 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFAIR^2 Drones: An AI-Ready Standard for Cross-Domain Wildlife Drone Datasets
May 29, 2026Animal ecology data collection using drones represents a substantial investment of time, expertise, and financial resources. Yet most existing datasets serve only a single research community, limiting interdisciplinary reuse. We propose a unified drone dataset standard, FAIR^2 Drones, that bridges ecology, robotics, and computer vision by building on existing FAIR and AI-ready data frameworks while adding essential platform metadata and annotation specifications. Our standard enables datasets to simultaneously support ecological analysis, robotics algorithm development, and computer vision benchmarking. We provide open-source validation tools, reference implementations, and multimodal extensions linking drone imagery with complementary sensors such as camera traps, GPS, and acoustics. By standardizing metadata across disciplines, this framework maximizes the scientific return on investment for costly field deployments and accelerates cross-domain collaboration in environmental monitoring.
MMLA: Multi-Environment, Multi-Species, Low-Altitude Aerial Footage Dataset
Apr 10, 2025Real-time wildlife detection in drone imagery is critical for numerous applications, including animal ecology, conservation, and biodiversity monitoring. Low-altitude drone missions are effective for collecting fine-grained animal movement and behavior data, particularly if missions are automated for increased speed and consistency. However, little work exists on evaluating computer vision models on low-altitude aerial imagery and generalizability across different species and settings. To fill this gap, we present a novel multi-environment, multi-species, low-altitude aerial footage (MMLA) dataset. MMLA consists of drone footage collected across three diverse environments: Ol Pejeta Conservancy and Mpala Research Centre in Kenya, and The Wilds Conservation Center in Ohio, which includes five species: Plains zebras, Grevy's zebras, giraffes, onagers, and African Painted Dogs. We comprehensively evaluate three YOLO models (YOLOv5m, YOLOv8m, and YOLOv11m) for detecting animals. Results demonstrate significant performance disparities across locations and species-specific detection variations. Our work highlights the importance of evaluating detection algorithms across different environments for robust wildlife monitoring applications using drones.
Safe Reinforcement Learning with Minimal Supervision
Jan 08, 2025Reinforcement learning (RL) in the real world necessitates the development of procedures that enable agents to explore without causing harm to themselves or others. The most successful solutions to the problem of safe RL leverage offline data to learn a safe-set, enabling safe online exploration. However, this approach to safe-learning is often constrained by the demonstrations that are available for learning. In this paper we investigate the influence of the quantity and quality of data used to train the initial safe learning problem offline on the ability to learn safe-RL policies online. Specifically, we focus on tasks with spatially extended goal states where we have few or no demonstrations available. Classically this problem is addressed either by using hand-designed controllers to generate data or by collecting user-generated demonstrations. However, these methods are often expensive and do not scale to more complex tasks and environments. To address this limitation we propose an unsupervised RL-based offline data collection procedure, to learn complex and scalable policies without the need for hand-designed controllers or user demonstrations. Our research demonstrates the significance of providing sufficient demonstrations for agents to learn optimal safe-RL policies online, and as a result, we propose optimistic forgetting, a novel online safe-RL approach that is practical for scenarios with limited data. Further, our unsupervised data collection approach highlights the need to balance diversity and optimality for safe online exploration.
