 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTopology-Preserving Image Segmentation with Spatial-Aware Persistent Feature Matching
Dec 03, 2024



Topological correctness is critical for segmentation of tubular structures. Existing topological segmentation loss functions are primarily based on the persistent homology of the image. They match the persistent features from the segmentation with the persistent features from the ground truth and minimize the difference between them. However, these methods suffer from an ambiguous matching problem since the matching only relies on the information in the topological space. In this work, we propose an effective and efficient Spatial-Aware Topological Loss Function that further leverages the information in the original spatial domain of the image to assist the matching of persistent features. Extensive experiments on images of various types of tubular structures show that the proposed method has superior performance in improving the topological accuracy of the segmentation compared with state-of-the-art methods.
Multi-target and multi-stage liver lesion segmentation and detection in multi-phase computed tomography scans
Apr 17, 2024



Multi-phase computed tomography (CT) scans use contrast agents to highlight different anatomical structures within the body to improve the probability of identifying and detecting anatomical structures of interest and abnormalities such as liver lesions. Yet, detecting these lesions remains a challenging task as these lesions vary significantly in their size, shape, texture, and contrast with respect to surrounding tissue. Therefore, radiologists need to have an extensive experience to be able to identify and detect these lesions. Segmentation-based neural networks can assist radiologists with this task. Current state-of-the-art lesion segmentation networks use the encoder-decoder design paradigm based on the UNet architecture where the multi-phase CT scan volume is fed to the network as a multi-channel input. Although this approach utilizes information from all the phases and outperform single-phase segmentation networks, we demonstrate that their performance is not optimal and can be further improved by incorporating