 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoupling Speech Encoders with Downstream Text Models
Jul 24, 2024



We present a modular approach to building cascade speech translation (AST) models that guarantees that the resulting model performs no worse than the 1-best cascade baseline while preserving state-of-the-art speech recognition (ASR) and text translation (MT) performance for a given task. Our novel contribution is the use of an ``exporter'' layer that is trained under L2-loss to ensure a strong match between ASR embeddings and the MT token embeddings for the 1-best sequence. The ``exporter'' output embeddings are fed directly to the MT model in lieu of 1-best token embeddings, thus guaranteeing that the resulting model performs no worse than the 1-best cascade baseline, while allowing back-propagation gradient to flow from the MT model into the ASR components. The matched-embeddings cascade architecture provide a significant improvement over its 1-best counterpart in scenarios where incremental training of the MT model is not an option and yet we seek to improve quality by leveraging (speech, transcription, translated transcription) data provided with the AST task. The gain disappears when the MT model is incrementally trained on the parallel text data available with the AST task. The approach holds promise for other scenarios that seek to couple ASR encoders and immutable text models, such at large language models (LLM).
Lego-Features: Exporting modular encoder features for streaming and deliberation ASR
Mar 31, 2023In end-to-end (E2E) speech recognition models, a representational tight-coupling inevitably emerges between the encoder and the decoder. We build upon recent work that has begun to explore building encoders with modular encoded representations, such that encoders and decoders from different models can be stitched together in a zero-shot manner without further fine-tuning. While previous research only addresses full-context speech models, we explore the problem in a streaming setting as well. Our framework builds on top of existing encoded representations, converting them to modular features, dubbed as Lego-Features, without modifying the pre-trained model. The features remain interchangeable when the model is retrained with distinct initializations. Though sparse, we show that the Lego-Features are powerful when tested with RNN-T or LAS decoders, maintaining high-quality downstream performance. They are also rich enough to represent the first-pass prediction during two-pass deliberation. In this scenario, they outperform the N-best hypotheses, since they do not need to be supplemented with acoustic features to deliver the best results. Moreover, generating the Lego-Features does not require beam search or auto-regressive computation. Overall, they present a modular, powerful and cheap alternative to the standard encoder output, as well as the N-best hypotheses.
Towards Computationally Verifiable Semantic Grounding for Language Models
Nov 16, 2022



The paper presents an approach to semantic grounding of language models (LMs) that conceptualizes the LM as a conditional model generating text given a desired semantic message formalized as a set of entity-relationship triples. It embeds the LM in an auto-encoder by feeding its output to a semantic parser whose output is in the same representation domain as the input message. Compared to a baseline that generates text using greedy search, we demonstrate two techniques that improve the fluency and semantic accuracy of the generated text: The first technique samples multiple candidate text sequences from which the semantic parser chooses. The second trains the language model while keeping the semantic parser frozen to improve the semantic accuracy of the auto-encoder. We carry out experiments on the English WebNLG 3.0 data set, using BLEU to measure the fluency of generated text and standard parsing metrics to measure semantic accuracy. We show that our proposed approaches significantly improve on the greedy search baseline. Human evaluation corroborates the results of the automatic evaluation experiments.
