 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniversal Vessel Segmentation for Multi-Modality Retinal Images
Feb 10, 2025
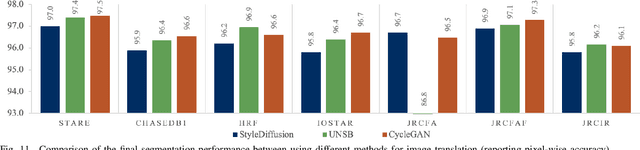
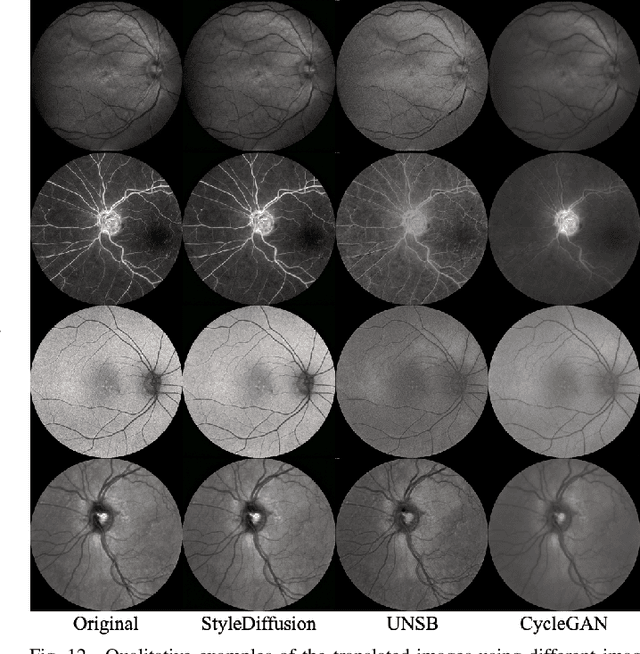
We identify two major limitations in the existing studies on retinal vessel segmentation: (1) Most existing works are restricted to one modality, i.e, the Color Fundus (CF). However, multi-modality retinal images are used every day in the study of retina and retinal diseases, and the study of vessel segmentation on the other modalities is scarce; (2) Even though a small amount of works extended their experiments to limited new modalities such as the Multi-Color Scanning Laser Ophthalmoscopy (MC), these works still require finetuning a separate model for the new modality. And the finetuning will require extra training data, which is difficult to acquire. In this work, we present a foundational universal vessel segmentation model (UVSM) for multi-modality retinal images. Not only do we perform the study on a much wider range of modalities, but also we propose a universal model to segment the vessels in all these commonly-used modalities. Despite being much more versatile comparing with existing methods, our universal model still demonstrates comparable performance with the state-of-the- art finetuned methods. To the best of our knowledge, this is the first work that achieves cross-modality retinal vessel segmentation and also the first work to study retinal vessel segmentation in some novel modalities.
