 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Text Generation with Artificial Negative Examples
Paper and Code
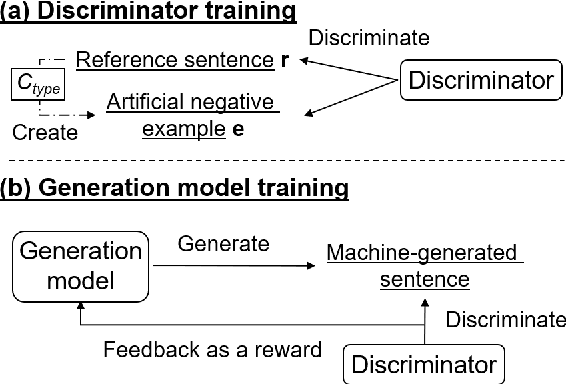



Neural text generation models conditioning on given input (e.g. machine translation and image captioning) are usually trained by maximum likelihood estimation of target text. However, the trained models suffer from various types of errors at inference time. In this paper, we propose to suppress an arbitrary type of errors by training the text generation model in a reinforcement learning framework, where we use a trainable reward function that is capable of discriminating between references and sentences containing the targeted type of errors. We create such negative examples by artificially injecting the targeted errors to the references. In experiments, we focus on two error types, repeated and dropped tokens in model-generated text. The experimental results show that our method can suppress the generation errors and achieve significant improvements on two machine translation and two image captioning tasks.