Biased AI can Influence Political Decision-Making
Oct 08, 2024
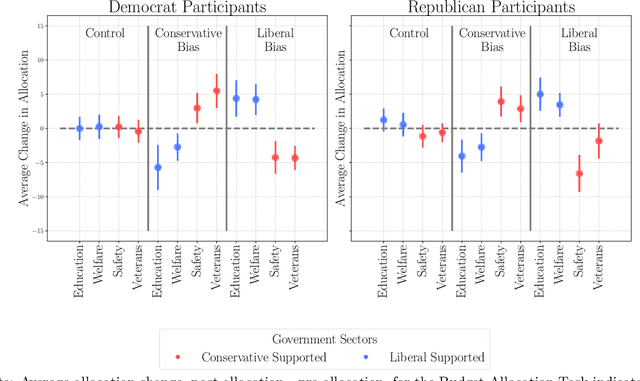

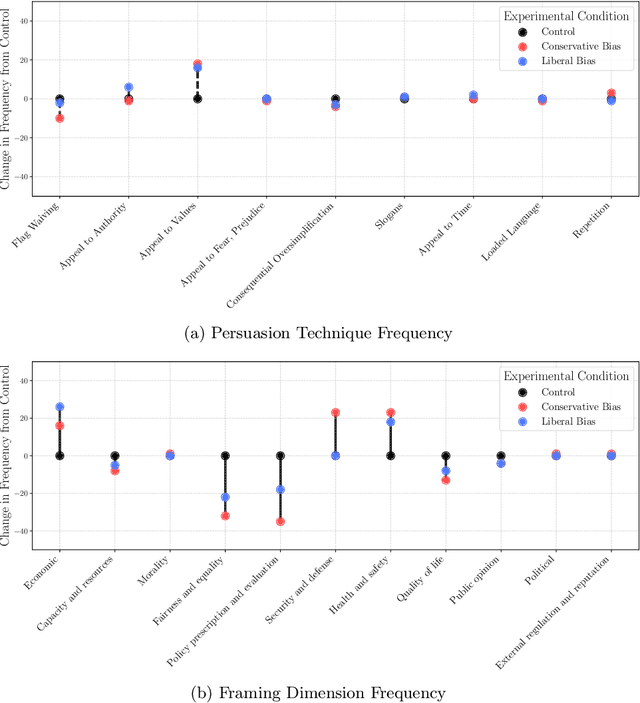
As modern AI models become integral to everyday tasks, concerns about their inherent biases and their potential impact on human decision-making have emerged. While bias in models are well-documented, less is known about how these biases influence human decisions. This paper presents two interactive experiments investigating the effects of partisan bias in AI language models on political decision-making. Participants interacted freely with either a biased liberal, conservative, or unbiased control model while completing political decision-making tasks. We found that participants exposed to politically biased models were significantly more likely to adopt opinions and make decisions aligning with the AI's bias, regardless of their personal political partisanship. However, we also discovered that prior knowledge about AI could lessen the impact of the bias, highlighting the possible importance of AI education for robust bias mitigation. Our findings not only highlight the critical effects of interacting with biased AI and its ability to impact public discourse and political conduct, but also highlights potential techniques for mitigating these risks in the future.
Improved prediction of future user activity in online A/B testing
Feb 05, 2024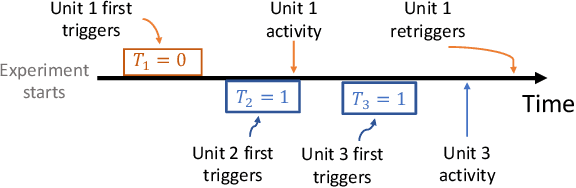

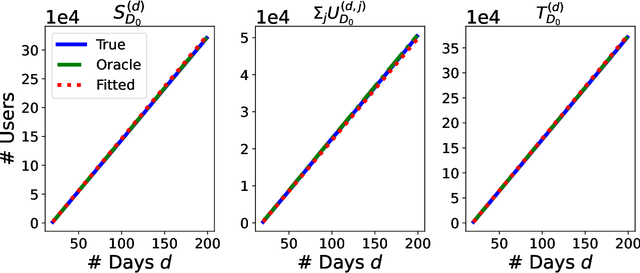
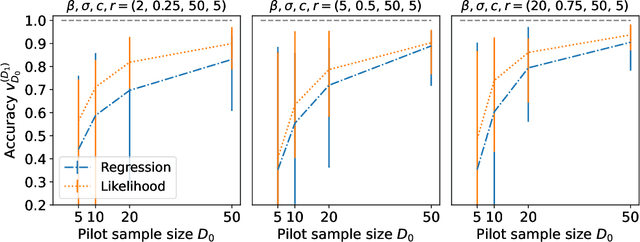
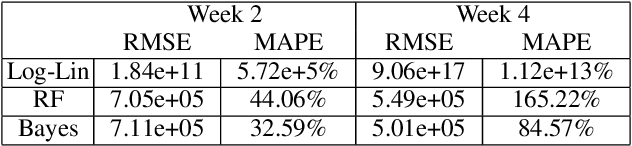
In online randomized experiments or A/B tests, accurate predictions of participant inclusion rates are of paramount importance. These predictions not only guide experimenters in optimizing the experiment's duration but also enhance the precision of treatment effect estimates. In this paper we present a novel, straightforward, and scalable Bayesian nonparametric approach for predicting the rate at which individuals will be exposed to interventions within the realm of online A/B testing. Our approach stands out by offering dual prediction capabilities: it forecasts both the quantity of new customers expected in future time windows and, unlike available alternative methods, the number of times they will be observed. We derive closed-form expressions for the posterior distributions of the quantities needed to form predictions about future user activity, thereby bypassing the need for numerical algorithms such as Markov chain Monte Carlo. After a comprehensive exposition of our model, we test its performance on experiments on real and simulated data, where we show its superior performance with respect to existing alternatives in the literature.
