 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Translation Quality Estimation Exploiting Synthetic Data and Pre-trained Multilingual Encoder
Nov 09, 2023Translation quality estimation (TQE) is the task of predicting translation quality without reference translations. Due to the enormous cost of creating training data for TQE, only a few translation directions can benefit from supervised training. To address this issue, unsupervised TQE methods have been studied. In this paper, we extensively investigate the usefulness of synthetic TQE data and pre-trained multilingual encoders in unsupervised sentence-level TQE, both of which have been proven effective in the supervised training scenarios. Our experiment on WMT20 and WMT21 datasets revealed that this approach can outperform other unsupervised TQE methods on high- and low-resource translation directions in predicting post-editing effort and human evaluation score, and some zero-resource translation directions in predicting post-editing effort.
Neural Text Generation with Artificial Negative Examples
Dec 28, 2020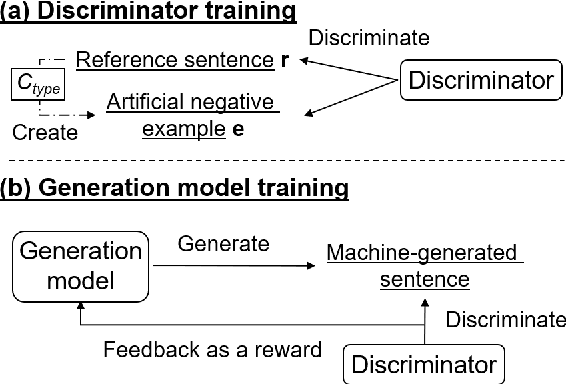



Neural text generation models conditioning on given input (e.g. machine translation and image captioning) are usually trained by maximum likelihood estimation of target text. However, the trained models suffer from various types of errors at inference time. In this paper, we propose to suppress an arbitrary type of errors by training the text generation model in a reinforcement learning framework, where we use a trainable reward function that is capable of discriminating between references and sentences containing the targeted type of errors. We create such negative examples by artificially injecting the targeted errors to the references. In experiments, we focus on two error types, repeated and dropped tokens in model-generated text. The experimental results show that our method can suppress the generation errors and achieve significant improvements on two machine translation and two image captioning tasks.