 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling Participation in Modular AI Systems
Jun 05, 2026Humanity is a mosaic of multifaceted talents and needs, and any truly intelligent AI must reflect that richness. Yet the LLMs used by all are built by the few -- a centralized market of monolithic AI models structurally ill-suited to capture the diversity of human knowledge, reasoning, and values. Here we introduce scaling participation, a new paradigm in which modular AI systems are built from the bottom up through the contributions of diverse stakeholders. Participants contribute small models trained on their own interests and priorities; these models then collaborate in modular frameworks as compositional AI systems. Participatory AI systems outperform monolithic LLMs by up to 15.4% across 15 tasks, such as reasoning and factuality, surpassing models larger than all contributed components combined. Further experiments show that participatory AI systems benefit from contributor diversity, substantially improve on each contributor's original priorities, and exhibit emergent capabilities that allow them to solve over 15% of problems where all individual models fail. Scaling participation provides a technical foundation for transitioning from the monolithic status quo toward an open, bottom-up, and collaborative AI future.
Small Reward Models via Backward Inference
Feb 14, 2026Reward models (RMs) play a central role throughout the language model (LM) pipeline, particularly in non-verifiable domains. However, the dominant LLM-as-a-Judge paradigm relies on the strong reasoning capabilities of large models, while alternative approaches require reference responses or explicit rubrics, limiting flexibility and broader accessibility. In this work, we propose FLIP (FLipped Inference for Prompt reconstruction), a reference-free and rubric-free reward modeling approach that reformulates reward modeling through backward inference: inferring the instruction that would most plausibly produce a given response. The similarity between the inferred and the original instructions is then used as the reward signal. Evaluations across four domains using 13 small language models show that FLIP outperforms LLM-as-a-Judge baselines by an average of 79.6%. Moreover, FLIP substantially improves downstream performance in extrinsic evaluations under test-time scaling via parallel sampling and GRPO training. We further find that FLIP is particularly effective for longer outputs and robust to common forms of reward hacking. By explicitly exploiting the validation-generation gap, FLIP enables reliable reward modeling in downscaled regimes where judgment methods fail. Code available at https://github.com/yikee/FLIP.
MentorCollab: Selective Large-to-Small Inference-Time Guidance for Efficient Reasoning
Feb 05, 2026Large reasoning models (LRMs) achieve strong performance by producing long chains of thought, but their inference costs are high and often generate redundant reasoning. Small language models (SLMs) are far more efficient, yet struggle on multi-step reasoning tasks. A natural idea is to let a large model guide a small one at inference time as a mentor, yet existing collaboration methods often promote imitation, resulting in verbose reasoning without consistent error correction. We propose MentorCollab, an inference-time collaboration method in which an LRM selectively and sparsely guides an SLM, rather than taking over generation. At randomly sampled token positions, we probe for divergences between the two models and use a lightweight verifier to decide whether the SLM should follow a short lookahead segment from its mentor or continue on its own. Across 15 SLM--LRM pairs and 3 domains (math reasoning, general knowledge, and commonsense reasoning), our method improves performance in 12 settings, with average gains of 3.0% and up to 8.0%, while adopting only having 18.4% tokens generated by the expensive mentor model on average. We find that short segments and selective probing are sufficient for effective collaboration. Our results show that selective inference-time guidance restores large-model reasoning ability without substantial inference overhead.
The Single-Multi Evolution Loop for Self-Improving Model Collaboration Systems
Feb 05, 2026Model collaboration -- systems where multiple language models (LMs) collaborate -- combines the strengths of diverse models with cost in loading multiple LMs. We improve efficiency while preserving the strengths of collaboration by distilling collaborative patterns into a single model, where the model is trained on the outputs of the model collaboration system. At inference time, only the distilled model is employed: it imitates the collaboration while only incurring the cost of a single model. Furthermore, we propose the single-multi evolution loop: multiple LMs collaborate, each distills from the collaborative outputs, and these post-distillation improved LMs collaborate again, forming a collective evolution ecosystem where models evolve and self-improve by interacting with an environment of other models. Extensive experiments with 7 collaboration strategies and 15 tasks (QA, reasoning, factuality, etc.) demonstrate that: 1) individual models improve by 8.0% on average, absorbing the strengths of collaboration while reducing the cost to a single model; 2) the collaboration also benefits from the stronger and more synergistic LMs after distillation, improving over initial systems without evolution by 14.9% on average. Analysis reveals that the single-multi evolution loop outperforms various existing evolutionary AI methods, is compatible with diverse model/collaboration/distillation settings, and helps solve problems where the initial model/system struggles to.