Scaling Laws for Neural Machine Translation
Sep 16, 2021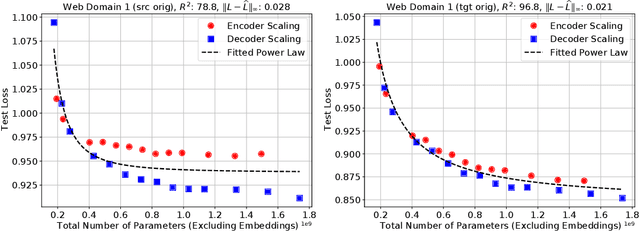
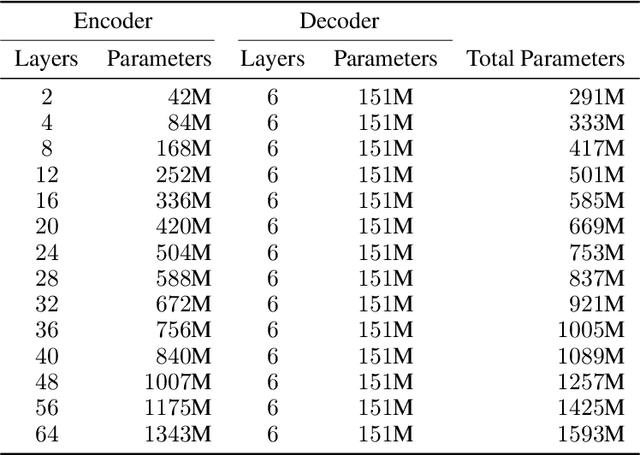
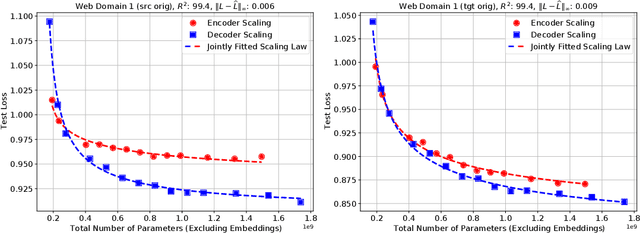
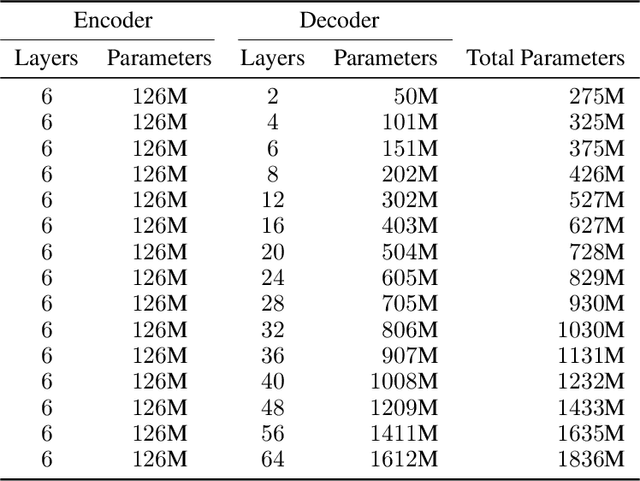
We present an empirical study of scaling properties of encoder-decoder Transformer models used in neural machine translation (NMT). We show that cross-entropy loss as a function of model size follows a certain scaling law. Specifically (i) We propose a formula which describes the scaling behavior of cross-entropy loss as a bivariate function of encoder and decoder size, and show that it gives accurate predictions under a variety of scaling approaches and languages; we show that the total number of parameters alone is not sufficient for such purposes. (ii) We observe different power law exponents when scaling the decoder vs scaling the encoder, and provide recommendations for optimal allocation of encoder/decoder capacity based on this observation. (iii) We also report that the scaling behavior of the model is acutely influenced by composition bias of the train/test sets, which we define as any deviation from naturally generated text (either via machine generated or human translated text). We observe that natural text on the target side enjoys scaling, which manifests as successful reduction of the cross-entropy loss. (iv) Finally, we investigate the relationship between the cross-entropy loss and the quality of the generated translations. We find two different behaviors, depending on the nature of the test data. For test sets which were originally translated from target language to source language, both loss and BLEU score improve as model size increases. In contrast, for test sets originally translated from source language to target language, the loss improves, but the BLEU score stops improving after a certain threshold. We release generated text from all models used in this study.
Data Troubles in Sentence Level Confidence Estimation for Machine Translation
Oct 26, 2020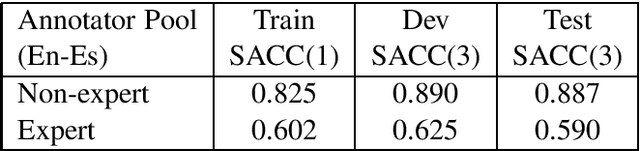
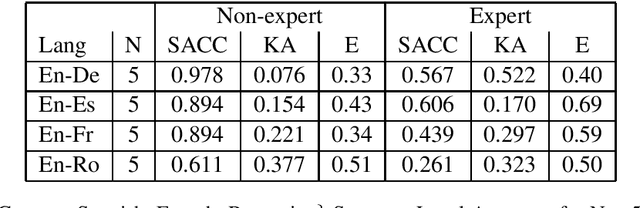
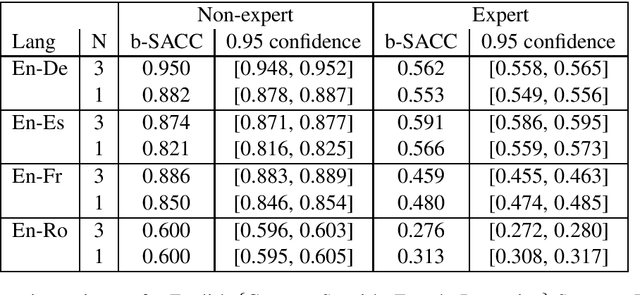
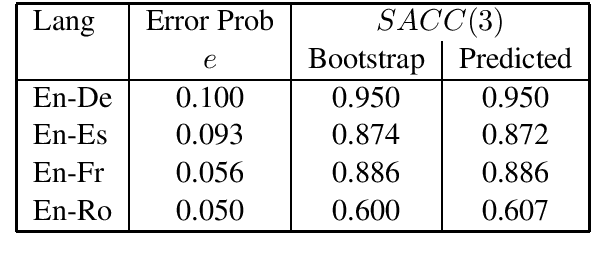
