 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Shared-Autonomy Construction Robotic System for Overhead Works
Nov 12, 2025We present the ongoing development of a robotic system for overhead work such as ceiling drilling. The hardware platform comprises a mobile base with a two-stage lift, on which a bimanual torso is mounted with a custom-designed drilling end effector and RGB-D cameras. To support teleoperation in dynamic environments with limited visibility, we use Gaussian splatting for online 3D reconstruction and introduce motion parameters to model moving objects. For safe operation around dynamic obstacles, we developed a neural configuration-space barrier approach for planning and control. Initial feasibility studies demonstrate the capability of the hardware in drilling, bolting, and anchoring, and the software in safe teleoperation in a dynamic environment.
DynaGSLAM: Real-Time Gaussian-Splatting SLAM for Online Rendering, Tracking, Motion Predictions of Moving Objects in Dynamic Scenes
Mar 15, 2025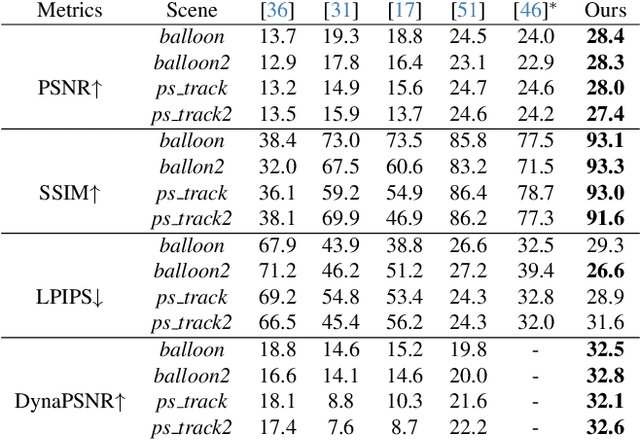

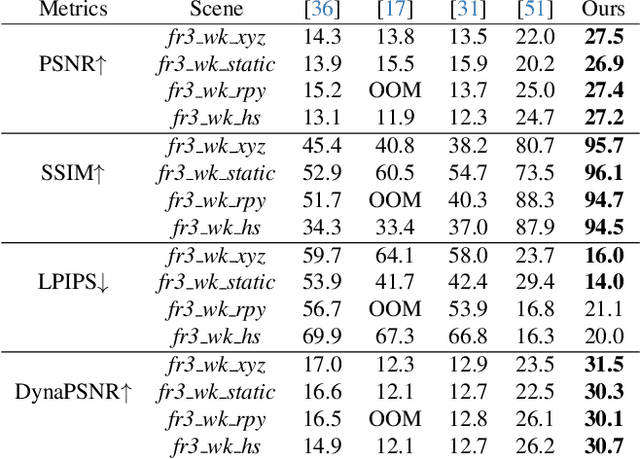
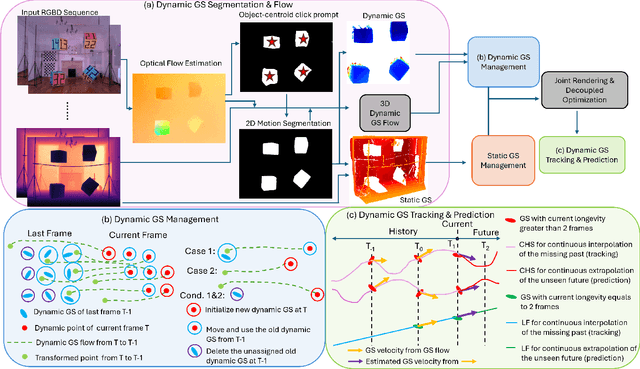
Simultaneous Localization and Mapping (SLAM) is one of the most important environment-perception and navigation algorithms for computer vision, robotics, and autonomous cars/drones. Hence, high quality and fast mapping becomes a fundamental problem. With the advent of 3D Gaussian Splatting (3DGS) as an explicit representation with excellent rendering quality and speed, state-of-the-art (SOTA) works introduce GS to SLAM. Compared to classical pointcloud-SLAM, GS-SLAM generates photometric information by learning from input camera views and synthesize unseen views with high-quality textures. However, these GS-SLAM fail when moving objects occupy the scene that violate the static assumption of bundle adjustment. The failed updates of moving GS affects the static GS and contaminates the full map over long frames. Although some efforts have been made by concurrent works to consider moving objects for GS-SLAM, they simply detect and remove the moving regions from GS rendering ("anti'' dynamic GS-SLAM), where only the static background could benefit from GS. To this end, we propose the first real-time GS-SLAM, "DynaGSLAM'', that achieves high-quality online GS rendering, tracking, motion predictions of moving objects in dynamic scenes while jointly estimating accurate ego motion. Our DynaGSLAM outperforms SOTA static & "Anti'' dynamic GS-SLAM on three dynamic real datasets, while keeping speed and memory efficiency in practice.
Open-Vocabulary Semantic Part Segmentation of 3D Human
Feb 27, 20253D part segmentation is still an open problem in the field of 3D vision and AR/VR. Due to limited 3D labeled data, traditional supervised segmentation methods fall short in generalizing to unseen shapes and categories. Recently, the advancement in vision-language models' zero-shot abilities has brought a surge in open-world 3D segmentation methods. While these methods show promising results for 3D scenes or objects, they do not generalize well to 3D humans. In this paper, we present the first open-vocabulary segmentation method capable of handling 3D human. Our framework can segment the human category into desired fine-grained parts based on the textual prompt. We design a simple segmentation pipeline, leveraging SAM to generate multi-view proposals in 2D and proposing a novel HumanCLIP model to create unified embeddings for visual and textual inputs. Compared with existing pre-trained CLIP models, the HumanCLIP model yields more accurate embeddings for human-centric contents. We also design a simple-yet-effective MaskFusion module, which classifies and fuses multi-view features into 3D semantic masks without complex voting and grouping mechanisms. The design of decoupling mask proposals and text input also significantly boosts the efficiency of per-prompt inference. Experimental results on various 3D human datasets show that our method outperforms current state-of-the-art open-vocabulary 3D segmentation methods by a large margin. In addition, we show that our method can be directly applied to various 3D representations including meshes, point clouds, and 3D Gaussian Splatting.
GlossGau: Efficient Inverse Rendering for Glossy Surface with Anisotropic Spherical Gaussian
Feb 19, 2025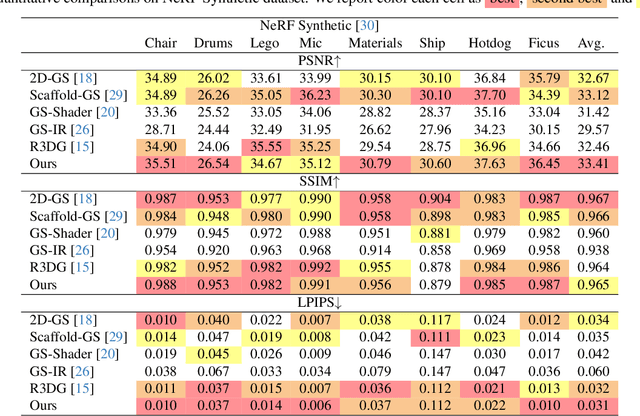
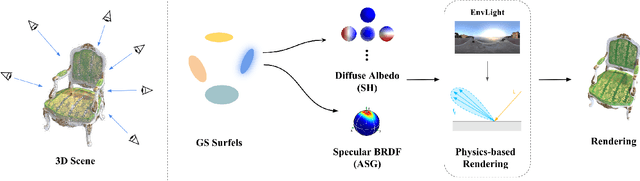
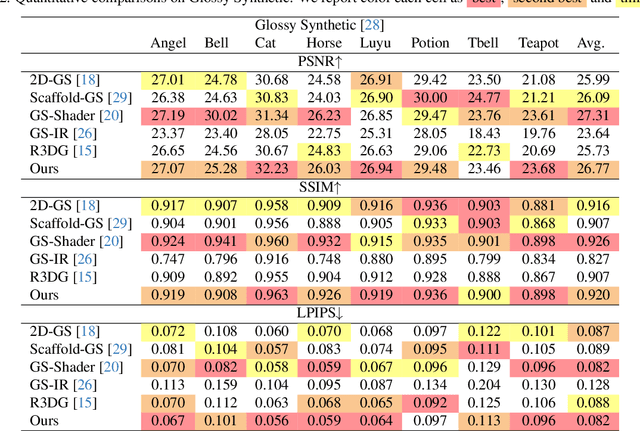