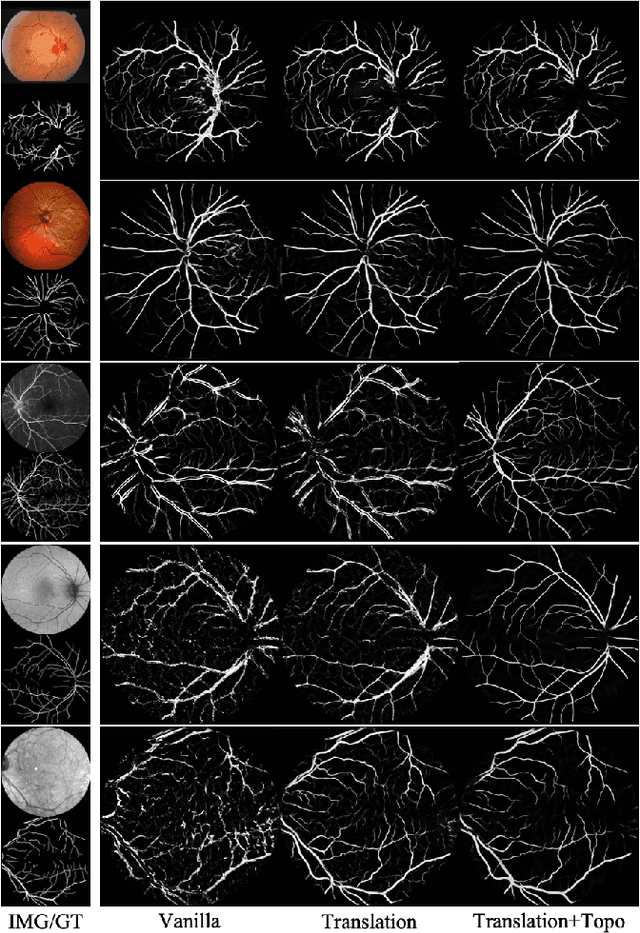
Topology-Preserving Image Segmentation with Spatial-Aware Persistent Feature Matching
Dec 03, 2024



Topological correctness is critical for segmentation of tubular structures. Existing topological segmentation loss functions are primarily based on the persistent homology of the image. They match the persistent features from the segmentation with the persistent features from the ground truth and minimize the difference between them. However, these methods suffer from an ambiguous matching problem since the matching only relies on the information in the topological space. In this work, we propose an effective and efficient Spatial-Aware Topological Loss Function that further leverages the information in the original spatial domain of the image to assist the matching of persistent features. Extensive experiments on images of various types of tubular structures show that the proposed method has superior performance in improving the topological accuracy of the segmentation compared with state-of-the-art methods.
Multi-target and multi-stage liver lesion segmentation and detection in multi-phase computed tomography scans
Apr 17, 2024



Multi-phase computed tomography (CT) scans use contrast agents to highlight different anatomical structures within the body to improve the probability of identifying and detecting anatomical structures of interest and abnormalities such as liver lesions. Yet, detecting these lesions remains a challenging task as these lesions vary significantly in their size, shape, texture, and contrast with respect to surrounding tissue. Therefore, radiologists need to have an extensive experience to be able to identify and detect these lesions. Segmentation-based neural networks can assist radiologists with this task. Current state-of-the-art lesion segmentation networks use the encoder-decoder design paradigm based on the UNet architecture where the multi-phase CT scan volume is fed to the network as a multi-channel input. Although this approach utilizes information from all the phases and outperform single-phase segmentation networks, we demonstrate that their performance is not optimal and can be further improved by incorporating the learning from models trained on each single-phase individually. Our approach comprises three stages. The first stage identifies the regions within the liver where there might be lesions at three different scales (4, 8, and 16 mm). The second stage includes the main segmentation model trained using all the phases as well as a segmentation model trained on each of the phases individually. The third stage uses the multi-phase CT volumes together with the predictions from each of the segmentation models to generate the final segmentation map. Overall, our approach improves relative liver lesion segmentation performance by 1.6% while reducing performance variability across subjects by 8% when compared to the current state-of-the-art models.
