 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData Troubles in Sentence Level Confidence Estimation for Machine Translation
Oct 26, 2020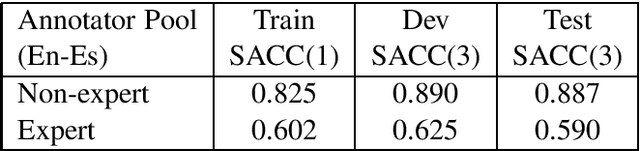
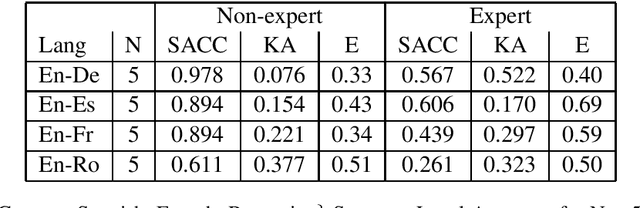
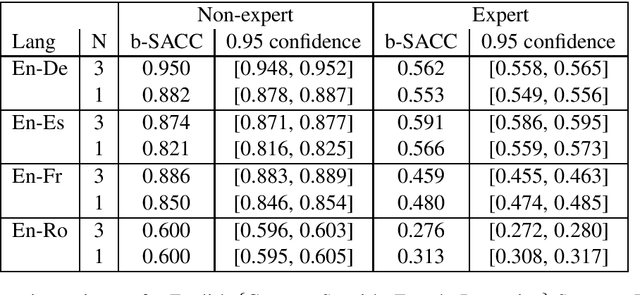
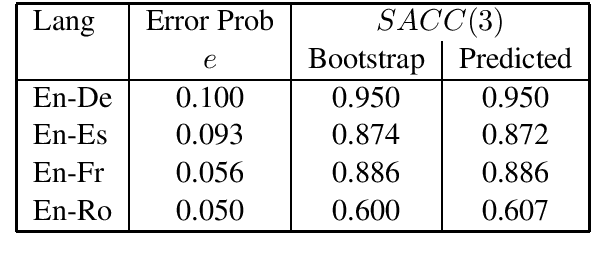
The paper investigates the feasibility of confidence estimation for neural machine translation models operating at the high end of the performance spectrum. As a side product of the data annotation process necessary for building such models we propose sentence level accuracy $SACC$ as a simple, self-explanatory evaluation metric for quality of translation. Experiments on two different annotator pools, one comprised of non-expert (crowd-sourced) and one of expert (professional) translators show that $SACC$ can vary greatly depending on the translation proficiency of the annotators, despite the fact that both pools are about equally reliable according to Krippendorff's alpha metric; the relatively low values of inter-annotator agreement confirm the expectation that sentence-level binary labeling $good$ / $needs\ work$ for translation out of context is very hard. For an English-Spanish translation model operating at $SACC = 0.89$ according to a non-expert annotator pool we can derive a confidence estimate that labels 0.5-0.6 of the $good$ translations in an "in-domain" test set with 0.95 Precision. Switching to an expert annotator pool decreases $SACC$ dramatically: $0.61$ for English-Spanish, measured on the exact same data as above. This forces us to lower the CE model operating point to 0.9 Precision while labeling correctly about 0.20-0.25 of the $good$ translations in the data. We find surprising the extent to which CE depends on the level of proficiency of the annotator pool used for labeling the data. This leads to an important recommendation we wish to make when tackling CE modeling in practice: it is critical to match the end-user expectation for translation quality in the desired domain with the demands of annotators assigning binary quality labels to CE training data.