the learning from models trained on each single-phase individually. Our approach comprises three stages. The first stage identifies the regions within the liver where there might be lesions at three different scales (4, 8, and 16 mm). The second stage includes the main segmentation model trained using all the phases as well as a segmentation model trained on each of the phases individually. The third stage uses the multi-phase CT volumes together with the predictions from each of the segmentation models to generate the final segmentation map. Overall, our approach improves relative liver lesion segmentation performance by 1.6% while reducing performance variability across subjects by 8% when compared to the current state-of-the-art models.
Deep learning network to correct axial and coronal eye motion in 3D OCT retinal imaging
May 27, 2023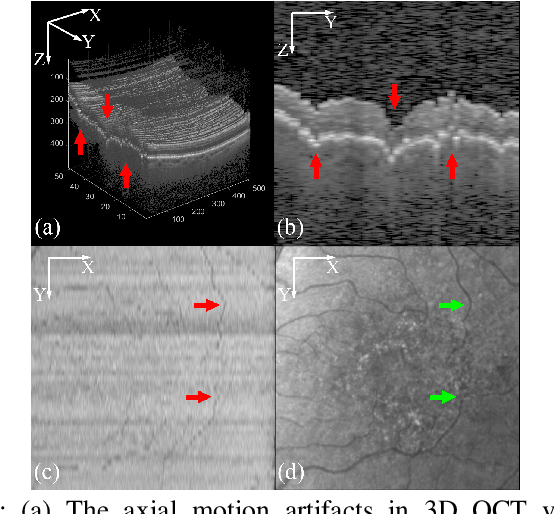
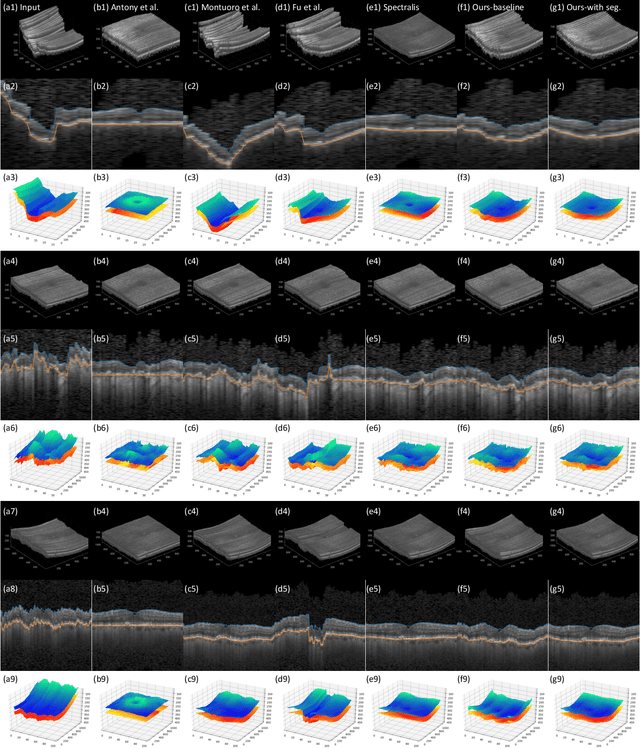
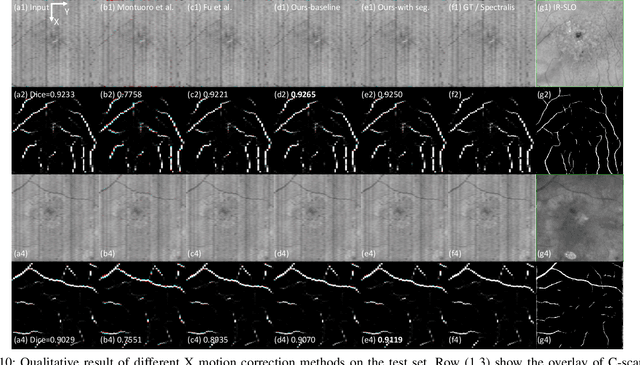
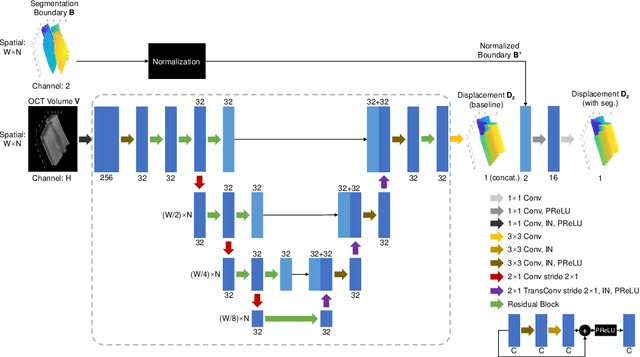
Optical Coherence Tomography (OCT) is one of the most important retinal imaging technique. However, involuntary motion artifacts still pose a major challenge in OCT imaging that compromises the quality of downstream analysis, such as retinal layer segmentation and OCT Angiography. We propose deep learning based neural networks to correct axial and coronal motion artifacts in OCT based on a single volumetric scan. The proposed method consists of two fully-convolutional neural networks that predict Z and X dimensional displacement maps sequentially in two stages. The experimental result shows that the proposed method can effectively correct motion artifacts and achieve smaller error than other methods. Specifically, the method can recover the overall curvature of the retina, and can be generalized well to various diseases and resolutions.
A CNN Segmentation-Based Approach to Object Detection and Tracking in Ultrasound Scans with Application to the Vagus Nerve Detection
Jun 25, 2021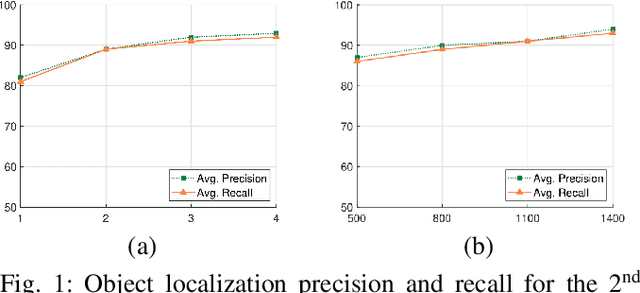
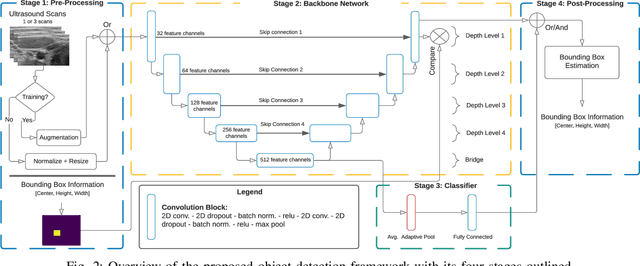
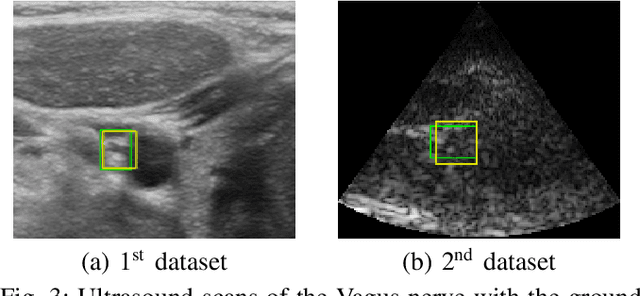
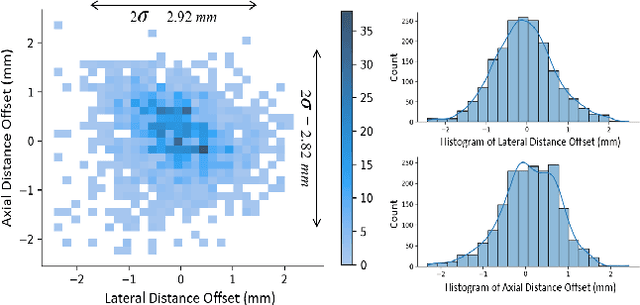
