 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistilling Text Style Transfer With Self-Explanation From LLMs
Mar 02, 2024



Text Style Transfer (TST) seeks to alter the style of text while retaining its core content. Given the constraints of limited parallel datasets for TST, we propose CoTeX, a framework that leverages large language models (LLMs) alongside chain-of-thought (CoT) prompting to facilitate TST. CoTeX distills the complex rewriting and reasoning capabilities of LLMs into more streamlined models capable of working with both non-parallel and parallel data. Through experimentation across four TST datasets, CoTeX is shown to surpass traditional supervised fine-tuning and knowledge distillation methods, particularly in low-resource settings. We conduct a comprehensive evaluation, comparing CoTeX against current unsupervised, supervised, in-context learning (ICL) techniques, and instruction-tuned LLMs. Furthermore, CoTeX distinguishes itself by offering transparent explanations for its style transfer process.
Data Troubles in Sentence Level Confidence Estimation for Machine Translation
Oct 26, 2020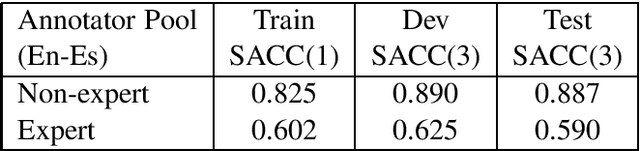
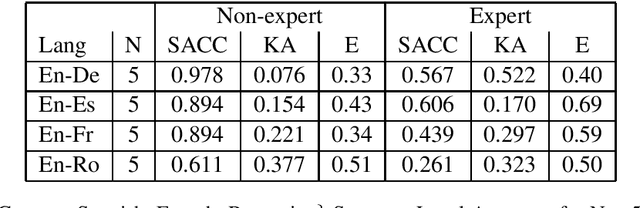
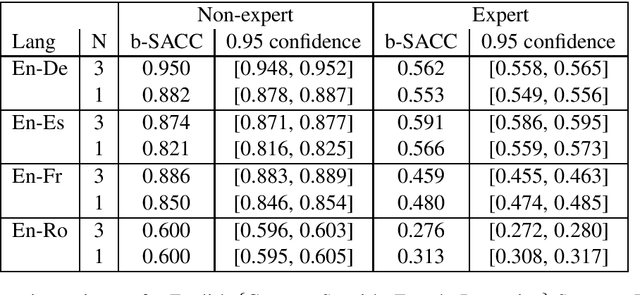
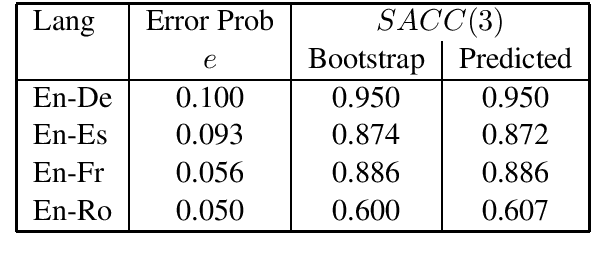
The paper investigates the feasibility of confidence estimation for neural machine translation models operating at the high end of the performance spectrum. As a side product of the data annotation process necessary for building such models we propose sentence level accuracy $SACC$ as a simple, self-explanatory evaluation metric for quality of translation. Experiments on two different annotator pools, one comprised of non-expert (crowd-sourced) and one of expert (professional) translators show that $SACC$ can vary greatly depending on the translation proficiency of the annotators, despite the fact that both pools are about equally reliable according to Krippendorff's alpha metric; the relatively low values of inter-annotator agreement confirm the expectation that sentence-level binary labeling $good$ / $needs\ work$ for translation out of context is very hard. For an English-Spanish translation model operating at $SACC = 0.89$ according to a non-expert annotator pool we can derive a confidence estimate that labels 0.5-0.6 of the $good$ translations in an "in-domain" test set with 0.95 Precision. Switching to an expert annotator pool decreases $SACC$ dramatically: $0.61$ for English-Spanish, measured on the exact same data as above. This forces us to lower the CE model operating point to 0.9 Precision while labeling correctly about 0.20-0.25 of the $good$ translations in the data. We find surprising the extent to which CE depends on the level of proficiency of the annotator pool used for labeling the data. This leads to an important recommendation we wish to make when tackling CE modeling in practice: it is critical to match the end-user expectation for translation quality in the desired domain with the demands of annotators assigning binary quality labels to CE training data.
Practical Perspectives on Quality Estimation for Machine Translation
May 02, 2020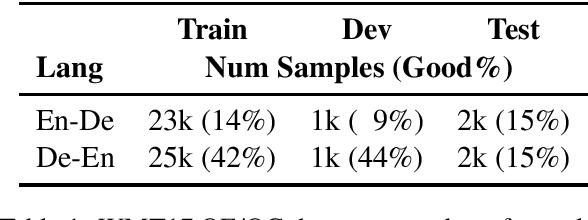
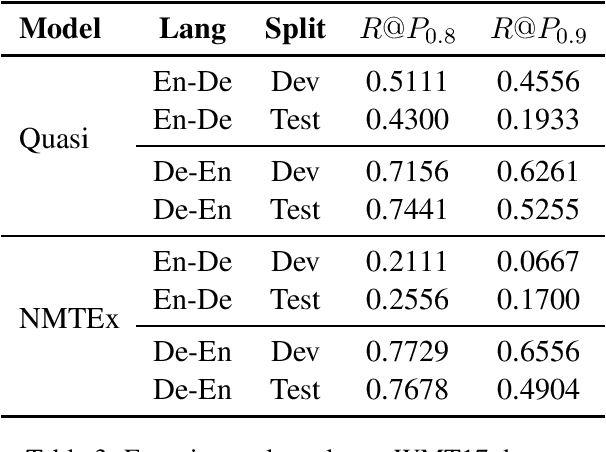
Sentence level quality estimation (QE) for machine translation (MT) attempts to predict the translation edit rate (TER) cost of post-editing work required to correct MT output. We describe our view on sentence-level QE as dictated by several practical setups encountered in the industry. We find consumers of MT output---whether human or algorithmic ones---to be primarily interested in a binary quality metric: is the translated sentence adequate as-is or does it need post-editing? Motivated by this we propose a quality classification (QC) view on sentence-level QE whereby we focus on maximizing recall at precision above a given threshold. We demonstrate that, while classical QE regression models fare poorly on this task, they can be re-purposed by replacing the output regression layer with a binary classification one, achieving 50-60\% recall at 90\% precision. For a high-quality MT system producing 75-80\% correct translations, this promises a significant reduction in post-editing work indeed.