The reconstruction of 3D objects from calibrated photographs represents a fundamental yet intricate challenge in the domains of computer graphics and vision. Although neural reconstruction approaches based on Neural Radiance Fields (NeRF) have shown remarkable capabilities, their processing costs remain substantial. Recently, the advent of 3D Gaussian Splatting (3D-GS) largely improves the training efficiency and facilitates to generate realistic rendering in real-time. However, due to the limited ability of Spherical Harmonics (SH) to represent high-frequency information, 3D-GS falls short in reconstructing glossy objects. Researchers have turned to enhance the specular expressiveness of 3D-GS through inverse rendering. Yet these methods often struggle to maintain the training and rendering efficiency, undermining the benefits of Gaussian Splatting techniques. In this paper, we introduce GlossGau, an efficient inverse rendering framework that reconstructs scenes with glossy surfaces while maintaining training and rendering speeds comparable to vanilla 3D-GS. Specifically, we explicitly model the surface normals, Bidirectional Reflectance Distribution Function (BRDF) parameters, as well as incident lights and use Anisotropic Spherical Gaussian (ASG) to approximate the per-Gaussian Normal Distribution Function under the microfacet model. We utilize 2D Gaussian Splatting (2D-GS) as foundational primitives and apply regularization to significantly alleviate the normal estimation challenge encountered in related works. Experiments demonstrate that GlossGau achieves competitive or superior reconstruction on datasets with glossy surfaces. Compared with previous GS-based works that address the specular surface, our optimization time is considerably less.
SplatSDF: Boosting Neural Implicit SDF via Gaussian Splatting Fusion
Nov 23, 2024



A signed distance function (SDF) is a useful representation for continuous-space geometry and many related operations, including rendering, collision checking, and mesh generation. Hence, reconstructing SDF from image observations accurately and efficiently is a fundamental problem. Recently, neural implicit SDF (SDF-NeRF) techniques, trained using volumetric rendering, have gained a lot of attention. Compared to earlier truncated SDF (TSDF) fusion algorithms that rely on depth maps and voxelize continuous space, SDF-NeRF enables continuous-space SDF reconstruction with better geometric and photometric accuracy. However, the accuracy and convergence speed of scene-level SDF reconstruction require further improvements for many applications. With the advent of 3D Gaussian Splatting (3DGS) as an explicit representation with excellent rendering quality and speed, several works have focused on improving SDF-NeRF by introducing consistency losses on depth and surface normals between 3DGS and SDF-NeRF. However, loss-level connections alone lead to incremental improvements. We propose a novel neural implicit SDF called "SplatSDF" to fuse 3DGSandSDF-NeRF at an architecture level with significant boosts to geometric and photometric accuracy and convergence speed. Our SplatSDF relies on 3DGS as input only during training, and keeps the same complexity and efficiency as the original SDF-NeRF during inference. Our method outperforms state-of-the-art SDF-NeRF models on geometric and photometric evaluation by the time of submission.