 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWarrantScore: Modeling Warrants between Claims and Evidence for Substantiation Evaluation in Peer Reviews
Jan 24, 2026The scientific peer-review process is facing a shortage of human resources due to the rapid growth in the number of submitted papers. The use of language models to reduce the human cost of peer review has been actively explored as a potential solution to this challenge. A method has been proposed to evaluate the level of substantiation in scientific reviews in a manner that is interpretable by humans. This method extracts the core components of an argument, claims and evidence, and assesses the level of substantiation based on the proportion of claims supported by evidence. The level of substantiation refers to the extent to which claims are based on objective facts. However, when assessing the level of substantiation, simply detecting the presence or absence of supporting evidence for a claim is insufficient; it is also necessary to accurately assess the logical inference between a claim and its evidence. We propose a new evaluation metric for scientific review comments that assesses the logical inference between claims and evidence. Experimental results show that the proposed method achieves a higher correlation with human scores than conventional methods, indicating its potential to better support the efficiency of the peer-review process.
KeyMPs: One-Shot Vision-Language Guided Motion Generation by Sequencing DMPs for Occlusion-Rich Tasks
Apr 14, 2025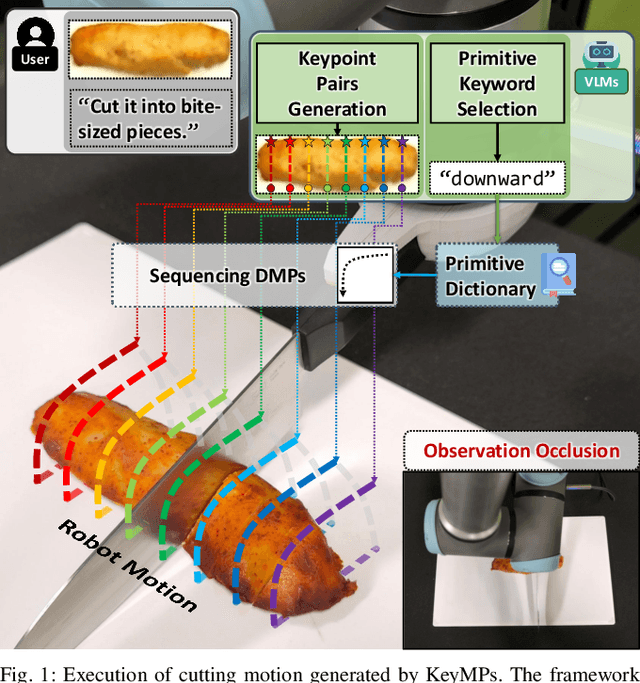
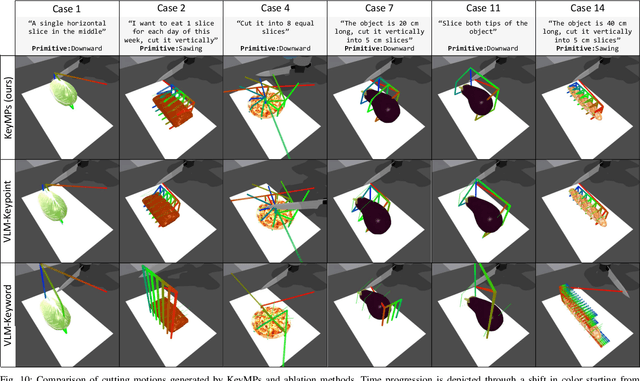
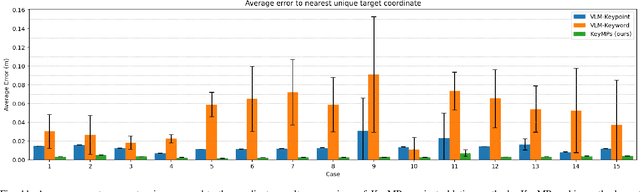
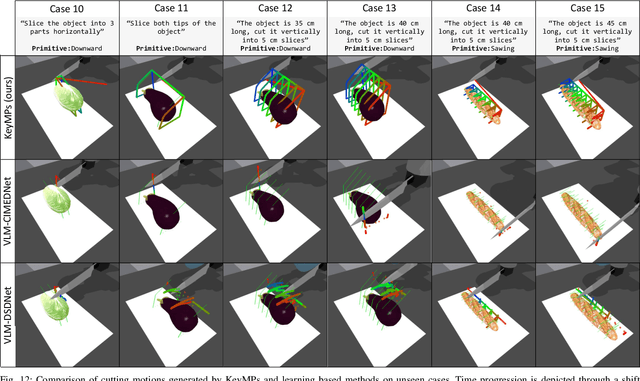
Dynamic Movement Primitives (DMPs) provide a flexible framework wherein smooth robotic motions are encoded into modular parameters. However, they face challenges in integrating multimodal inputs commonly used in robotics like vision and language into their framework. To fully maximize DMPs' potential, enabling them to handle multimodal inputs is essential. In addition, we also aim to extend DMPs' capability to handle object-focused tasks requiring one-shot complex motion generation, as observation occlusion could easily happen mid-execution in such tasks (e.g., knife occlusion in cake icing, hand occlusion in dough kneading, etc.). A promising approach is to leverage Vision-Language Models (VLMs), which process multimodal data and can grasp high-level concepts. However, they typically lack enough knowledge and capabilities to directly infer low-level motion details and instead only serve as a bridge between high-level instructions and low-level control. To address this limitation, we propose Keyword Labeled Primitive Selection and Keypoint Pairs Generation Guided Movement Primitives (KeyMPs), a framework that combines VLMs with sequencing of DMPs. KeyMPs use VLMs' high-level reasoning capability to select a reference primitive through keyword labeled primitive selection and VLMs' spatial awareness to generate spatial scaling parameters used for sequencing DMPs by generalizing the overall motion through keypoint pairs generation, which together enable one-shot vision-language guided motion generation that aligns with the intent expressed in the multimodal input. We validate our approach through an occlusion-rich manipulation task, specifically object cutting experiments in both simulated and real-world environments, demonstrating superior performance over other DMP-based methods that integrate VLMs support.
