 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRestoration-Guided Kuzushiji Character Recognition Framework under Seal Interference
Feb 22, 2026Kuzushiji was one of the most popular writing styles in pre-modern Japan and was widely used in both personal letters and official documents. However, due to its highly cursive forms and extensive glyph variations, most modern Japanese readers cannot directly interpret Kuzushiji characters. Therefore, recent research has focused on developing automated Kuzushiji character recognition methods, which have achieved satisfactory performance on relatively clean Kuzushiji document images. However, existing methods struggle to maintain recognition accuracy under seal interference (e.g., when seals overlap characters), despite the frequent occurrence of seals in pre-modern Japanese documents. To address this challenge, we propose a three-stage restoration-guided Kuzushiji character recognition (RG-KCR) framework specifically designed to mitigate seal interference. We construct datasets for evaluating Kuzushiji character detection (Stage 1) and classification (Stage 3). Experimental results show that the YOLOv12-medium model achieves a precision of 98.0% and a recall of 93.3% on the constructed test set. We quantitatively evaluate the restoration performance of Stage 2 using PSNR and SSIM. In addition, we conduct an ablation study to demonstrate that Stage 2 improves the Top-1 accuracy of Metom, a Vision Transformer (ViT)-based Kuzushiji classifier employed in Stage 3, from 93.45% to 95.33%. The implementation code of this work is available at https://ruiyangju.github.io/RG-KCR.
LegalRikai: Open Benchmark -- Benchmark for Complex Japanese Corporate Legal Tasks
Dec 15, 2025This paper introduces LegalRikai: Open Benchmark, a new benchmark comprising four complex tasks that emulate Japanese corporate legal practices. The benchmark was created by legal professionals under the supervision of an attorney. This benchmark has 100 samples that require long-form, structured outputs, and we evaluated them against multiple practical criteria. We conducted both human and automated evaluations using leading LLMs, including GPT-5, Gemini 2.5 Pro, and Claude Opus 4.1. Our human evaluation revealed that abstract instructions prompted unnecessary modifications, highlighting model weaknesses in document-level editing that were missed by conventional short-text tasks. Furthermore, our analysis reveals that automated evaluation aligns well with human judgment on criteria with clear linguistic grounding, and assessing structural consistency remains a challenge. The result demonstrates the utility of automated evaluation as a screening tool when expert availability is limited. We propose a dataset evaluation framework to promote more practice-oriented research in the legal domain.
DKDS: A Benchmark Dataset of Degraded Kuzushiji Documents with Seals for Detection and Binarization
Nov 12, 2025Kuzushiji, a pre-modern Japanese cursive script, can currently be read and understood by only a few thousand trained experts in Japan. With the rapid development of deep learning, researchers have begun applying Optical Character Recognition (OCR) techniques to transcribe Kuzushiji into modern Japanese. Although existing OCR methods perform well on clean pre-modern Japanese documents written in Kuzushiji, they often fail to consider various types of noise, such as document degradation and seals, which significantly affect recognition accuracy. To the best of our knowledge, no existing dataset specifically addresses these challenges. To address this gap, we introduce the Degraded Kuzushiji Documents with Seals (DKDS) dataset as a new benchmark for related tasks. We describe the dataset construction process, which required the assistance of a trained Kuzushiji expert, and define two benchmark tracks: (1) text and seal detection and (2) document binarization. For the text and seal detection track, we provide baseline results using multiple versions of the You Only Look Once (YOLO) models for detecting Kuzushiji characters and seals. For the document binarization track, we present baseline results from traditional binarization algorithms, traditional algorithms combined with K-means clustering, and Generative Adversarial Network (GAN)-based methods. The DKDS dataset and the implementation code for baseline methods are available at https://ruiyangju.github.io/DKDS.
Developing Vision-Language-Action Model from Egocentric Videos
Sep 26, 2025Egocentric videos capture how humans manipulate objects and tools, providing diverse motion cues for learning object manipulation. Unlike the costly, expert-driven manual teleoperation commonly used in training Vision-Language-Action models (VLAs), egocentric videos offer a scalable alternative. However, prior studies that leverage such videos for training robot policies typically rely on auxiliary annotations, such as detailed hand-pose recordings. Consequently, it remains unclear whether VLAs can be trained directly from raw egocentric videos. In this work, we address this challenge by leveraging EgoScaler, a framework that extracts 6DoF object manipulation trajectories from egocentric videos without requiring auxiliary recordings. We apply EgoScaler to four large-scale egocentric video datasets and automatically refine noisy or incomplete trajectories, thereby constructing a new large-scale dataset for VLA pre-training. Our experiments with a state-of-the-art $\pi_0$ architecture in both simulated and real-robot environments yield three key findings: (i) pre-training on our dataset improves task success rates by over 20\% compared to training from scratch, (ii) the performance is competitive with that achieved using real-robot datasets, and (iii) combining our dataset with real-robot data yields further improvements. These results demonstrate that egocentric videos constitute a promising and scalable resource for advancing VLA research.