Among Us: Measuring and Mitigating Malicious Contributions in Model Collaboration Systems
Feb 05, 2026Language models (LMs) are increasingly used in collaboration: multiple LMs trained by different parties collaborate through routing systems, multi-agent debate, model merging, and more. Critical safety risks remain in this decentralized paradigm: what if some of the models in multi-LLM systems are compromised or malicious? We first quantify the impact of malicious models by engineering four categories of malicious LMs, plug them into four types of popular model collaboration systems, and evaluate the compromised system across 10 datasets. We find that malicious models have a severe impact on the multi-LLM systems, especially for reasoning and safety domains where performance is lowered by 7.12% and 7.94% on average. We then propose mitigation strategies to alleviate the impact of malicious components, by employing external supervisors that oversee model collaboration to disable/mask them out to reduce their influence. On average, these strategies recover 95.31% of the initial performance, while making model collaboration systems fully resistant to malicious models remains an open research question.
MoCo: A One-Stop Shop for Model Collaboration Research
Jan 29, 2026Advancing beyond single monolithic language models (LMs), recent research increasingly recognizes the importance of model collaboration, where multiple LMs collaborate, compose, and complement each other. Existing research on this topic has mostly been disparate and disconnected, from different research communities, and lacks rigorous comparison. To consolidate existing research and establish model collaboration as a school of thought, we present MoCo: a one-stop Python library of executing, benchmarking, and comparing model collaboration algorithms at scale. MoCo features 26 model collaboration methods, spanning diverse levels of cross-model information exchange such as routing, text, logit, and model parameters. MoCo integrates 25 evaluation datasets spanning reasoning, QA, code, safety, and more, while users could flexibly bring their own data. Extensive experiments with MoCo demonstrate that most collaboration strategies outperform models without collaboration in 61.0% of (model, data) settings on average, with the most effective methods outperforming by up to 25.8%. We further analyze the scaling of model collaboration strategies, the training/inference efficiency of diverse methods, highlight that the collaborative system solves problems where single LMs struggle, and discuss future work in model collaboration, all made possible by MoCo. We envision MoCo as a valuable toolkit to facilitate and turbocharge the quest for an open, modular, decentralized, and collaborative AI future.
SPARTA ALIGNMENT: Collectively Aligning Multiple Language Models through Combat