The paper investigates the feasibility of confidence estimation for neural machine translation models operating at the high end of the performance spectrum. As a side product of the data annotation process necessary for building such models we propose sentence level accuracy $SACC$ as a simple, self-explanatory evaluation metric for quality of translation. Experiments on two different annotator pools, one comprised of non-expert (crowd-sourced) and one of expert (professional) translators show that $SACC$ can vary greatly depending on the translation proficiency of the annotators, despite the fact that both pools are about equally reliable according to Krippendorff's alpha metric; the relatively low values of inter-annotator agreement confirm the expectation that sentence-level binary labeling $good$ / $needs\ work$ for translation out of context is very hard. For an English-Spanish translation model operating at $SACC = 0.89$ according to a non-expert annotator pool we can derive a confidence estimate that labels 0.5-0.6 of the $good$ translations in an "in-domain" test set with 0.95 Precision. Switching to an expert annotator pool decreases $SACC$ dramatically: $0.61$ for English-Spanish, measured on the exact same data as above. This forces us to lower the CE model operating point to 0.9 Precision while labeling correctly about 0.20-0.25 of the $good$ translations in the data. We find surprising the extent to which CE depends on the level of proficiency of the annotator pool used for labeling the data. This leads to an important recommendation we wish to make when tackling CE modeling in practice: it is critical to match the end-user expectation for translation quality in the desired domain with the demands of annotators assigning binary quality labels to CE training data.
Multi-Stage Influence Function
Jul 17, 2020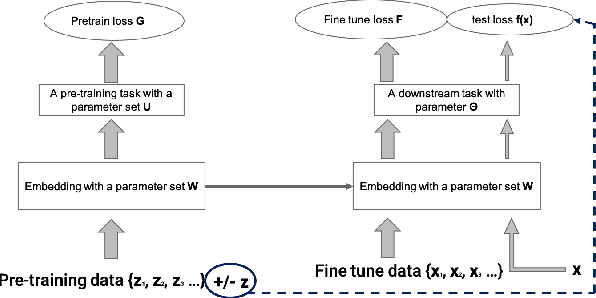
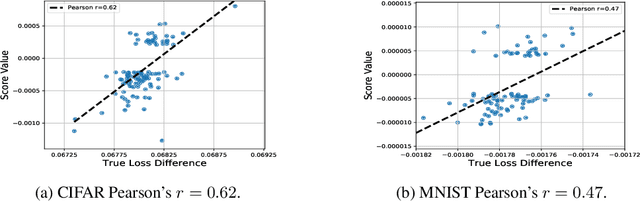

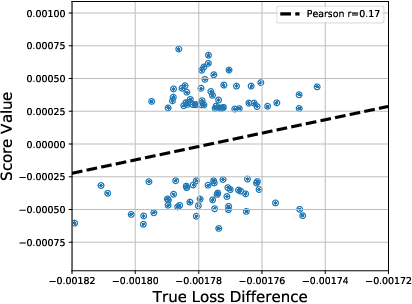
Multi-stage training and knowledge transfer, from a large-scale pretraining task to various finetuning tasks, have revolutionized natural language processing and computer vision resulting in state-of-the-art performance improvements. In this paper, we develop a multi-stage influence function score to track predictions from a finetuned model all the way back to the pretraining data. With this score, we can identify the pretraining examples in the pretraining task that contribute most to a prediction in the finetuning task. The proposed multi-stage influence function generalizes the original influence function for a single model in (Koh & Liang, 2017), thereby enabling influence computation through both pretrained and finetuned models. We study two different scenarios with the pretrained embeddings fixed or updated in the finetuning tasks. We test our proposed method in various experiments to show its effectiveness and potential applications.