EgoOops: A Dataset for Mistake Action Detection from Egocentric Videos with Procedural Texts
Oct 07, 2024


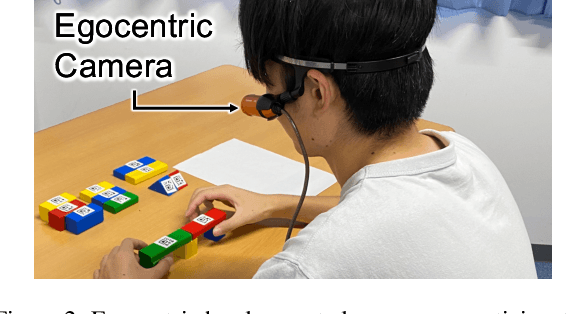
Mistake action detection from egocentric videos is crucial for developing intelligent archives that detect workers' errors and provide feedback. Previous studies have been limited to specific domains, focused on detecting mistakes from videos without procedural texts, and analyzed whether actions are mistakes. To address these limitations, in this paper, we propose the EgoOops dataset, which includes egocentric videos, procedural texts, and three types of annotations: video-text alignment, mistake labels, and descriptions for mistakes. EgoOops covers five procedural domains and includes 50 egocentric videos. The video-text alignment allows the model to detect mistakes based on both videos and procedural texts. The mistake labels and descriptions enable detailed analysis of real-world mistakes. Based on EgoOops, we tackle two tasks: video-text alignment and mistake detection. For video-text alignment, we enhance the recent StepFormer model with an additional loss for fine-tuning. Based on the alignment results, we propose a multi-modal classifier to predict mistake labels. In our experiments, the proposed methods achieve higher performance than the baselines. In addition, our ablation study demonstrates the effectiveness of combining videos and texts. We will release the dataset and codes upon publication.
Vaporetto: Efficient Japanese Tokenization Based on Improved Pointwise Linear Classification
Jun 24, 2024This paper proposes an approach to improve the runtime efficiency of Japanese tokenization based on the pointwise linear classification (PLC) framework, which formulates the whole tokenization process as a sequence of linear classification problems. Our approach optimizes tokenization by leveraging the characteristics of the PLC framework and the task definition. Our approach involves (1) composing multiple classifications into array-based operations, (2) efficient feature lookup with memory-optimized automata, and (3) three orthogonal pre-processing methods for reducing actual score calculation. Thus, our approach makes the tokenization speed 5.7 times faster than the current approach based on the same model without decreasing tokenization accuracy. Our implementation is available at https://github.com/daac-tools/vaporetto under the MIT or Apache-2.0 license.
BioVL-QR: Egocentric Biochemical Video-and-Language Dataset Using Micro QR Codes
Apr 04, 2024This paper introduces a biochemical vision-and-language dataset, which consists of 24 egocentric experiment videos, corresponding protocols, and video-and-language alignments. The key challenge in the wet-lab domain is detecting equipment, reagents, and containers is difficult because the lab environment is scattered by filling objects on the table and some objects are indistinguishable. Therefore, previous studies assume that objects are manually annotated and given for downstream tasks, but this is costly and time-consuming. To address this issue, this study focuses on Micro QR Codes to detect objects automatically. From our preliminary study, we found that detecting objects only using Micro QR Codes is still difficult because the researchers manipulate objects, causing blur and occlusion frequently. To address this, we also propose a novel object labeling method by combining a Micro QR Code detector and an off-the-shelf hand object detector. As one of the applications of our dataset, we conduct the task of generating protocols from experiment videos and find that our approach can generate accurate protocols.
Text-driven Affordance Learning from Egocentric Vision
Apr 03, 2024Visual affordance learning is a key component for robots to understand how to interact with objects. Conventional approaches in this field rely on pre-defined objects and actions, falling short of capturing diverse interactions in realworld scenarios. The key idea of our approach is employing textual instruction, targeting various affordances for a wide range of objects. This approach covers both hand-object and tool-object interactions. We introduce text-driven affordance learning, aiming to learn contact points and manipulation trajectories from an egocentric view following textual instruction. In our task, contact points are represented as heatmaps, and the manipulation trajectory as sequences of coordinates that incorporate both linear and rotational movements for various manipulations. However, when we gather data for this task, manual annotations of these diverse interactions are costly. To this end, we propose a pseudo dataset creation pipeline and build a large pseudo-training dataset: TextAFF80K, consisting of over 80K instances of the contact points, trajectories, images, and text tuples. We extend existing referring expression comprehension models for our task, and experimental results show that our approach robustly handles multiple affordances, serving as a new standard for affordance learning in real-world scenarios.