Quad2Plane: An Intermediate Training Procedure for Online Exploration in Aerial Robotics via Receding Horizon Control
Mar 21, 2022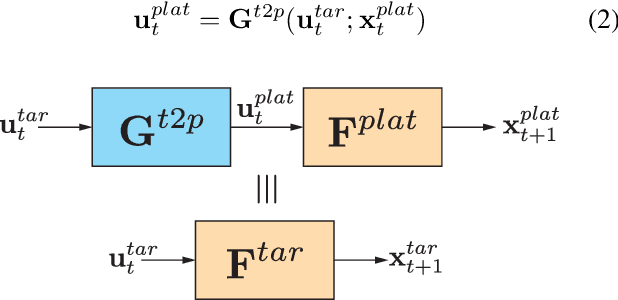
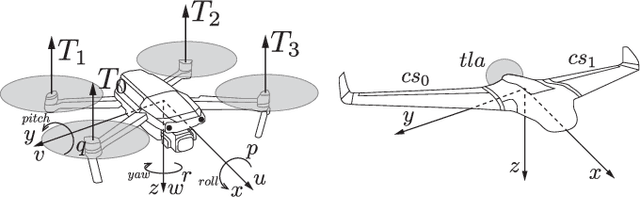
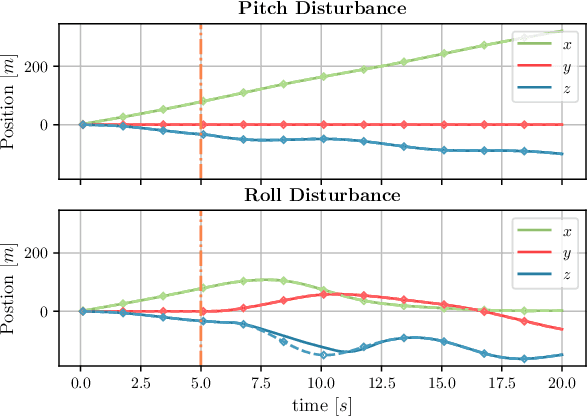
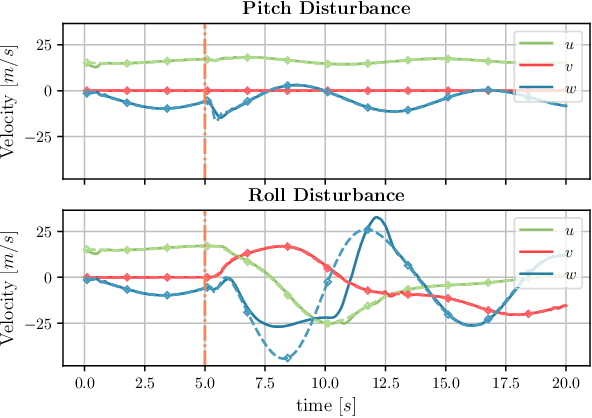
Data driven robotics relies upon accurate real-world representations to learn useful policies. Despite our best-efforts, zero-shot sim-to-real transfer is still an unsolved problem, and we often need to allow our agents to explore online to learn useful policies for a given task. For many applications of field robotics online exploration is prohibitively expensive and dangerous, this is especially true in fixed-wing aerial robotics. To address these challenges we offer an intermediary solution for learning in field robotics. We investigate the use of dissimilar platform vehicle for learning and offer a procedure to mimic the behavior of one vehicle with another. We specifically consider the problem of training fixed-wing aircraft, an expensive and dangerous vehicle type, using a multi-rotor host platform. Using a Model Predictive Control approach, we design a controller capable of mimicking another vehicles behavior in both simulation and the real-world.