Ultrasound scanning is essential in several medical diagnostic and therapeutic applications. It is used to visualize and analyze anatomical features and structures that influence treatment plans. However, it is both labor intensive, and its effectiveness is operator dependent. Real-time accurate and robust automatic detection and tracking of anatomical structures while scanning would significantly impact diagnostic and therapeutic procedures to be consistent and efficient. In this paper, we propose a deep learning framework to automatically detect and track a specific anatomical target structure in ultrasound scans. Our framework is designed to be accurate and robust across subjects and imaging devices, to operate in real-time, and to not require a large training set. It maintains a localization precision and recall higher than 90% when trained on training sets that are as small as 20% in size of the original training set. The framework backbone is a weakly trained segmentation neural network based on U-Net. We tested the framework on two different ultrasound datasets with the aim to detect and track the Vagus nerve, where it outperformed current state-of-the-art real-time object detection networks.
SG2Caps: Revisiting Scene Graphs for Image Captioning
Feb 09, 2021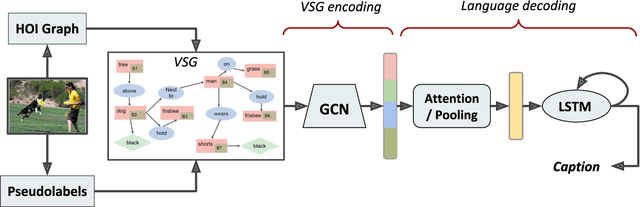
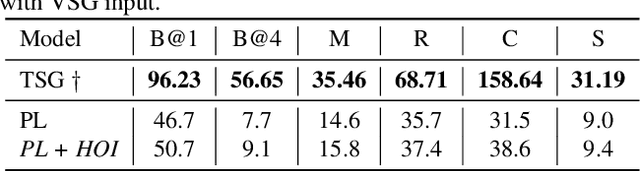
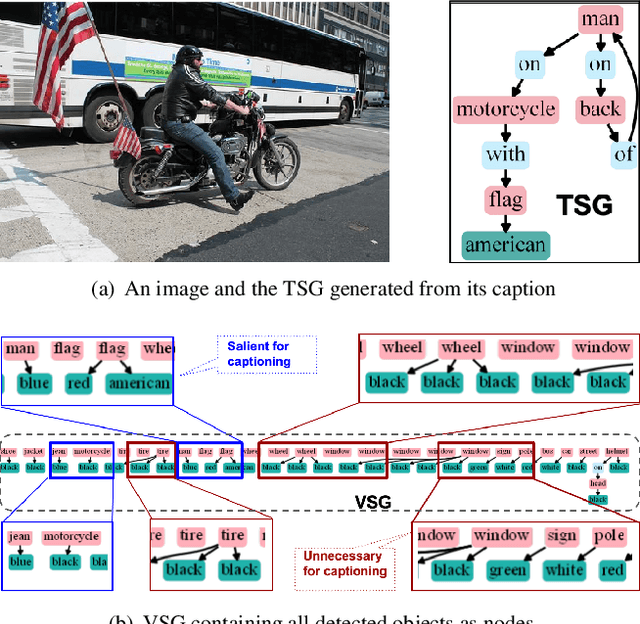
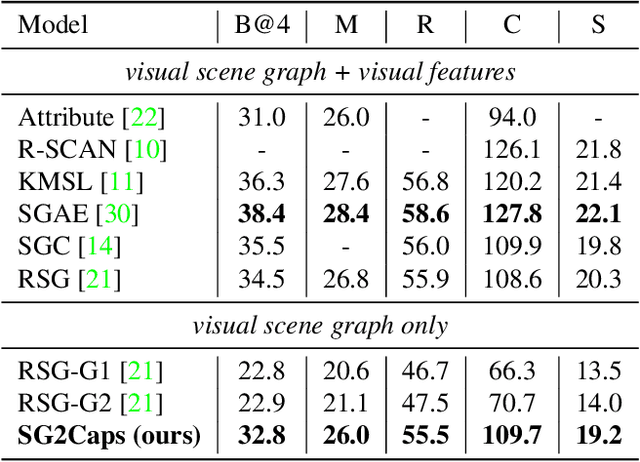
The mainstream image captioning models rely on Convolutional Neural Network (CNN) image features with an additional attention to salient regions and objects to generate captions via recurrent models. Recently, scene graph representations of images have been used to augment captioning models so as to leverage their structural semantics, such as object entities, relationships and attributes. Several studies have noted that naive use of scene graphs from a black-box scene graph generator harms image caption-ing performance, and scene graph-based captioning mod-els have to incur the overhead of explicit use of image features to generate decent captions. Addressing these challenges, we propose a framework, SG2Caps, that utilizes only the scene graph labels for competitive image caption-ing performance. The basic idea is to close the semantic gap between