 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdapters for Altering LLM Vocabularies: What Languages Benefit the Most?
Oct 12, 2024



Vocabulary adaptation, which integrates new vocabulary into pre-trained language models (LMs), enables expansion to new languages and mitigates token over-fragmentation. However, existing approaches are limited by their reliance on heuristic or external embeddings. We propose VocADT, a novel method for vocabulary adaptation using adapter modules that are trained to learn the optimal linear combination of existing embeddings while keeping the model's weights fixed. VocADT offers a flexible and scalable solution without requiring external resources or language constraints. Across 11 languages-with various scripts, resource availability, and fragmentation-we demonstrate that VocADT outperforms the original Mistral model and other baselines across various multilingual tasks. We find that Latin-script languages and highly fragmented languages benefit the most from vocabulary adaptation. We further fine-tune the adapted model on the generative task of machine translation and find that vocabulary adaptation is still beneficial after fine-tuning and that VocADT is the most effective method.
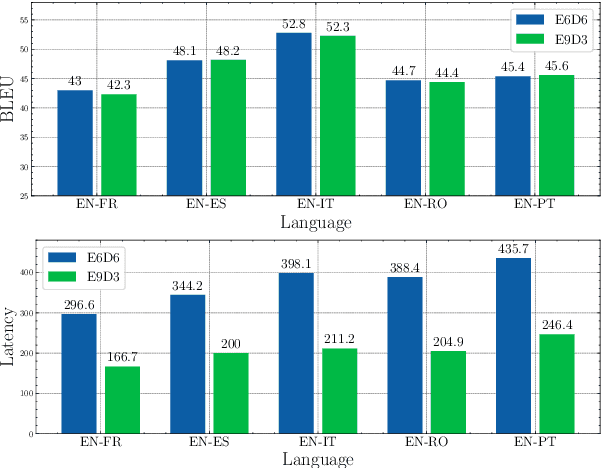
X-ALMA: Plug & Play Modules and Adaptive Rejection for Quality Translation at Scale
Oct 04, 2024



Large language models (LLMs) have achieved remarkable success across various NLP tasks, yet their focus has predominantly been on English due to English-centric pre-training and limited multilingual data. While some multilingual LLMs claim to support for hundreds of languages, models often fail to provide high-quality response for mid- and low-resource languages, leading to imbalanced performance heavily skewed in favor of high-resource languages like English and Chinese. In this paper, we prioritize quality over scaling number of languages, with a focus on multilingual machine translation task, and introduce X-ALMA, a model designed with a commitment to ensuring top-tier performance across 50 diverse languages, regardless of their resource levels. X-ALMA surpasses state-of-the-art open-source multilingual LLMs, such as Aya-101 and Aya-23, in every single translation direction on the FLORES and WMT'23 test datasets according to COMET-22. This is achieved by plug-and-play language-specific module architecture to prevent language conflicts during training and a carefully designed training regimen with novel optimization methods to maximize the translation performance. At the final stage of training regimen, our proposed Adaptive Rejection Preference Optimization (ARPO) surpasses existing preference optimization methods in translation tasks.
Building Multilingual Machine Translation Systems That Serve Arbitrary X-Y Translations
Jun 30, 2022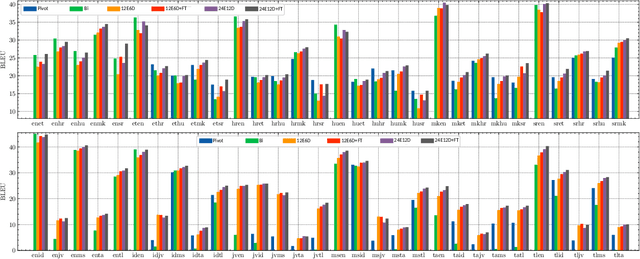
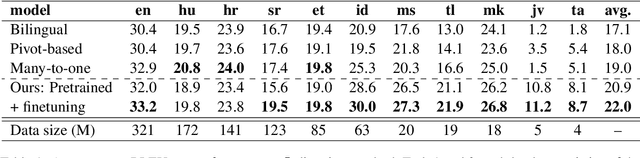
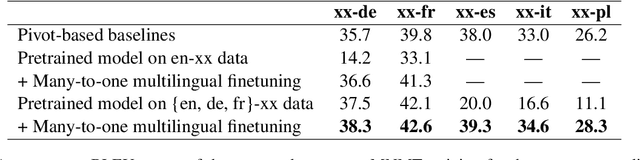
Multilingual Neural Machine Translation (MNMT) enables one system to translate sentences from multiple source languages to multiple target languages, greatly reducing deployment costs compared with conventional bilingual systems. The MNMT training benefit, however, is often limited to many-to-one directions. The model suffers from poor performance in one-to-many and many-to-many with zero-shot setup. To address this issue, this paper discusses how to practically build MNMT systems that serve arbitrary X-Y translation directions while leveraging multilinguality with a two-stage training strategy of pretraining and finetuning. Experimenting with the WMT'21 multilingual translation task, we demonstrate that our systems outperform the conventional baselines of direct bilingual models and pivot translation models for most directions, averagely giving +6.0 and +4.1 BLEU, without the need for architecture change or extra data collection. Moreover, we also examine our proposed approach in an extremely large-scale data setting to accommodate practical deployment scenarios.
Improving Multilingual Translation by Representation and Gradient Regularization
Sep 10, 2021


