 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Scale Distributed Acoustic Modeling With Back-off N-grams
Paper and Code
Feb 05, 2013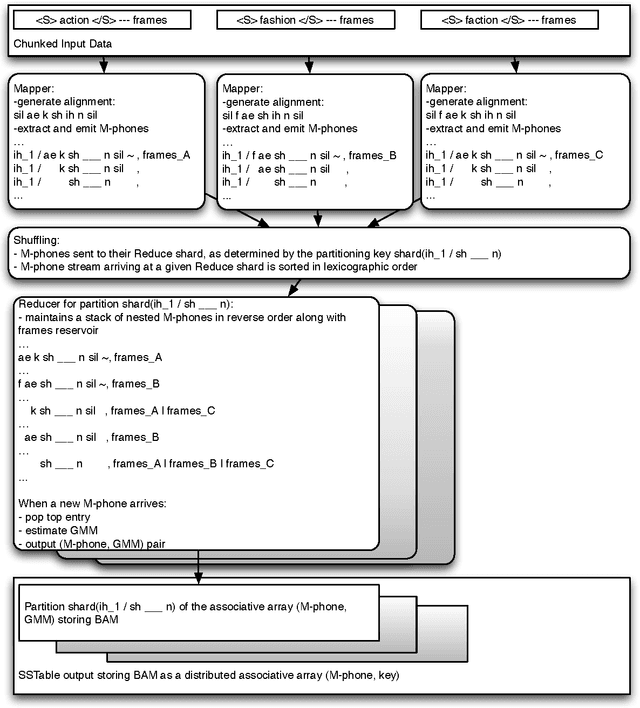
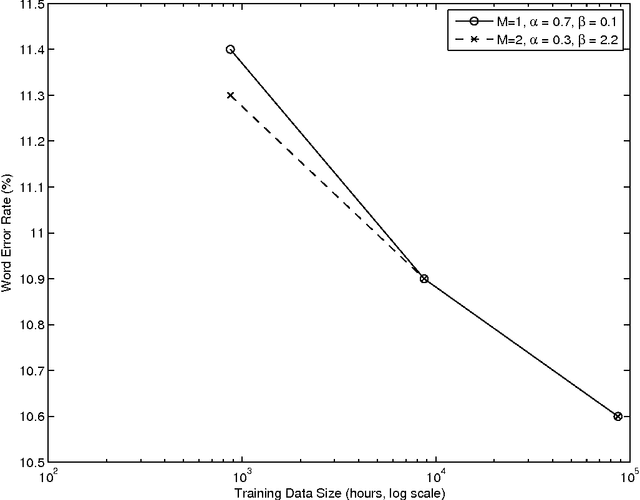
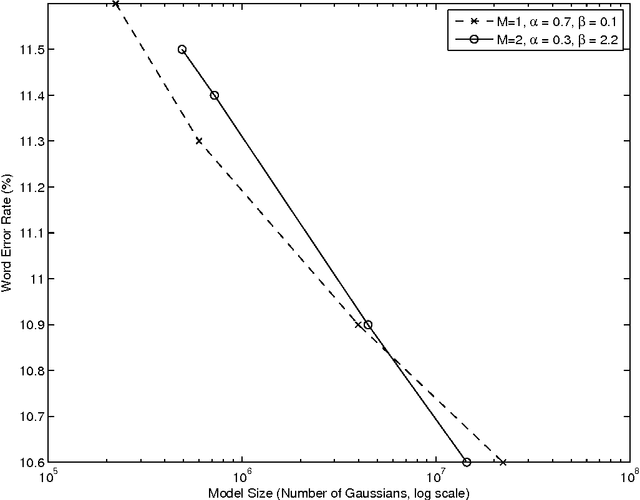
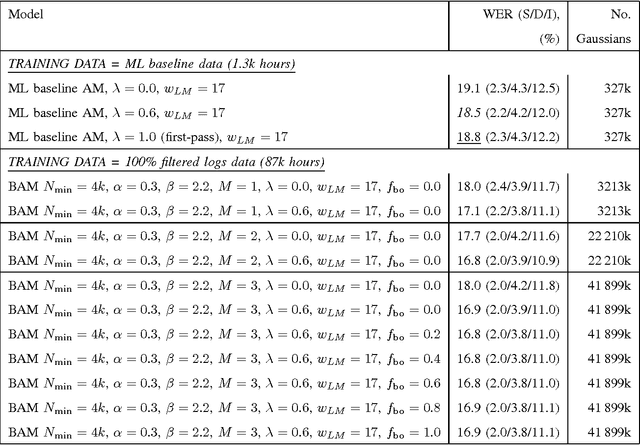
The paper revives an older approach to acoustic modeling that borrows from n-gram language modeling in an attempt to scale up both the amount of training data and model size (as measured by the number of parameters in the model), to approximately 100 times larger than current sizes used in automatic speech recognition. In such a data-rich setting, we can expand the phonetic context significantly beyond triphones, as well as increase the number of Gaussian mixture components for the context-dependent states that allow it. We have experimented with contexts that span seven or more context-independent phones, and up to 620 mixture components per state. Dealing with unseen phonetic contexts is accomplished using the familiar back-off technique used in language modeling due to implementation simplicity. The back-off acoustic model is estimated, stored and served using MapReduce distributed computing infrastructure. Speech recognition experiments are carried out in an N-best list rescoring framework for Google Voice Search. Training big models on large amounts of data proves to be an effective way to increase the accuracy of a state-of-the-art automatic speech recognition system. We use 87,000 hours of training data (speech along with transcription) obtained by filtering utterances in Voice Search logs on automatic speech recognition confidence. Models ranging in size between 20--40 million Gaussians are estimated using maximum likelihood training. They achieve relative reductions in word-error-rate of 11% and 6% when combined with first-pass models trained using maximum likelihood, and boosted maximum mutual information, respectively. Increasing the context size beyond five phones (quinphones) does not help.