Practical Perspectives on Quality Estimation for Machine Translation
May 02, 2020
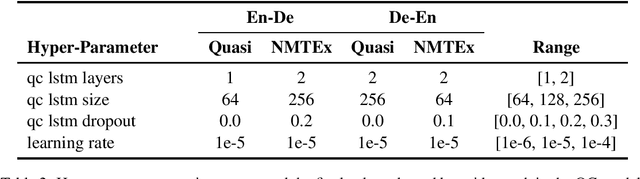
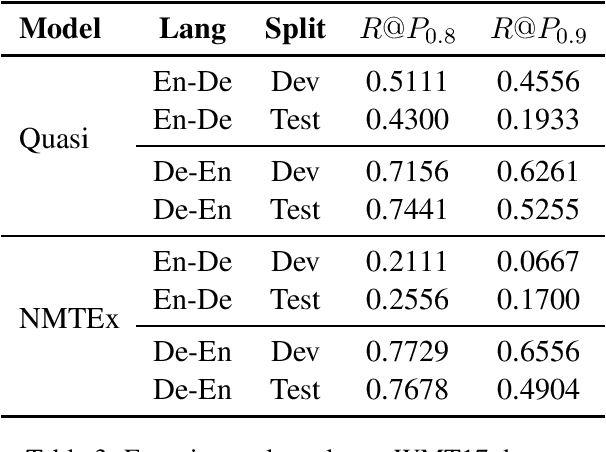
Sentence level quality estimation (QE) for machine translation (MT) attempts to predict the translation edit rate (TER) cost of post-editing work required to correct MT output. We describe our view on sentence-level QE as dictated by several practical setups encountered in the industry. We find consumers of MT output---whether human or algorithmic ones---to be primarily interested in a binary quality metric: is the translated sentence adequate as-is or does it need post-editing? Motivated by this we propose a quality classification (QC) view on sentence-level QE whereby we focus on maximizing recall at precision above a given threshold. We demonstrate that, while classical QE regression models fare poorly on this task, they can be re-purposed by replacing the output regression layer with a binary classification one, achieving 50-60\% recall at 90\% precision. For a high-quality MT system producing 75-80\% correct translations, this promises a significant reduction in post-editing work indeed.
Faster Transformer Decoding: N-gram Masked Self-Attention
Jan 14, 2020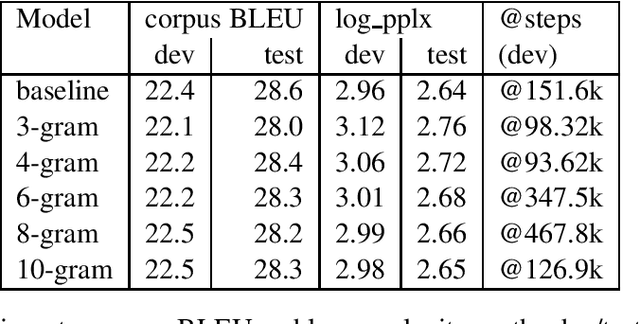
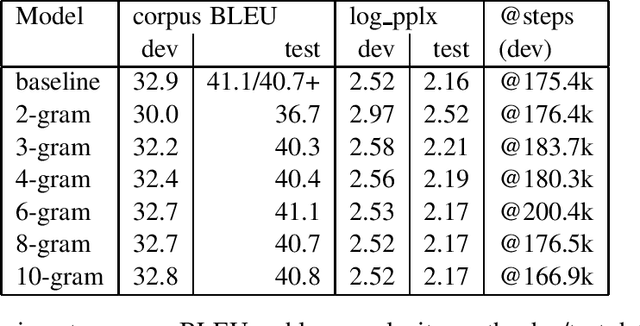
Motivated by the fact that most of the information relevant to the prediction of target tokens is drawn from the source sentence $S=s_1, \ldots, s_S$, we propose truncating the target-side window used for computing self-attention by making an $N$-gram assumption. Experiments on WMT EnDe and EnFr data sets show that the $N$-gram masked self-attention model loses very little in BLEU score for $N$ values in the range $4, \ldots, 8$, depending on the task.
