 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData Troubles in Sentence Level Confidence Estimation for Machine Translation
Oct 26, 2020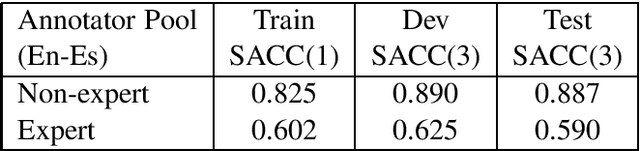
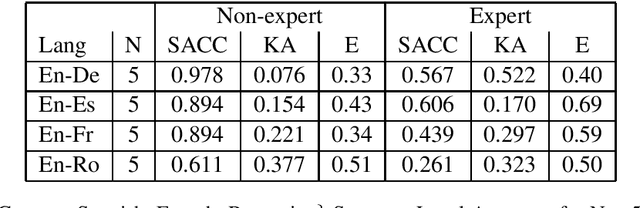
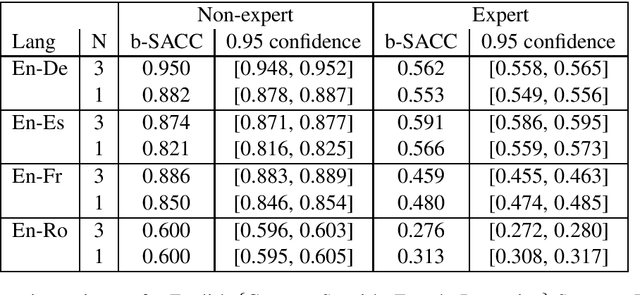
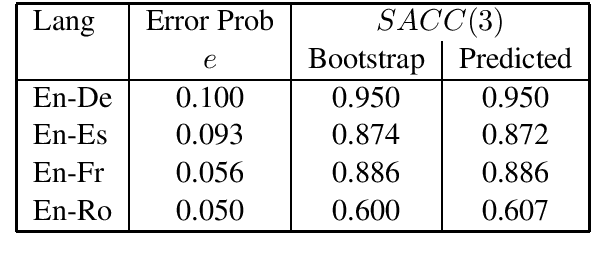
The paper investigates the feasibility of confidence estimation for neural machine translation models operating at the high end of the performance spectrum. As a side product of the data annotation process necessary for building such models we propose sentence level accuracy $SACC$ as a simple, self-explanatory evaluation metric for quality of translation. Experiments on two different annotator pools, one comprised of non-expert (crowd-sourced) and one of expert (professional) translators show that $SACC$ can vary greatly depending on the translation proficiency of the annotators, despite the fact that both pools are about equally reliable according to Krippendorff's alpha metric; the relatively low values of inter-annotator agreement confirm the expectation that sentence-level binary labeling $good$ / $needs\ work$ for translation out of context is very hard. For an English-Spanish translation model operating at $SACC = 0.89$ according to a non-expert annotator pool we can derive a confidence estimate that labels 0.5-0.6 of the $good$ translations in an "in-domain" test set with 0.95 Precision. Switching to an expert annotator pool decreases $SACC$ dramatically: $0.61$ for English-Spanish, measured on the exact same data as above. This forces us to lower the CE model operating point to 0.9 Precision while labeling correctly about 0.20-0.25 of the $good$ translations in the data. We find surprising the extent to which CE depends on the level of proficiency of the annotator pool used for labeling the data. This leads to an important recommendation we wish to make when tackling CE modeling in practice: it is critical to match the end-user expectation for translation quality in the desired domain with the demands of annotators assigning binary quality labels to CE training data.