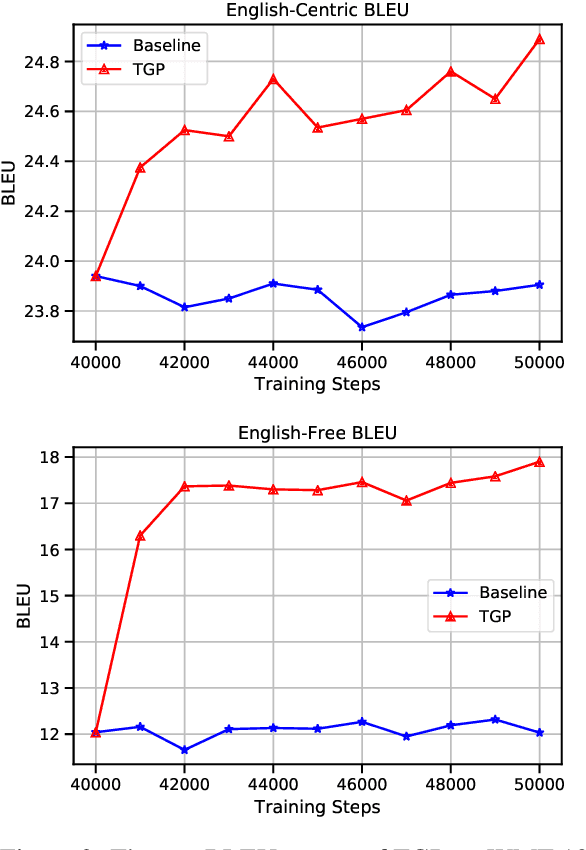
Multilingual Neural Machine Translation (NMT) enables one model to serve all translation directions, including ones that are unseen during training, i.e. zero-shot translation. Despite being theoretically attractive, current models often produce low quality translations -- commonly failing to even produce outputs in the right target language. In this work, we observe that off-target translation is dominant even in strong multilingual systems, trained on massive multilingual corpora. To address this issue, we propose a joint approach to regularize NMT models at both representation-level and gradient-level. At the representation level, we leverage an auxiliary target language prediction task to regularize decoder outputs to retain information about the target language. At the gradient level, we leverage a small amount of direct data (in thousands of sentence pairs) to regularize model gradients. Our results demonstrate that our approach is highly effective in both reducing off-target translation occurrences and improving zero-shot translation performance by +5.59 and +10.38 BLEU on WMT and OPUS datasets respectively. Moreover, experiments show that our method also works well when the small amount of direct data is not available.
XLM-T: Scaling up Multilingual Machine Translation with Pretrained Cross-lingual Transformer Encoders
Dec 31, 2020