two scene graphs - one derived from the input image and the other one from its caption. In order to achieve this, we leverage the spatial location of objects and the Human-Object-Interaction (HOI) labels as an additional HOI graph. Our framework outperforms existing scene graph-only captioning models by a large margin (CIDEr score of 110 vs 71) indicating scene graphs as a promising representation for image captioning. Direct utilization of the scene graph labels avoids expensive graph convolutions over high-dimensional CNN features resulting in 49%fewer trainable parameters.
Toward Joint Image Generation and Compression using Generative Adversarial Networks
Jan 23, 2019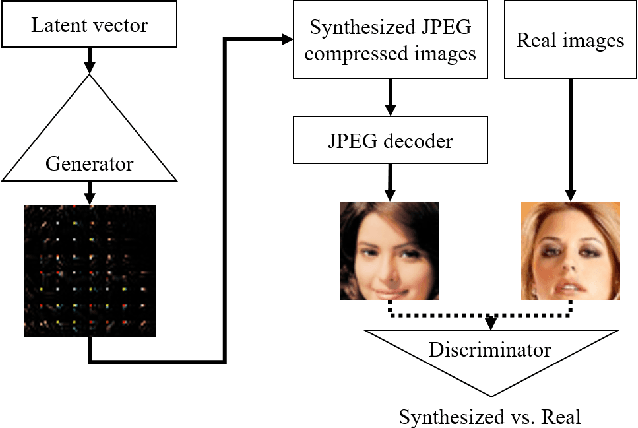

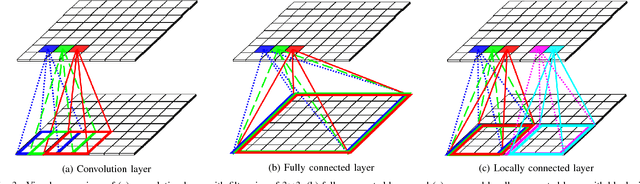

In this paper, we present a generative adversarial network framework that generates compressed images instead of synthesizing raw RGB images and compressing them separately. In the real world, most images and videos are stored and transferred in a compressed format to save storage capacity and data transfer bandwidth. However, since typical generative adversarial networks generate raw RGB images, those generated images need to be compressed by a post-processing stage to reduce the data size. Among image compression methods, JPEG has been one of the most commonly used lossy compression methods for still images. Hence, we propose a novel framework that generates JPEG compressed images using generative adversarial networks. The novel generator consists of the proposed locally connected layers, chroma subsampling layers, quantization layers, residual blocks, and convolution layers. The locally connected layer is proposed to enable block-based operations. We also discuss training strategies for the proposed architecture including the loss function and the transformation between its generator and its discriminator. The proposed method is evaluated using the publicly available CIFAR-10 dataset and LSUN bedroom dataset. The results demonstrate that the proposed method is able to generate compressed data with competitive qualities. The proposed method is a promising baseline method for joint image generation and compression using generative adversarial networks.
