 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Machine Learning-Based Study on the Synergistic Optimization of Supply Chain Management and Financial Supply Chains from an Economic Perspective
Sep 03, 2025Based on economic theories and integrated with machine learning technology, this study explores a collaborative Supply Chain Management and Financial Supply Chain Management (SCM - FSCM) model to solve issues like efficiency loss, financing constraints, and risk transmission. We combine Transaction Cost and Information Asymmetry theories and use algorithms such as random forests to process multi-dimensional data and build a data-driven, three-dimensional (cost-efficiency-risk) analysis framework. We then apply an FSCM model of "core enterprise credit empowerment plus dynamic pledge financing." We use Long Short-Term Memory (LSTM) networks for demand forecasting and clustering/regression algorithms for benefit allocation. The study also combines Game Theory and reinforcement learning to optimize the inventory-procurement mechanism and uses eXtreme Gradient Boosting (XGBoost) for credit assessment to enable rapid monetization of inventory. Verified with 20 core and 100 supporting enterprises, the results show a 30\% increase in inventory turnover, an 18\%-22\% decrease in SME financing costs, a stable order fulfillment rate above 95\%, and excellent model performance (demand forecasting error <= 8\%, credit assessment accuracy >= 90\%). This SCM-FSCM model effectively reduces operating costs, alleviates financing constraints, and supports high-quality supply chain development.
Attributed Graph Clustering with Multi-Scale Weight-Based Pairwise Coarsening and Contrastive Learning
Jul 28, 2025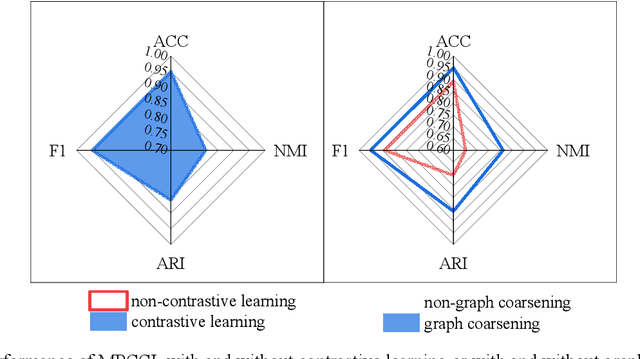
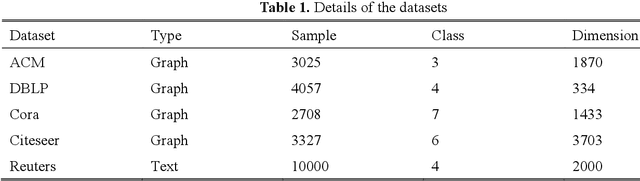
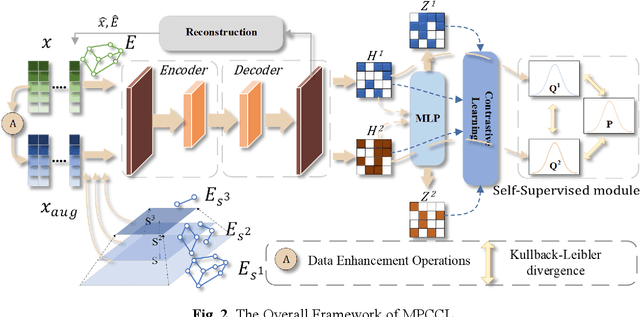
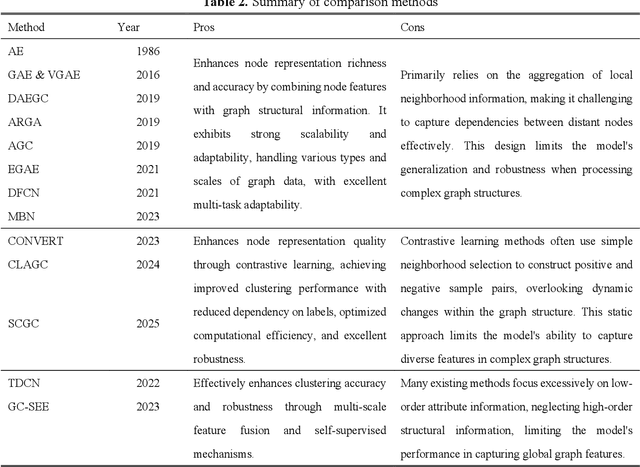
This study introduces the Multi-Scale Weight-Based Pairwise Coarsening and Contrastive Learning (MPCCL) model, a novel approach for attributed graph clustering that effectively bridges critical gaps in existing methods, including long-range dependency, feature collapse, and information loss. Traditional methods often struggle to capture high-order graph features due to their reliance on low-order attribute information, while contrastive learning techniques face limitations in feature diversity by overemphasizing local neighborhood structures. Similarly, conventional graph coarsening methods, though reducing graph scale, frequently lose fine-grained structural details. MPCCL addresses these challenges through an innovative multi-scale coarsening strategy, which progressively condenses the graph while prioritizing the merging of key edges based on global node similarity to preserve essential structural information. It further introduces a one-to-many contrastive learning paradigm, integrating node embeddings with augmented graph views and cluster centroids to enhance feature diversity, while mitigating feature masking issues caused by the accumulation of high-frequency node weights during multi-scale coarsening. By incorporating a graph reconstruction loss and KL divergence into its self-supervised learning framework, MPCCL ensures cross-scale consistency of node representations. Experimental evaluations reveal that MPCCL achieves a significant improvement in clustering performance, including a remarkable 15.24% increase in NMI on the ACM dataset and notable robust gains on smaller-scale datasets such as Citeseer, Cora and DBLP.