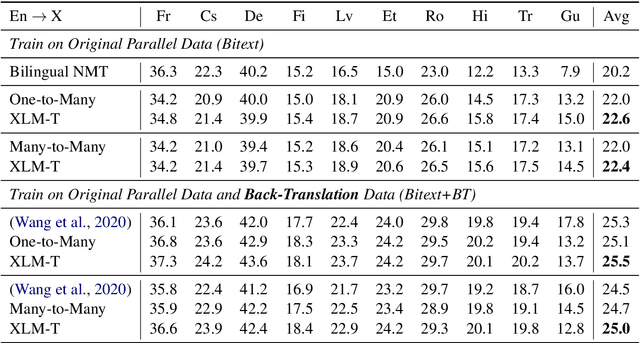

Multilingual machine translation enables a single model to translate between different languages. Most existing multilingual machine translation systems adopt a randomly initialized Transformer backbone. In this work, inspired by the recent success of language model pre-training, we present XLM-T, which initializes the model with an off-the-shelf pretrained cross-lingual Transformer encoder and fine-tunes it with multilingual parallel data. This simple method achieves significant improvements on a WMT dataset with 10 language pairs and the OPUS-100 corpus with 94 pairs. Surprisingly, the method is also effective even upon the strong baseline with back-translation. Moreover, extensive analysis of XLM-T on unsupervised syntactic parsing, word alignment, and multilingual classification explains its effectiveness for machine translation. The code will be at https://aka.ms/xlm-t.
Neural Text Generation with Artificial Negative Examples
Dec 28, 2020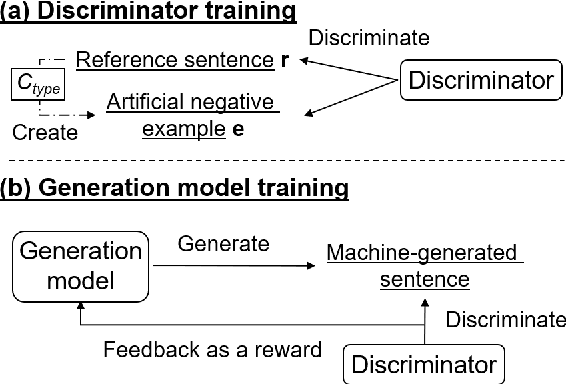



Neural text generation models conditioning on given input (e.g. machine translation and image captioning) are usually trained by maximum likelihood estimation of target text. However, the trained models suffer from various types of errors at inference time. In this paper, we propose to suppress an arbitrary type of errors by training the text generation model in a reinforcement learning framework, where we use a trainable reward function that is capable of discriminating between references and sentences containing the targeted type of errors. We create such negative examples by artificially injecting the targeted errors to the references. In experiments, we focus on two error types, repeated and dropped tokens in model-generated text. The experimental results show that our method can suppress the generation errors and achieve significant improvements on two machine translation and two image captioning tasks.
Lingvo: a Modular and Scalable Framework for Sequence-to-Sequence Modeling
Feb 21, 2019
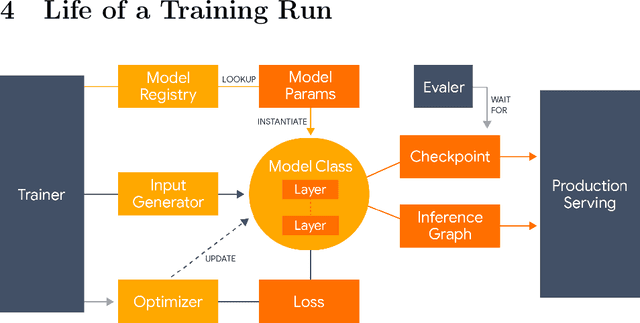
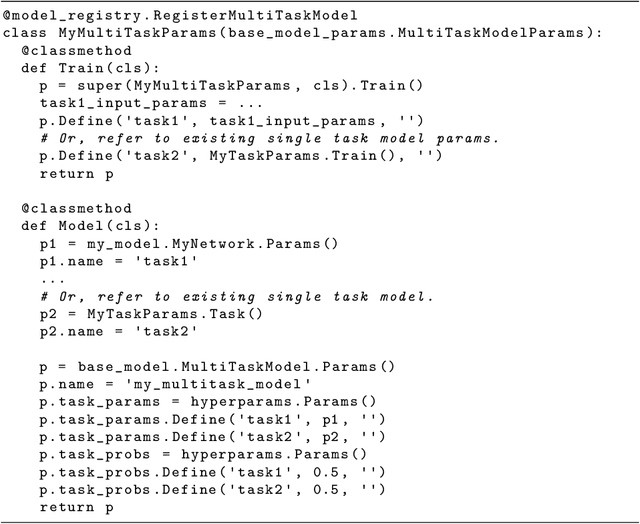
Lingvo is a Tensorflow framework offering a complete solution for collaborative deep learning research, with a particular focus towards sequence-to-sequence models. Lingvo models are composed of modular building blocks that are flexible and easily extensible, and experiment configurations are centralized and highly customizable. Distributed training and quantized inference are supported directly within the framework, and it contains existing implementations of a large number of utilities, helper functions, and the newest research ideas. Lingvo has been used in collaboration by dozens of researchers in more than 20 papers over the last two years. This document outlines the underlying design of Lingvo and serves as an introduction to the various pieces of the framework, while also offering examples of advanced features that showcase the capabilities of the framework.
Multilingual Extractive Reading Comprehension by Runtime Machine Translation
Nov 02, 2018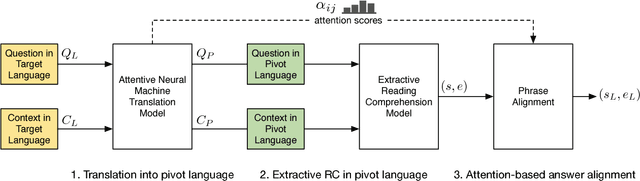