Bayesian Sample Size Prediction for Online Activity
Nov 23, 2021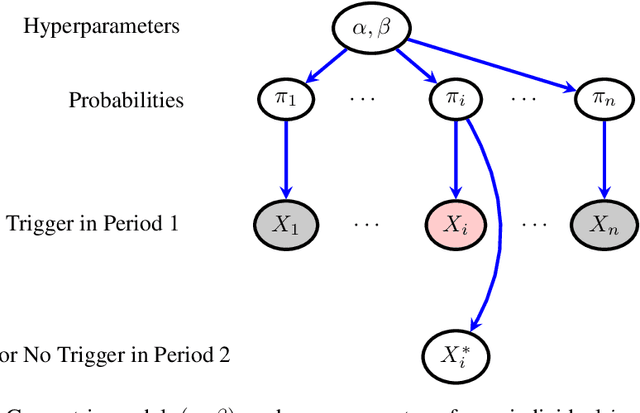
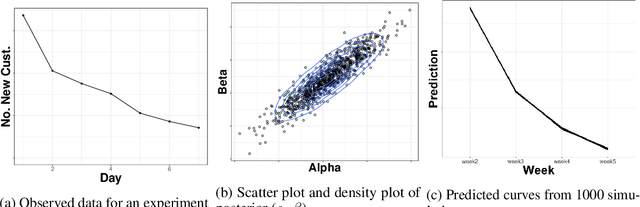
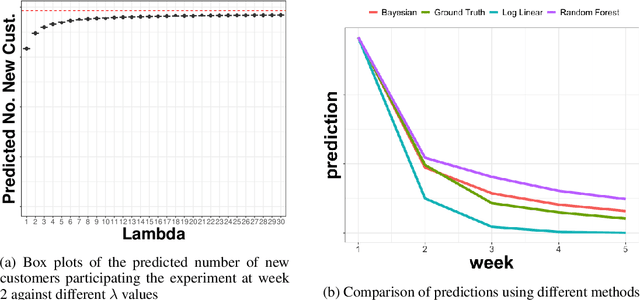
In many contexts it is useful to predict the number of individuals in some population who will initiate a particular activity during a given period. For example, the number of users who will install a software update, the number of customers who will use a new feature on a website or who will participate in an A/B test. In practical settings, there is heterogeneity amongst individuals with regard to the distribution of time until they will initiate. For these reasons it is inappropriate to assume that the number of new individuals observed on successive days will be identically distributed. Given observations on the number of unique users participating in an initial period, we present a simple but novel Bayesian method for predicting the number of additional individuals who will subsequently participate during a subsequent period. We illustrate the performance of the method in predicting sample size in online experimentation.