Zero-Shot Cross-lingual Classification Using Multilingual Neural Machine Translation
Sep 12, 2018



Transferring representations from large supervised tasks to downstream tasks has shown promising results in AI fields such as Computer Vision and Natural Language Processing (NLP). In parallel, the recent progress in Machine Translation (MT) has enabled one to train multilingual Neural MT (NMT) systems that can translate between multiple languages and are also capable of performing zero-shot translation. However, little attention has been paid to leveraging representations learned by a multilingual NMT system to enable zero-shot multilinguality in other NLP tasks. In this paper, we demonstrate a simple framework, a multilingual Encoder-Classifier, for cross-lingual transfer learning by reusing the encoder from a multilingual NMT system and stitching it with a task-specific classifier component. Our proposed model achieves significant improvements in the English setup on three benchmark tasks - Amazon Reviews, SST and SNLI. Further, our system can perform classification in a new language for which no classification data was seen during training, showing that zero-shot classification is possible and remarkably competitive. In order to understand the underlying factors contributing to this finding, we conducted a series of analyses on the effect of the shared vocabulary, the training data type for NMT, classifier complexity, encoder representation power, and model generalization on zero-shot performance. Our results provide strong evidence that the representations learned from multilingual NMT systems are widely applicable across languages and tasks.
Google's Neural Machine Translation System: Bridging the Gap between Human and Machine Translation
Oct 08, 2016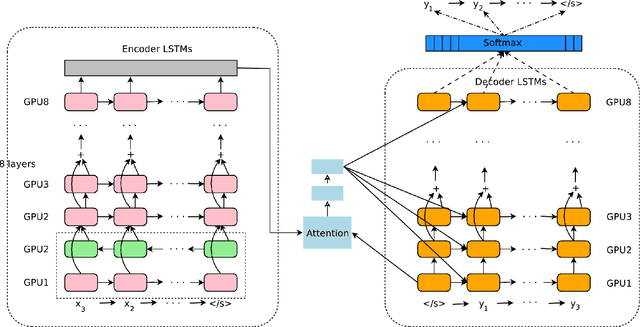

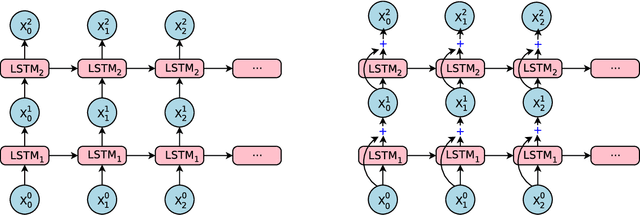
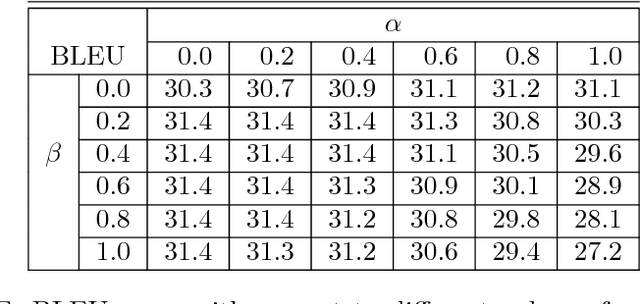
Neural Machine Translation (NMT) is an end-to-end learning approach for automated translation, with the potential to overcome many of the weaknesses of conventional phrase-based translation systems. Unfortunately, NMT systems are known to be computationally expensive both in training and in translation inference. Also, most NMT systems have difficulty with rare words. These issues have hindered NMT's use in practical deployments and services, where both accuracy and speed are essential. In this work, we present GNMT, Google's Neural Machine Translation system, which attempts to address many of these issues. Our model consists of a deep LSTM network with 8 encoder and 8 decoder layers using attention and residual connections. To improve parallelism and therefore decrease training time, our attention mechanism connects the bottom layer of the decoder to the top layer of the encoder. To accelerate the final translation speed, we employ low-precision arithmetic during inference computations. To improve handling of rare words, we divide words into a limited set of common sub-word units ("wordpieces") for both input and output. This method provides a good balance between the flexibility of "character"-delimited models and the efficiency of "word"-delimited models, naturally handles translation of rare words, and ultimately improves the overall accuracy of the system. Our beam search technique employs a length-normalization procedure and uses a coverage penalty, which encourages generation of an output sentence that is most likely to cover all the words in the source sentence. On the WMT'14 English-to-French and English-to-German benchmarks, GNMT achieves competitive results to state-of-the-art. Using a human side-by-side evaluation on a set of isolated simple sentences, it reduces translation errors by an average of 60% compared to Google's phrase-based production system.