Random Forest with Learned Representations for Semantic Segmentation
Jan 23, 2019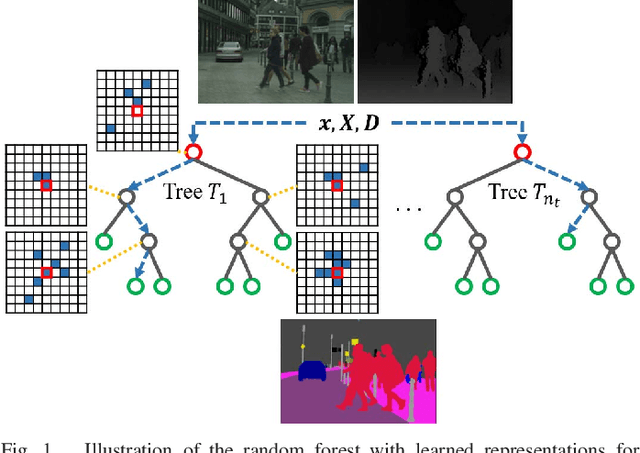
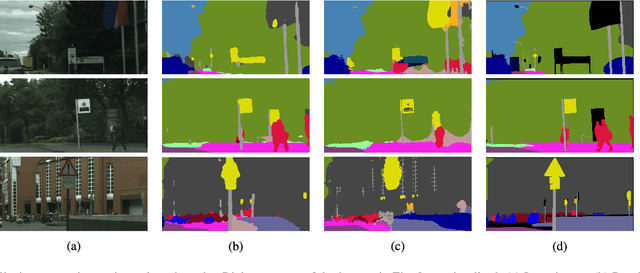
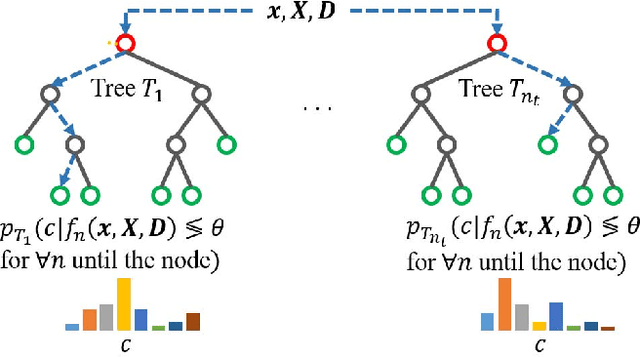
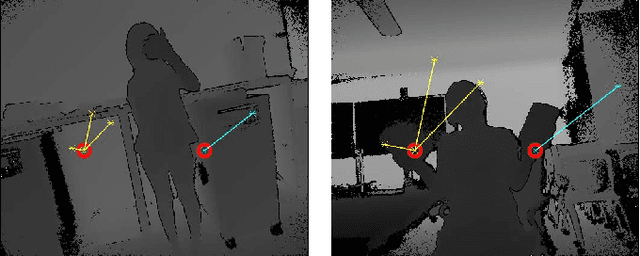
In this work, we present a random forest framework that learns the weights, shapes, and sparsities of feature representations for real-time semantic segmentation. Typical filters (kernels) have predetermined shapes and sparsities and learn only weights. A few feature extraction methods fix weights and learn only shapes and sparsities. These predetermined constraints restrict learning and extracting optimal features. To overcome this limitation, we propose an unconstrained representation that is able to extract optimal features by learning weights, shapes, and sparsities. We, then, present the random forest framework that learns the flexible filters using an iterative optimization algorithm and segments input images using the learned representations. We demonstrate the effectiveness of the proposed method using a hand segmentation dataset for hand-object interaction and using two semantic segmentation datasets. The results show that the proposed method achieves real-time semantic segmentation using limited computational and memory resources.
