Rib Fracture Instance Segmentation and Classification from CT on the RibFrac Challenge
Feb 14, 2024Rib fractures are a common and potentially severe injury that can be challenging and labor-intensive to detect in CT scans. While there have been efforts to address this field, the lack of large-scale annotated datasets and evaluation benchmarks has hindered the development and validation of deep learning algorithms. To address this issue, the RibFrac Challenge was introduced, providing a benchmark dataset of over 5,000 rib fractures from 660 CT scans, with voxel-level instance mask annotations and diagnosis labels for four clinical categories (buckle, nondisplaced, displaced, or segmental). The challenge includes two tracks: a detection (instance segmentation) track evaluated by an FROC-style metric and a classification track evaluated by an F1-style metric. During the MICCAI 2020 challenge period, 243 results were evaluated, and seven teams were invited to participate in the challenge summary. The analysis revealed that several top rib fracture detection solutions achieved performance comparable or even better than human experts. Nevertheless, the current rib fracture classification solutions are hardly clinically applicable, which can be an interesting area in the future. As an active benchmark and research resource, the data and online evaluation of the RibFrac Challenge are available at the challenge website. As an independent contribution, we have also extended our previous internal baseline by incorporating recent advancements in large-scale pretrained networks and point-based rib segmentation techniques. The resulting FracNet+ demonstrates competitive performance in rib fracture detection, which lays a foundation for further research and development in AI-assisted rib fracture detection and diagnosis.
Image Content Generation with Causal Reasoning
Dec 12, 2023The emergence of ChatGPT has once again sparked research in generative artificial intelligence (GAI). While people have been amazed by the generated results, they have also noticed the reasoning potential reflected in the generated textual content. However, this current ability for causal reasoning is primarily limited to the domain of language generation, such as in models like GPT-3. In visual modality, there is currently no equivalent research. Considering causal reasoning in visual content generation is significant. This is because visual information contains infinite granularity. Particularly, images can provide more intuitive and specific demonstrations for certain reasoning tasks, especially when compared to coarse-grained text. Hence, we propose a new image generation task called visual question answering with image (VQAI) and establish a dataset of the same name based on the classic \textit{Tom and Jerry} animated series. Additionally, we develop a new paradigm for image generation to tackle the challenges of this task. Finally, we perform extensive experiments and analyses, including visualizations of the generated content and discussions on the potentials and limitations. The code and data are publicly available under the license of CC BY-NC-SA 4.0 for academic and non-commercial usage. The code and dataset are publicly available at: https://github.com/IEIT-AGI/MIX-Shannon/blob/main/projects/VQAI/lgd_vqai.md.
Robust Anti-jamming Communications with DMA-Based Reconfigurable Heterogeneous Array
Oct 14, 2023



In the future commercial and military communication systems, anti-jamming remains a critical issue. Existing homogeneous or heterogeneous arrays with a limited degrees of freedom (DoF) and high consumption are unable to meet the requirements of communication in rapidly changing and intense jamming environments. To address these challenges, we propose a reconfigurable heterogeneous array (RHA) architecture based on dynamic metasurface antenna (DMA), which will increase the DoF and further improve anti-jamming capabilities. We propose a two-step anti-jamming scheme based on RHA, where the multipaths are estimated by an atomic norm minimization (ANM) based scheme, and then