Jun 05, 2025We propose SPARTA ALIGNMENT, an algorithm to collectively align multiple LLMs through competition and combat. To complement a single model's lack of diversity in generation and biases in evaluation, multiple LLMs form a "sparta tribe" to compete against each other in fulfilling instructions while serving as judges for the competition of others. For each iteration, one instruction and two models are selected for a duel, the other models evaluate the two responses, and their evaluation scores are aggregated through a adapted elo-ranking based reputation system, where winners/losers of combat gain/lose weight in evaluating others. The peer-evaluated combat results then become preference pairs where the winning response is preferred over the losing one, and all models learn from these preferences at the end of each iteration. SPARTA ALIGNMENT enables the self-evolution of multiple LLMs in an iterative and collective competition process. Extensive experiments demonstrate that SPARTA ALIGNMENT outperforms initial models and 4 self-alignment baselines across 10 out of 12 tasks and datasets with 7.0% average improvement. Further analysis reveals that SPARTA ALIGNMENT generalizes more effectively to unseen tasks and leverages the expertise diversity of participating models to produce more logical, direct and informative outputs.
ScienceMeter: Tracking Scientific Knowledge Updates in Language Models
May 30, 2025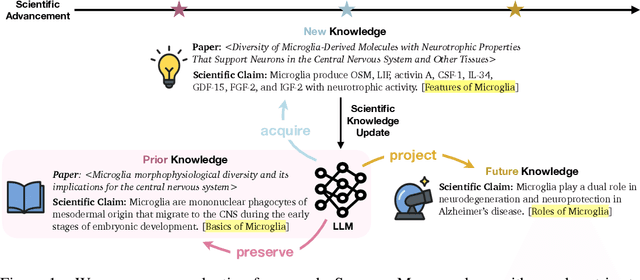
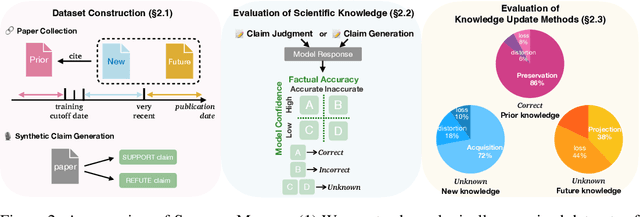
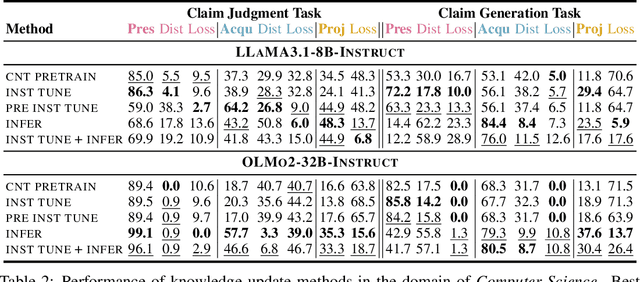
Large Language Models (LLMs) are increasingly used to support scientific research, but their knowledge of scientific advancements can quickly become outdated. We introduce ScienceMeter, a new framework for evaluating scientific knowledge update methods over scientific knowledge spanning the past, present, and future. ScienceMeter defines three metrics: knowledge preservation, the extent to which models' understanding of previously learned papers are preserved; knowledge acquisition, how well scientific claims from newly introduced papers are acquired; and knowledge projection, the ability of the updated model to anticipate or generalize to related scientific claims that may emerge in the future. Using ScienceMeter, we examine the scientific knowledge of LLMs on claim judgment and generation tasks across a curated dataset of 15,444 scientific papers and 30,888 scientific claims from ten domains including medicine, biology, materials science, and computer science. We evaluate five representative knowledge update approaches including training- and inference-time methods. With extensive experiments, we find that the best-performing knowledge update methods can preserve only 85.9% of existing knowledge, acquire 71.7% of new knowledge, and project 37.7% of future knowledge. Inference-based methods work for larger models, whereas smaller models require training to achieve comparable performance. Cross-domain analysis reveals that performance on these objectives is correlated. Even when applying on specialized scientific LLMs, existing knowledge update methods fail to achieve these objectives collectively, underscoring that developing robust scientific knowledge update mechanisms is both crucial and challenging.
MMMG: a Comprehensive and Reliable Evaluation Suite for Multitask Multimodal Generation