Image denoising with generalized Gaussian mixture model patch priors
Jun 11, 2018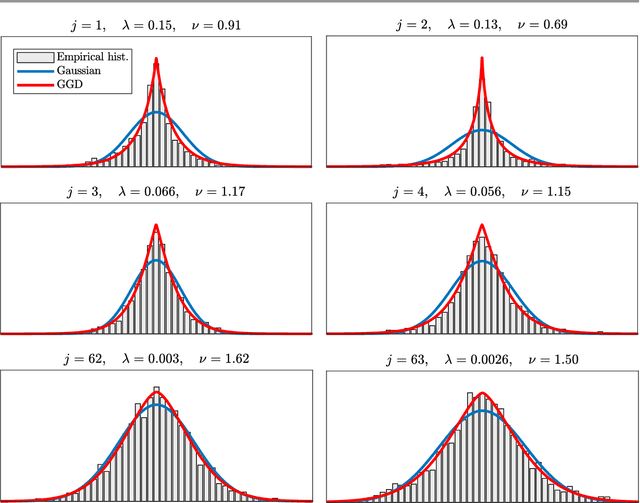

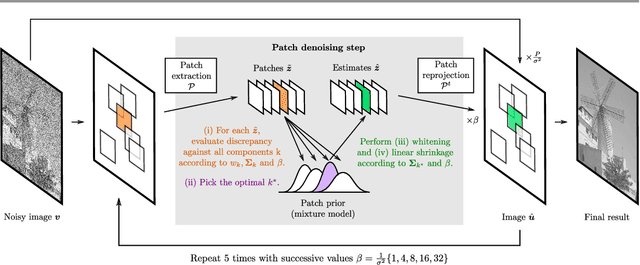
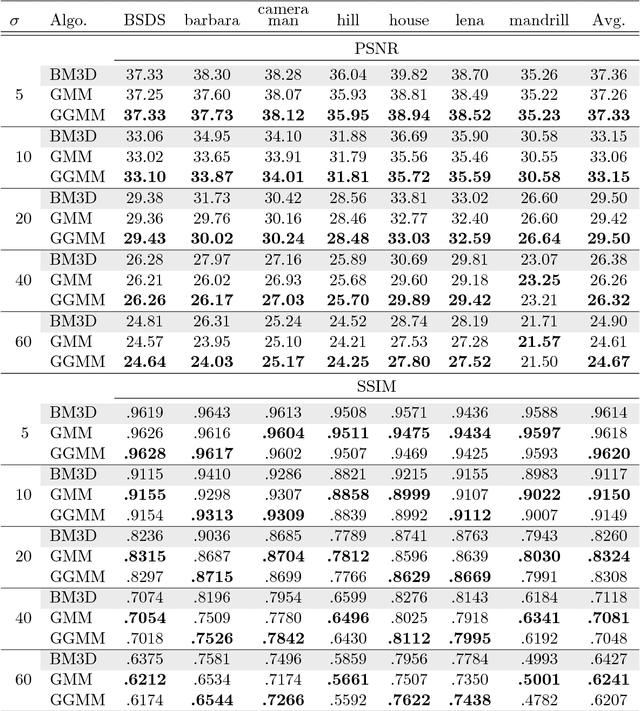
Patch priors have become an important component of image restoration. A powerful approach in this category of restoration algorithms is the popular Expected Patch Log-Likelihood (EPLL) algorithm. EPLL uses a Gaussian mixture model (GMM) prior learned on clean image patches as a way to regularize degraded patches. In this paper, we show that a generalized Gaussian mixture model (GGMM) captures the underlying distribution of patches better than a GMM. Even though GGMM is a powerful prior to combine with EPLL, the non-Gaussianity of its components presents major challenges to be applied to a computationally intensive process of image restoration. Specifically, each patch has to undergo a patch classification step and a shrinkage step. These two steps can be efficiently solved with a GMM prior but are computationally impractical when using a GGMM prior. In this paper, we provide approximations and computational recipes for fast evaluation of these two steps, so that EPLL can embed a GGMM prior on an image with more than tens of thousands of patches. Our main contribution is to analyze the accuracy of our approximations based on thorough theoretical analysis. Our evaluations indicate that the GGMM prior is consistently a better fit formodeling image patch distribution and performs better on average in image denoising task.