Distributed storage algorithms with optimal tradeoffs
Jan 13, 2021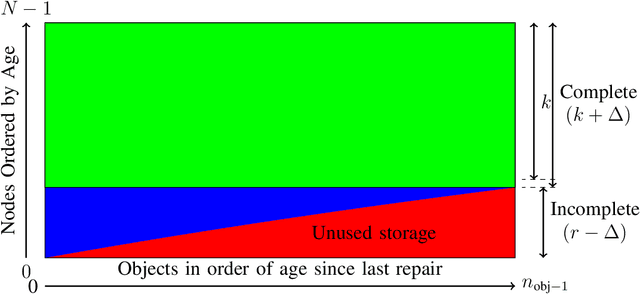
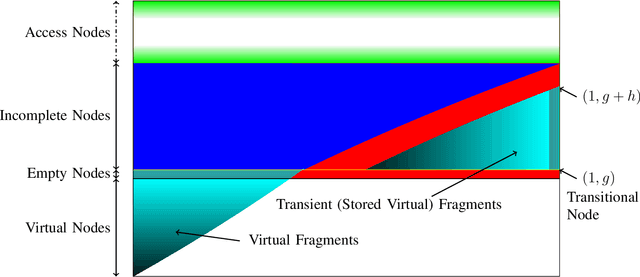
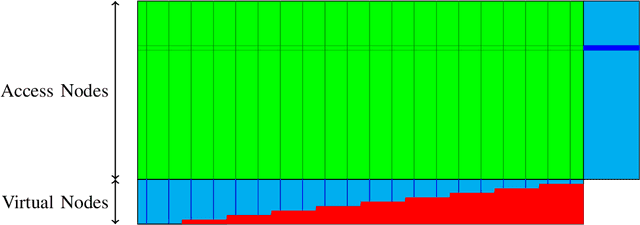
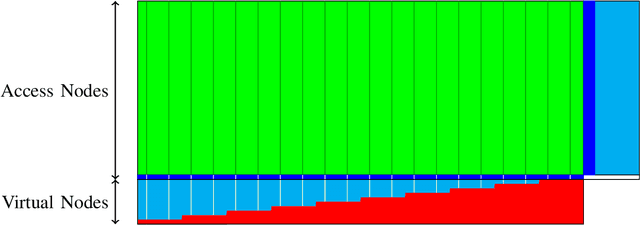
One of the primary objectives of a distributed storage system is to reliably store large amounts of source data for long durations using a large number $N$ of unreliable storage nodes, each with $c$ bits of storage capacity. Storage nodes fail randomly over time and are replaced with nodes of equal capacity initialized to zeroes, and thus bits are erased at some rate $e$. To maintain recoverability of the source data, a repairer continually reads data over a network from nodes at an average rate $r$, and generates and writes data to nodes based on the read data. The distributed storage source capacity is the maximum amount of source that can be reliably stored for long periods of time. Previous research shows that asymptotically the distributed storage source capacity is at most $\left(1-\frac{e}{2 \cdot r}\right) \cdot N \cdot c$ as $N$ and $r$ grow. In this work we introduce and analyze algorithms such that asymptotically the distributed storage source data capacity is at least the above equation. Thus, the above equation expresses a fundamental trade-off between network traffic and storage overhead to reliably store source data.
Agile Reactive Navigation for A Non-Holonomic Mobile Robot Using A Pixel Processor Array
Sep 27, 2020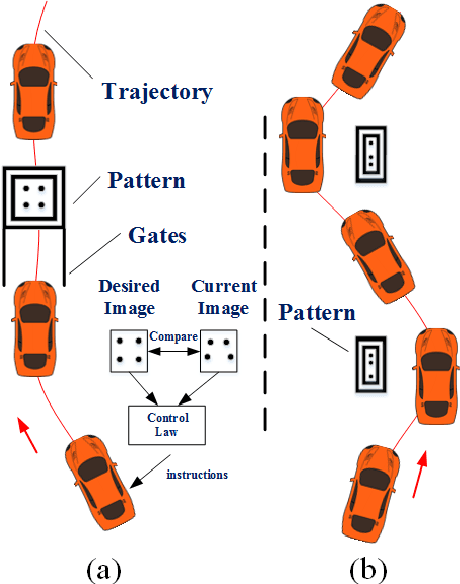

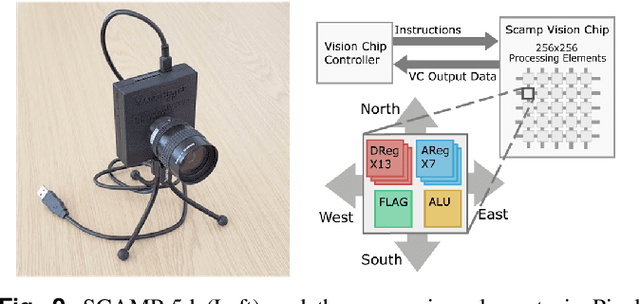
This paper presents an agile reactive navigation strategy for driving a non-holonomic ground vehicle around a preset course of gates in a cluttered environment using a low-cost processor array sensor. This enables machine vision tasks to be performed directly upon the sensor's image plane, rather than using a separate general-purpose computer. We demonstrate a small ground vehicle running through or avoiding multiple gates at high speed using minimal computational resources. To achieve this, target tracking algorithms are developed for the Pixel Processing Array and captured images