 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePractical Perspectives on Quality Estimation for Machine Translation
Paper and Code
May 02, 2020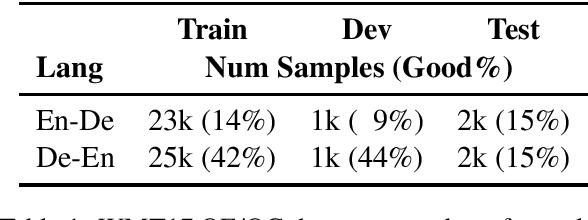
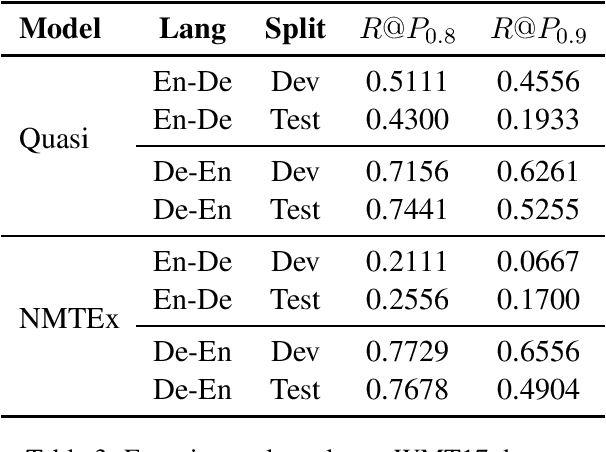
Sentence level quality estimation (QE) for machine translation (MT) attempts to predict the translation edit rate (TER) cost of post-editing work required to correct MT output. We describe our view on sentence-level QE as dictated by several practical setups encountered in the industry. We find consumers of MT output---whether human or algorithmic ones---to be primarily interested in a binary quality metric: is the translated sentence adequate as-is or does it need post-editing? Motivated by this we propose a quality classification (QC) view on sentence-level QE whereby we focus on maximizing recall at precision above a given threshold. We demonstrate that, while classical QE regression models fare poorly on this task, they can be re-purposed by replacing the output regression layer with a binary classification one, achieving 50-60\% recall at 90\% precision. For a high-quality MT system producing 75-80\% correct translations, this promises a significant reduction in post-editing work indeed.