DPW-SDNet: Dual Pixel-Wavelet Domain Deep CNNs for Soft Decoding of JPEG-Compressed Images
May 27, 2018
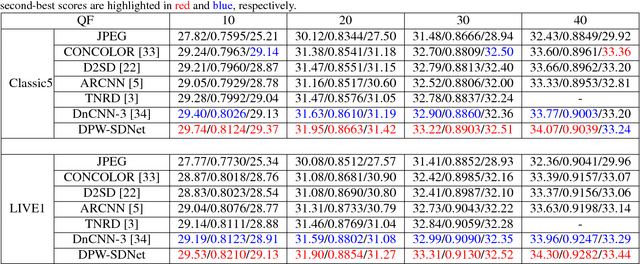
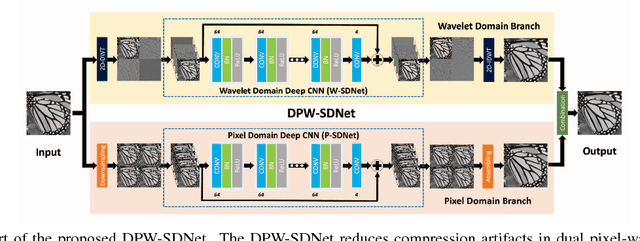
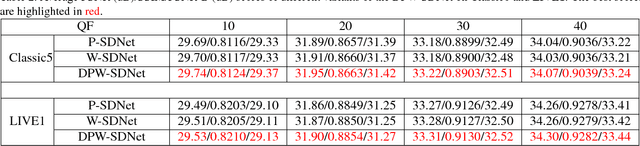
JPEG is one of the widely used lossy compression methods. JPEG-compressed images usually suffer from compression artifacts including blocking and blurring, especially at low bit-rates. Soft decoding is an effective solution to improve the quality of compressed images without changing codec or introducing extra coding bits. Inspired by the excellent performance of the deep convolutional neural networks (CNNs) on both low-level and high-level computer vision problems, we develop a dual pixel-wavelet domain deep CNNs-based soft decoding network for JPEG-compressed images, namely DPW-SDNet. The pixel domain deep network takes the four downsampled versions of the compressed image to form a 4-channel input and outputs a pixel domain prediction, while the wavelet domain deep network uses the 1-level discrete wavelet transformation (DWT) coefficients to form a 4-channel input to produce a DWT domain prediction. The pixel domain and wavelet domain estimates are combined to generate the final soft decoded result. Experimental results demonstrate the superiority of the proposed DPW-SDNet over several state-of-the-art compression artifacts reduction algorithms.
Correction by Projection: Denoising Images with Generative Adversarial Networks
Mar 12, 2018


Generative adversarial networks (GANs) transform low-dimensional latent vectors into visually plausible images. If the real dataset contains only clean images, then ostensibly, the manifold learned by the GAN should contain only clean images. In this paper, we propose to denoise corrupted images by finding the nearest point on the GAN manifold, recovering latent vectors by minimizing distances in image space. We first demonstrate that given a corrupted version of an image that truly lies on the GAN manifold, we can approximately recover the latent vector and denoise the image, obtaining significantly higher quality, comparing with BM3D. Next, we demonstrate that latent vectors recovered from noisy images exhibit a consistent bias. By subtracting this bias before projecting back to image space, we improve denoising results even further. Finally, even for unseen images, our method performs better at denoising better than BM3D. Notably, the basic version of our method (without bias correction) requires no prior knowledge on the noise variance. To achieve the highest possible denoising quality, the best performing signal processing based methods, such as BM3D, require an estimate of the blur kernel.