May 23, 2025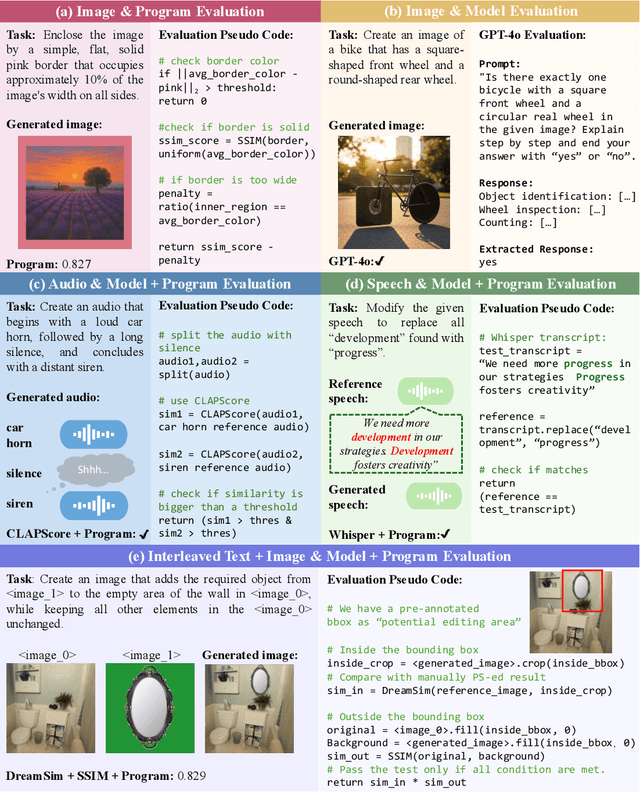
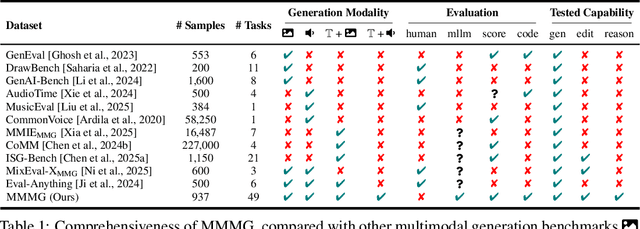
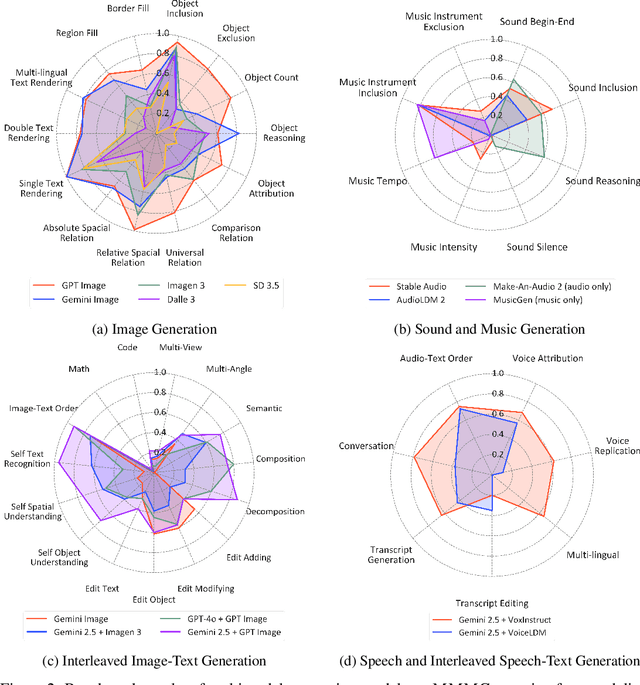
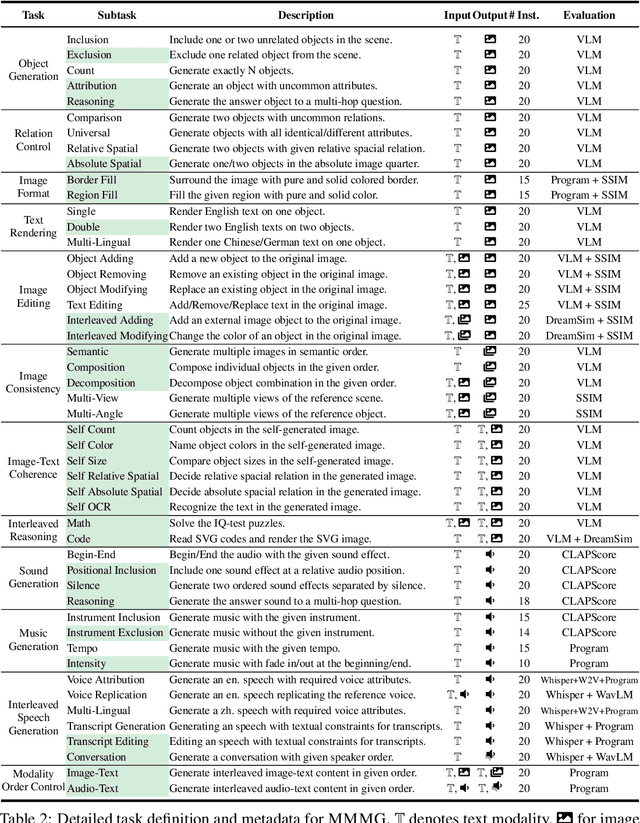
Automatically evaluating multimodal generation presents a significant challenge, as automated metrics often struggle to align reliably with human evaluation, especially for complex tasks that involve multiple modalities. To address this, we present MMMG, a comprehensive and human-aligned benchmark for multimodal generation across 4 modality combinations (image, audio, interleaved text and image, interleaved text and audio), with a focus on tasks that present significant challenges for generation models, while still enabling reliable automatic evaluation through a combination of models and programs. MMMG encompasses 49 tasks (including 29 newly developed ones), each with a carefully designed evaluation pipeline, and 937 instructions to systematically assess reasoning, controllability, and other key capabilities of multimodal generation models. Extensive validation demonstrates that MMMG is highly aligned with human evaluation, achieving an average agreement of 94.3%. Benchmarking results on 24 multimodal generation models reveal that even though the state-of-the-art model, GPT Image, achieves 78.3% accuracy for image generation, it falls short on multimodal reasoning and interleaved generation. Furthermore, results suggest considerable headroom for improvement in audio generation, highlighting an important direction for future research.
Bidirectional LMs are Better Knowledge Memorizers? A Benchmark for Real-world Knowledge Injection
May 18, 2025Despite significant advances in large language models (LLMs), their knowledge memorization capabilities remain underexplored, due to the lack of standardized and high-quality test ground. In this paper, we introduce a novel, real-world and large-scale knowledge injection benchmark that evolves continuously over time without requiring human intervention. Specifically, we propose WikiDYK, which leverages recently-added and human-written facts from Wikipedia's "Did You Know..." entries. These entries are carefully selected by expert Wikipedia editors based on criteria such as verifiability and clarity. Each entry is converted into multiple question-answer pairs spanning diverse task formats from easy cloze prompts to complex multi-hop questions. WikiDYK contains 12,290 facts and 77,180 questions, which is also seamlessly extensible with future updates from Wikipedia editors. Extensive experiments using continued pre-training reveal a surprising insight: despite their prevalence in modern LLMs, Causal Language Models (CLMs) demonstrate significantly weaker knowledge memorization capabilities compared to Bidirectional Language Models (BiLMs), exhibiting a 23% lower accuracy in terms of reliability. To compensate for the smaller scales of current BiLMs, we introduce a modular collaborative framework utilizing ensembles of BiLMs as external knowledge repositories to integrate with LLMs. Experiment shows that our framework further improves the reliability accuracy by up to 29.1%.