Tagged Back-Translation
Jun 15, 2019
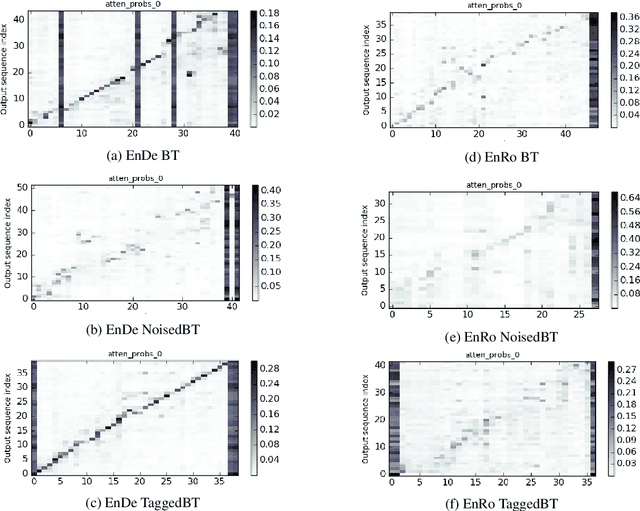
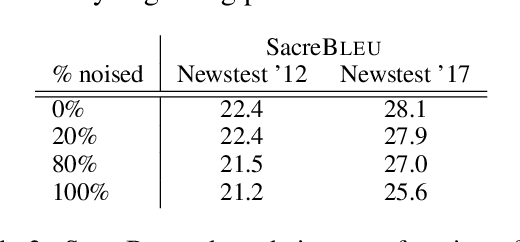
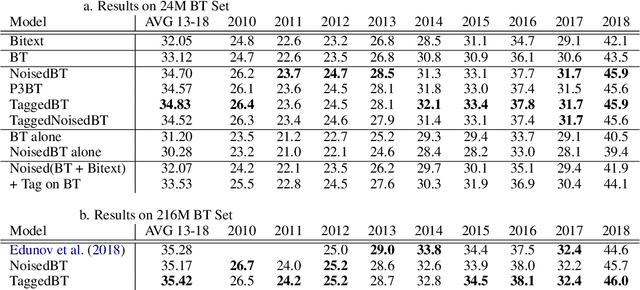
Recent work in Neural Machine Translation (NMT) has shown significant quality gains from noised-beam decoding during back-translation, a method to generate synthetic parallel data. We show that the main role of such synthetic noise is not to diversify the source side, as previously suggested, but simply to indicate to the model that the given source is synthetic. We propose a simpler alternative to noising techniques, consisting of tagging back-translated source sentences with an extra token. Our results on WMT outperform noised back-translation in English-Romanian and match performance on English-German, re-defining state-of-the-art in the former.
Dynamically Composing Domain-Data Selection with Clean-Data Selection by "Co-Curricular Learning" for Neural Machine Translation
Jun 03, 2019

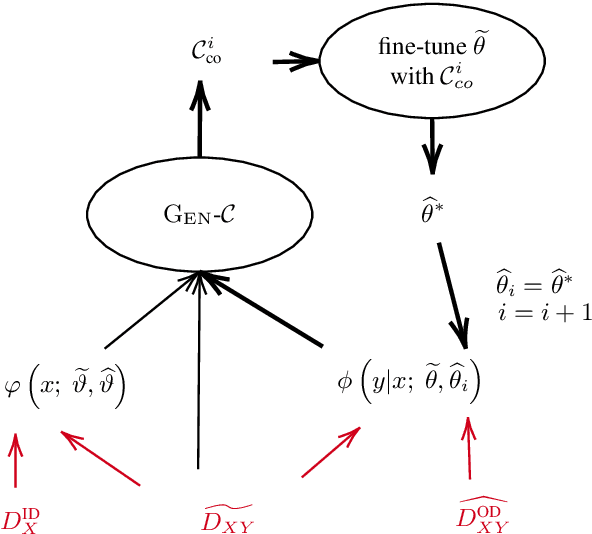
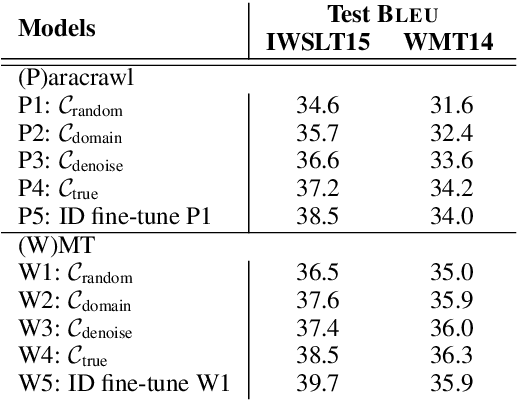
Noise and domain are important aspects of data quality for neural machine translation. Existing research focus separately on domain-data selection, clean-data selection, or their static combination, leaving the dynamic interaction across them not explicitly examined. This paper introduces a "co-curricular learning" method to compose dynamic domain-data selection with dynamic clean-data selection, for transfer learning across both capabilities. We apply an EM-style optimization procedure to further refine the "co-curriculum". Experiment results and analysis with two domains demonstrate the effectiveness of the method and the properties of data scheduled by the co-curriculum.
* 11 pages