the received signal-to-interference-plus-noise ratio (SINR) is maximized by jointly designing the phase shift of each DMA element and the weights of the array elements. To solve the challenging non-convex discrete fractional problem along with the estimation error in the direction of arrival (DoA) and channel state information (CSI), we propose a robust alternative algorithm based on the S-procedure to solve the lower-bound SINR maximization problem. Simulation results demonstrate that the proposed RHA architecture and corresponding schemes have superior performance in terms of jamming immunity and robustness.
Efficient Gaussian Process Classification-based Physical-Layer Authentication with Configurable Fingerprints for 6G-Enabled IoT
Jul 23, 2023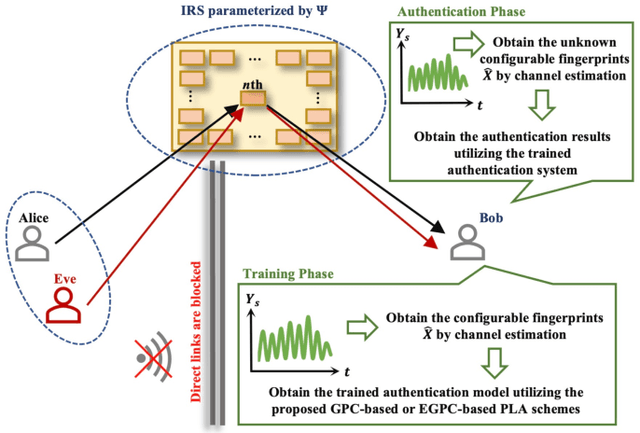
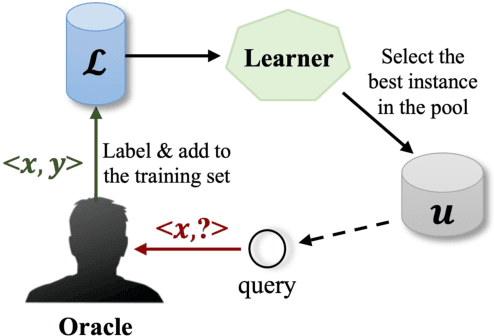
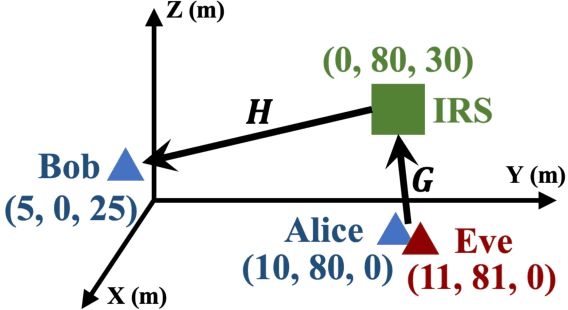
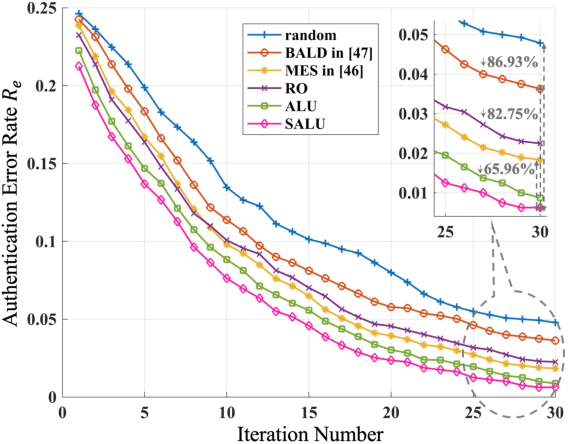
Physical-Layer Authentication (PLA) has been recently believed as an endogenous-secure and energy-efficient technique to recognize IoT terminals. However, the major challenge of applying the state-of-the-art PLA schemes directly to 6G-enabled IoT is the inaccurate channel fingerprint estimation in low Signal-Noise Ratio (SNR) environments, which will greatly influence the reliability and robustness of PLA. To tackle this issue, we propose a configurable-fingerprint-based PLA architecture through Intelligent Reflecting Surface (IRS) that helps create an alternative wireless transmission path to provide more accurate fingerprints. According to Baye's theorem, we propose a Gaussian Process Classification (GPC)-based PLA scheme, which utilizes the Expectation Propagation (EP) method to obtain the identities of unknown fingerprints. Considering that obtaining sufficient labeled fingerprint samples to train the GPC-based authentication model is challenging for future 6G systems, we further extend the GPC-based PLA to the Efficient-GPC (EGPC)-based PLA through active learning, which requires fewer labeled fingerprints and is more feasible. We also propose three fingerprint selecting algorithms to choose fingerprints, whose identities are queried to the upper-layers authentication mechanisms. For this reason, the proposed EGPC-based scheme is also a lightweight cross-layer authentication method to offer a superior security level. The simulations conducted on synthetic datasets demonstrate that the IRS-assisted scheme reduces the authentication error rate by 98.69% compared to the non-IRS-based scheme. Additionally, the proposed fingerprint selection algorithms reduce the authentication error rate by 65.96% to 86.93% and 45.45% to 70.00% under perfect and imperfect channel estimation conditions, respectively, when compared with baseline algorithms.
RibSeg v2: A Large-scale Benchmark for Rib Labeling and Anatomical Centerline Extraction
Oct 18, 2022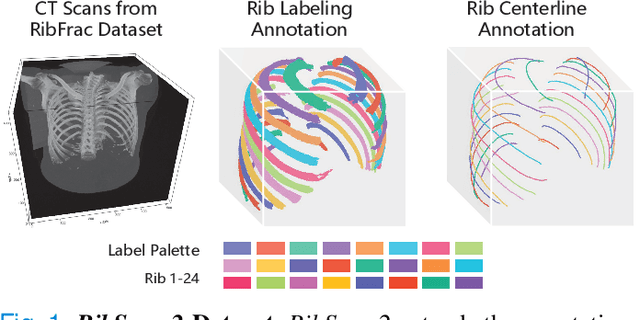

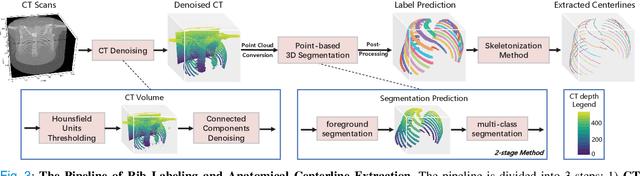
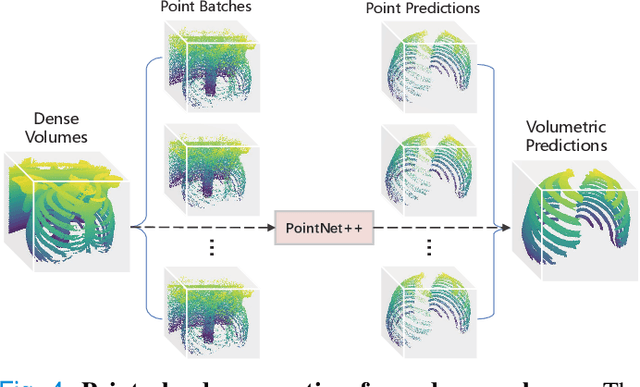
Automatic rib labeling and anatomical centerline extraction are common prerequisites for various clinical applications. Prior studies either use in-house datasets that are inaccessible to communities, or focus on rib segmentation that neglects the clinical significance of rib labeling. To address these issues, we extend our prior dataset (RibSeg) on the binary rib segmentation task to a comprehensive benchmark, named RibSeg v2, with 660 CT scans (15,466 individual ribs in total) and annotations manually inspected by experts for rib labeling and anatomical centerline extraction. Based on the RibSeg v2, we develop a pipeline including deep learning-based methods for rib labeling, and a skeletonization-based method for centerline extraction. To improve computational efficiency, we propose a sparse point cloud representation of CT scans and compare it with standard dense voxel grids. Moreover, we design and analyze evaluation metrics to address the key challenges of each task. Our dataset, code, and model are available online to facilitate open research at https://github.com/M3DV/RibSeg