are then processed directly on the vision sensor acquiring target information for controlling the ground vehicle. The algorithm can run at up to 2000 fps outdoors and 200fps at indoor illumination levels. Conducting image processing at the sensor level avoids the bottleneck of image transfer encountered in conventional sensors. The real-time performance of on-board image processing and robustness is validated through experiments. Experimental results demonstrate that the algorithm's ability to enable a ground vehicle to navigate at an average speed of 2.20 m/s for passing through multiple gates and 3.88 m/s for a 'slalom' task in an environment featuring significant visual clutter.
Towards An Adaptive Compliant Aerial Manipulator for Contact-Based Interaction
Nov 29, 2017
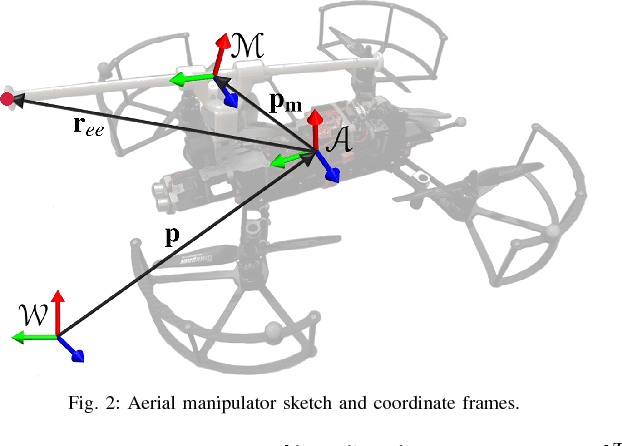

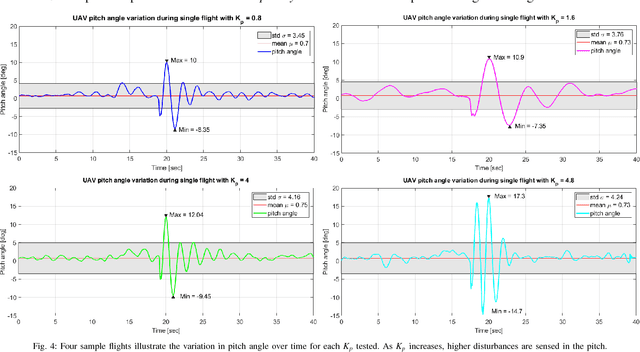
As roles for unmanned aerial vehicles (UAV) continue to diversify, the ability to sense and interact closely with the environment becomes increasingly important. Within this paper we report on the initial flight tests of a novel adaptive compliant actuator which will allow a UAV to carry out such tasks as the "pick and placement" of remote sensors, structural testing and contact-based inspection. Three key results are discussed and presented; the ability to physically compensate impact forces or apply interaction forces by the UAV through the use of the active compliant manipulator; to be able to tailor these forces through tuning of the manipulator controller gains; and the ability to apply a rapid series of physical pulses in order to excite remotely placed sensors, e.g. vibration sensors. The paper describes the overall system requirements and system modelling considerations which have driven the concept through to flight testing. A series of over sixty flight tests have been used to generate initial results which clearly demonstrate the potential of this new type of compliant aerial actuator. Results are discussed in line with potential applications; and a series of future flight tests are described which will enable us to refine and characterise the overall system.