Deep learning network to correct axial and coronal eye motion in 3D OCT retinal imaging
May 27, 2023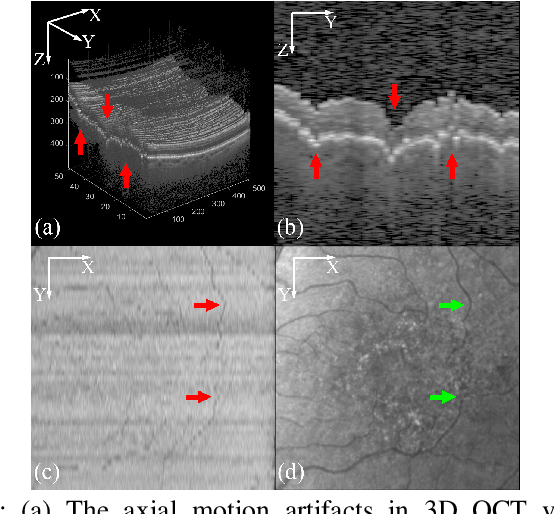
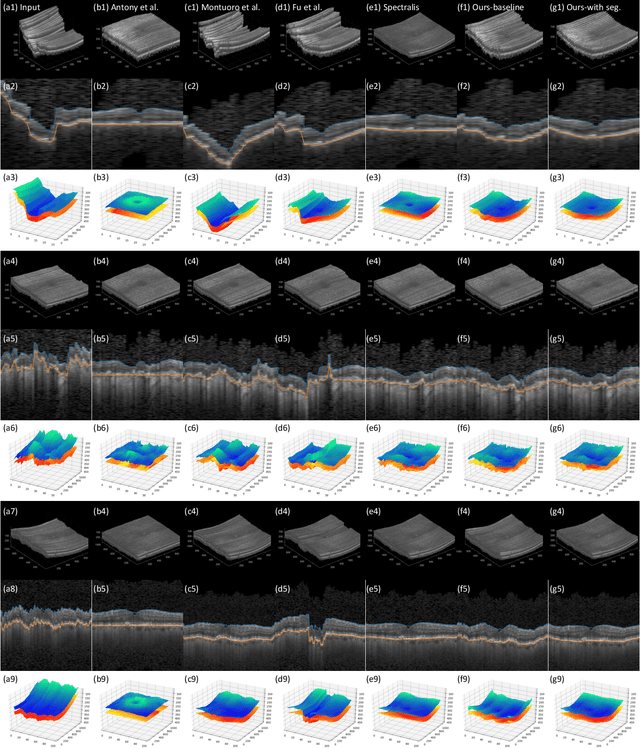
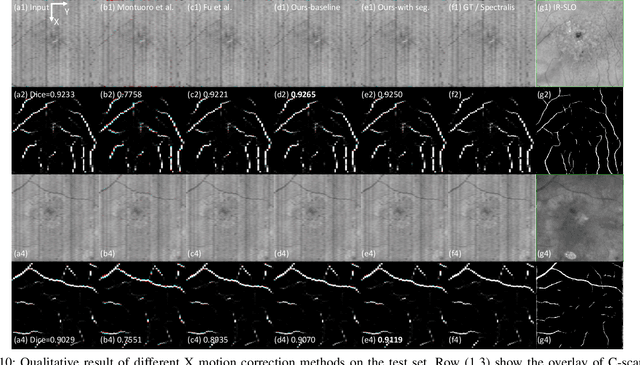
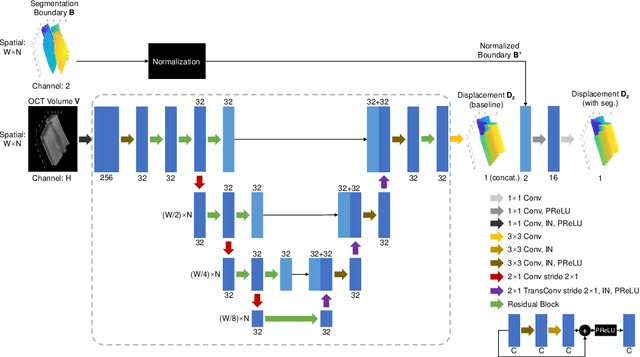
Optical Coherence Tomography (OCT) is one of the most important retinal imaging technique. However, involuntary motion artifacts still pose a major challenge in OCT imaging that compromises the quality of downstream analysis, such as retinal layer segmentation and OCT Angiography. We propose deep learning based neural networks to correct axial and coronal motion artifacts in OCT based on a single volumetric scan. The proposed method consists of two fully-convolutional neural networks that predict Z and X dimensional displacement maps sequentially in two stages. The experimental result shows that the proposed method can effectively correct motion artifacts and achieve smaller error than other methods. Specifically, the method can recover the overall curvature of the retina, and can be generalized well to various diseases and resolutions.