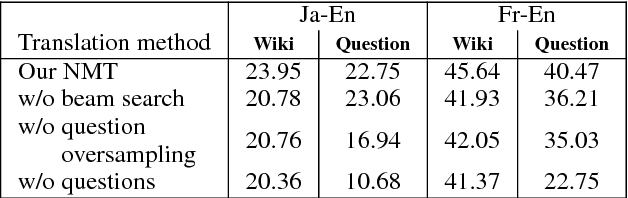

Despite recent work in Reading Comprehension (RC), progress has been mostly limited to English due to the lack of large-scale datasets in other languages. In this work, we introduce the first RC system for languages without RC training data. Given a target language without RC training data and a pivot language with RC training data (e.g. English), our method leverages existing RC resources in the pivot language by combining a competitive RC model in the pivot language with an attentive Neural Machine Translation (NMT) model. We first translate the data from the target to the pivot language, and then obtain an answer using the RC model in the pivot language. Finally, we recover the corresponding answer in the original language using soft-alignment attention scores from the NMT model. We create evaluation sets of RC data in two non-English languages, namely Japanese and French, to evaluate our method. Experimental results on these datasets show that our method significantly outperforms a back-translation baseline of a state-of-the-art product-level machine translation system.
Zero-Shot Cross-lingual Classification Using Multilingual Neural Machine Translation
Sep 12, 2018



Transferring representations from large supervised tasks to downstream tasks has shown promising results in AI fields such as Computer Vision and Natural Language Processing (NLP). In parallel, the recent progress in Machine Translation (MT) has enabled one to train multilingual Neural MT (NMT) systems that can translate between multiple languages and are also capable of performing zero-shot translation. However, little attention has been paid to leveraging representations learned by a multilingual NMT system to enable zero-shot multilinguality in other NLP tasks. In this paper, we demonstrate a simple framework, a multilingual Encoder-Classifier, for cross-lingual transfer learning by reusing the encoder from a multilingual NMT system and stitching it with a task-specific classifier component. Our proposed model achieves significant improvements in the English setup on three benchmark tasks - Amazon Reviews, SST and SNLI. Further, our system can perform classification in a new language for which no classification data was seen during training, showing that zero-shot classification is possible and remarkably competitive. In order to understand the underlying factors contributing to this finding, we conducted a series of analyses on the effect of the shared vocabulary, the training data type for NMT, classifier complexity, encoder representation power, and model generalization on zero-shot performance. Our results provide strong evidence that the representations learned from multilingual NMT systems are widely applicable across languages and tasks.
Learning to Parse and Translate Improves Neural Machine Translation
Apr 23, 2017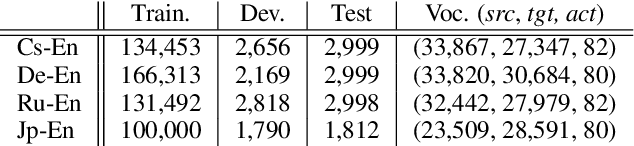
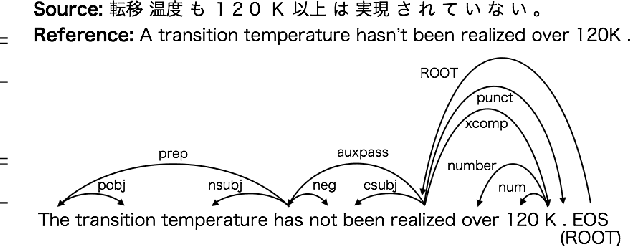
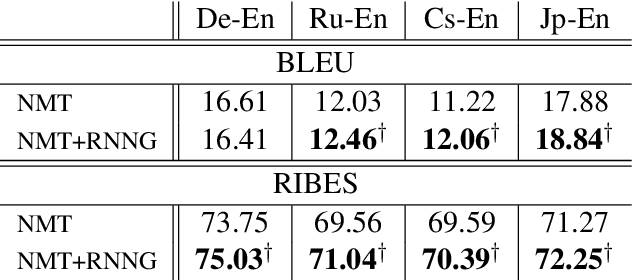
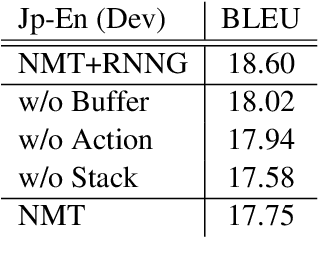
There has been relatively little attention to incorporating linguistic prior to neural machine translation. Much of the previous work was further constrained to considering linguistic prior on the source side. In this paper, we propose a hybrid model, called NMT+RNNG, that learns to parse and translate by combining the recurrent neural network grammar into the attention-based neural machine translation. Our approach encourages the neural machine translation model to incorporate linguistic prior during training, and lets it translate on its own afterward. Extensive experiments with four language pairs show the effectiveness of the proposed NMT+RNNG.