* The source code for this study is available at https://github.com/YF-W/MPCCL
Ensembling Prioritized Hybrid Policies for Multi-agent Pathfinding
Mar 12, 2024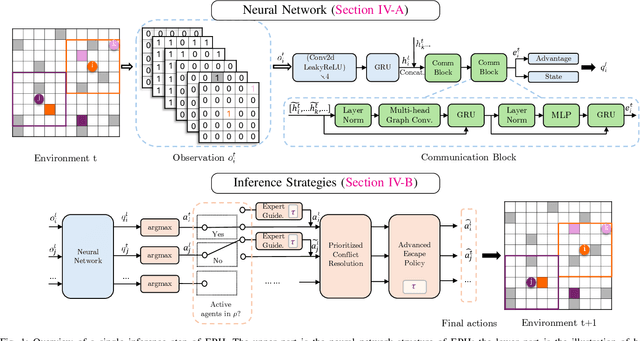



Multi-Agent Reinforcement Learning (MARL) based Multi-Agent Path Finding (MAPF) has recently gained attention due to its efficiency and scalability. Several MARL-MAPF methods choose to use communication to enrich the information one agent can perceive. However, existing works still struggle in structured environments with high obstacle density and a high number of agents. To further improve the performance of the communication-based MARL-MAPF solvers, we propose a new method, Ensembling Prioritized Hybrid Policies (EPH). We first propose a selective communication block to gather richer information for better agent coordination within multi-agent environments and train the model with a Q-learning-based algorithm. We further introduce three advanced inference strategies aimed at bolstering performance during the execution phase. First, we hybridize the neural policy with single-agent expert guidance for navigating conflict-free zones. Secondly, we propose Q value-based methods for prioritized resolution of conflicts as well as deadlock situations. Finally, we introduce a robust ensemble method that can efficiently collect the best out of multiple possible solutions. We empirically evaluate EPH in complex multi-agent environments and demonstrate competitive performance against state-of-the-art neural methods for MAPF.
HiMAP: Learning Heuristics-Informed Policies for Large-Scale Multi-Agent Pathfinding
Feb 23, 2024
Large-scale multi-agent pathfinding (MAPF) presents significant challenges in several areas. As systems grow in complexity with a multitude of autonomous agents operating simultaneously, efficient and collision-free coordination becomes paramount. Traditional algorithms often fall short in scalability, especially in intricate scenarios. Reinforcement Learning (RL) has shown potential to address the intricacies of MAPF; however, it has also been shown to struggle with scalability, demanding intricate implementation, lengthy training, and often exhibiting unstable convergence, limiting its practical application. In this paper, we introduce Heuristics-Informed Multi-Agent Pathfinding (HiMAP), a novel scalable approach that employs imitation learning with heuristic guidance in a decentralized manner. We train on small-scale instances using a heuristic policy as a teacher that maps each single agent observation information to an action probability distribution. During pathfinding, we adopt several inference techniques to improve performance. With a simple training scheme and implementation, HiMAP demonstrates competitive results in terms of success rate and scalability in the field of imitation-learning-only MAPF, showing the potential of imitation-learning-only MAPF equipped with inference techniques.
Explaining How a Neural Network Play the Go Game and Let People Learn
Oct 15, 2023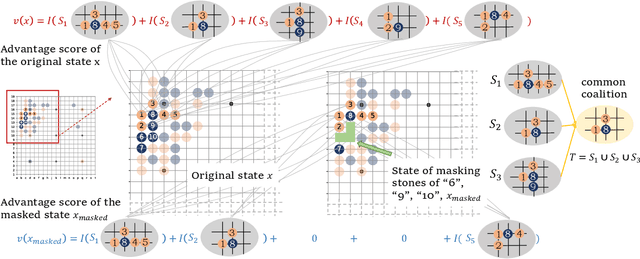

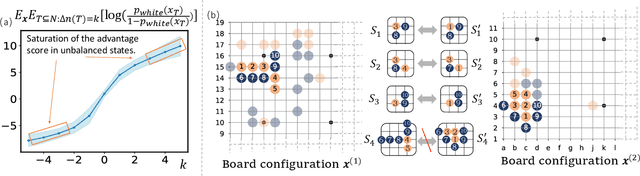
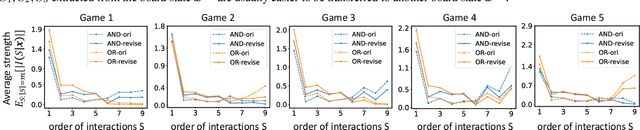
The AI model has surpassed human players in the game of Go, and it is widely believed that the AI model has encoded new knowledge about the Go game beyond human players. In this way, explaining the knowledge encoded by the AI model and using it to teach human players represent a promising-yet-challenging issue in explainable AI. To this end, mathematical supports are required to ensure that human players can learn accurate and verifiable knowledge, rather than specious intuitive analysis. Thus, in this paper, we extract interaction primitives between stones encoded by the value network for the Go game, so as to enable people to learn from the value network. Experiments show the effectiveness of our method.