Practical Perspectives on Quality Estimation for Machine Translation
May 02, 2020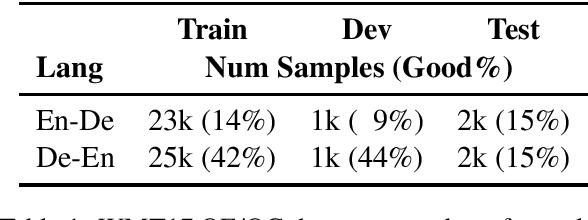
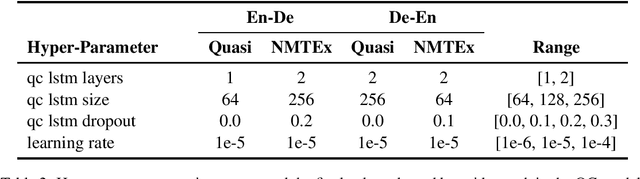
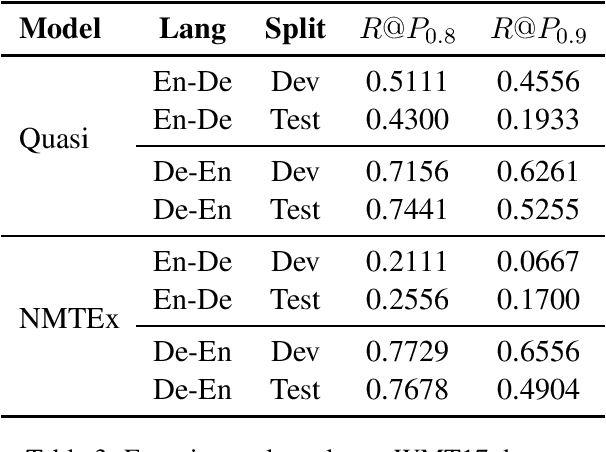
Sentence level quality estimation (QE) for machine translation (MT) attempts to predict the translation edit rate (TER) cost of post-editing work required to correct MT output. We describe our view on sentence-level QE as dictated by several practical setups encountered in the industry. We find consumers of MT output---whether human or algorithmic ones---to be primarily interested in a binary quality metric: is the translated sentence adequate as-is or does it need post-editing? Motivated by this we propose a quality classification (QC) view on sentence-level QE whereby we focus on maximizing recall at precision above a given threshold. We demonstrate that, while classical QE regression models fare poorly on this task, they can be re-purposed by replacing the output regression layer with a binary classification one, achieving 50-60\% recall at 90\% precision. For a high-quality MT system producing 75-80\% correct translations, this promises a significant reduction in post-editing work indeed.
Dial2Desc: End-to-end Dialogue Description Generation
Nov 01, 2018


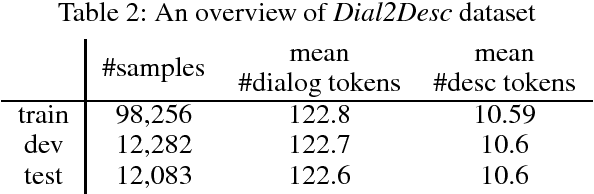
We first propose a new task named Dialogue Description (Dial2Desc). Unlike other existing dialogue summarization tasks such as meeting summarization, we do not maintain the natural flow of a conversation but describe an object or an action of what people are talking about. The Dial2Desc system takes a dialogue text as input, then outputs a concise description of the object or the action involved in this conversation. After reading this short description, one can quickly extract the main topic of a conversation and build a clear picture in his mind, without reading or listening to the whole conversation. Based on the existing dialogue dataset, we build a new dataset, which has more than one hundred thousand dialogue-description pairs. As a step forward, we demonstrate that one can get more accurate and descriptive results using a new neural attentive model that exploits the interaction between utterances from different speakers, compared with other baselines.
Learning Generative ConvNets via Multi-grid Modeling and Sampling
Apr 18, 2018



This paper proposes a multi-grid method for learning energy-based generative ConvNet models of images. For each grid, we learn an energy-based probabilistic model where the energy function is defined by a bottom-up convolutional neural network (ConvNet or CNN). Learning such a model requires generating synthesized examples from the model. Within each iteration of our learning algorithm, for each observed training image, we generate synthesized images at multiple grids by initializing the finite-step MCMC sampling from a minimal 1 x 1 version of the training image. The synthesized image at each subsequent grid is obtained by a finite-step MCMC initialized from the synthesized image generated at the previous coarser grid. After obtaining the synthesized examples, the parameters of the models at multiple grids are updated separately and simultaneously based on the differences between synthesized and observed examples. We show that this multi-grid method can learn realistic energy-based generative ConvNet models, and it outperforms the original contrastive divergence (CD) and persistent CD.