Automatic Construction of a Large-Scale Corpus for Geoparsing Using Wikipedia Hyperlinks
Mar 25, 2024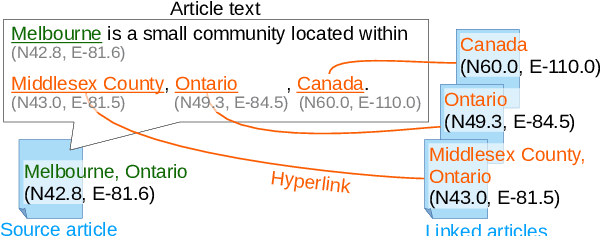
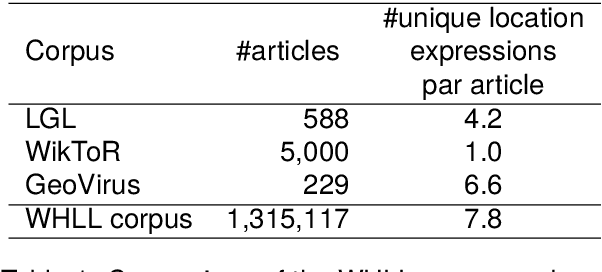

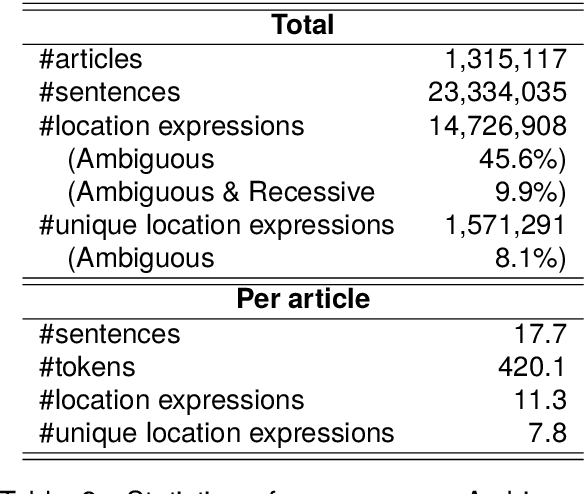
Geoparsing is the task of estimating the latitude and longitude (coordinates) of location expressions in texts. Geoparsing must deal with the ambiguity of the expressions that indicate multiple locations with the same notation. For evaluating geoparsing systems, several corpora have been proposed in previous work. However, these corpora are small-scale and suffer from the coverage of location expressions on general domains. In this paper, we propose Wikipedia Hyperlink-based Location Linking (WHLL), a novel method to construct a large-scale corpus for geoparsing from Wikipedia articles. WHLL leverages hyperlinks in Wikipedia to annotate multiple location expressions with coordinates. With this method, we constructed the WHLL corpus, a new large-scale corpus for geoparsing. The WHLL corpus consists of 1.3M articles, each containing about 7.8 unique location expressions. 45.6% of location expressions are ambiguous and refer to more than one location with the same notation. In each article, location expressions of the article title and those hyperlinks to other articles are assigned with coordinates. By utilizing hyperlinks, we can accurately assign location expressions with coordinates even with ambiguous location expressions in the texts. Experimental results show that there remains room for improvement by disambiguating location expressions.
Vision-Language Interpreter for Robot Task Planning
Nov 02, 2023



Large language models (LLMs) are accelerating the development of language-guided robot planners. Meanwhile, symbolic planners offer the advantage of interpretability. This paper proposes a new task that bridges these two trends, namely, multimodal planning problem specification. The aim is to generate a problem description (PD), a machine-readable file used by the planners to find a plan. By generating PDs from language instruction and scene observation, we can drive symbolic planners in a language-guided framework. We propose a Vision-Language Interpreter (ViLaIn), a new framework that generates PDs using state-of-the-art LLM and vision-language models. ViLaIn can refine generated PDs via error message feedback from the symbolic planner. Our aim is to answer the question: How accurately can ViLaIn and the symbolic planner generate valid robot plans? To evaluate ViLaIn, we introduce a novel dataset called the problem description generation (ProDG) dataset. The framework is evaluated with four new evaluation metrics. Experimental results show that ViLaIn can generate syntactically correct problems with more than 99% accuracy and valid plans with more than 58% accuracy.