SBS Figures: Pre-training Figure QA from Stage-by-Stage Synthesized Images
Dec 23, 2024



Building a large-scale figure QA dataset requires a considerable amount of work, from gathering and selecting figures to extracting attributes like text, numbers, and colors, and generating QAs. Although recent developments in LLMs have led to efforts to synthesize figures, most of these focus primarily on QA generation. Additionally, creating figures directly using LLMs often encounters issues such as code errors, similar-looking figures, and repetitive content in figures. To address this issue, we present SBSFigures (Stage-by-Stage Synthetic Figures), a dataset for pre-training figure QA. Our proposed pipeline enables the creation of chart figures with complete annotations of the visualized data and dense QA annotations without any manual annotation process. Our stage-by-stage pipeline makes it possible to create diverse topic and appearance figures efficiently while minimizing code errors. Our SBSFigures demonstrate a strong pre-training effect, making it possible to achieve efficient training with a limited amount of real-world chart data starting from our pre-trained weights.
SciPostLayout: A Dataset for Layout Analysis and Layout Generation of Scientific Posters
Jul 29, 2024Scientific posters are used to present the contributions of scientific papers effectively in a graphical format. However, creating a well-designed poster that efficiently summarizes the core of a paper is both labor-intensive and time-consuming. A system that can automatically generate well-designed posters from scientific papers would reduce the workload of authors and help readers understand the outline of the paper visually. Despite the demand for poster generation systems, only a limited research has been conduced due to the lack of publicly available datasets. Thus, in this study, we built the SciPostLayout dataset, which consists of 7,855 scientific posters and manual layout annotations for layout analysis and generation. SciPostLayout also contains 100 scientific papers paired with the posters. All of the posters and papers in our dataset are under the CC-BY license and are publicly available. As benchmark tests for the collected dataset, we conducted experiments for layout analysis and generation utilizing existing computer vision models and found that both layout analysis and generation of posters using SciPostLayout are more challenging than with scientific papers. We also conducted experiments on generating layouts from scientific papers to demonstrate the potential of utilizing LLM as a scientific poster generation system. The dataset is publicly available at https://huggingface.co/datasets/omron-sinicx/scipostlayout_v2. The code is also publicly available at https://github.com/omron-sinicx/scipostlayout.
Vision-Language Interpreter for Robot Task Planning
Nov 02, 2023Large language models (LLMs) are accelerating the development of language-guided robot planners. Meanwhile, symbolic planners offer the advantage of interpretability. This paper proposes a new task that bridges these two trends, namely, multimodal planning problem specification. The aim is to generate a problem description (PD), a machine-readable file used by the planners to find a plan. By generating PDs from language instruction and scene observation, we can drive symbolic planners in a language-guided framework. We propose a Vision-Language Interpreter (ViLaIn), a new framework that generates PDs using state-of-the-art LLM and vision-language models. ViLaIn can refine generated PDs via error message feedback from the symbolic planner. Our aim is to answer the question: How accurately can ViLaIn and the symbolic planner generate valid robot plans? To evaluate ViLaIn, we introduce a novel dataset called the problem description generation (ProDG) dataset. The framework is evaluated with four new evaluation metrics. Experimental results show that ViLaIn can generate syntactically correct problems with more than 99% accuracy and valid plans with more than 58% accuracy.
Whats New? Identifying the Unfolding of New Events in Narratives
Feb 20, 2023
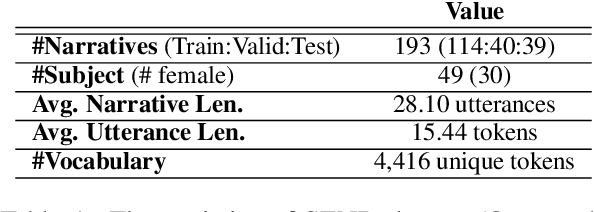
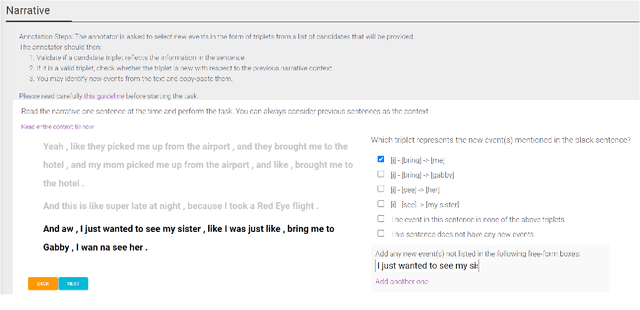
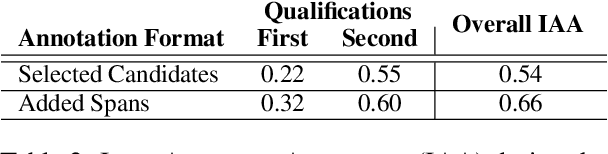
Narratives include a rich source of events unfolding over time and context. Automatic understanding of these events may provide a summarised comprehension of the narrative for further computation (such as reasoning). In this paper, we study the Information Status (IS) of the events and propose a novel challenging task: the automatic identification of new events in a narrative. We define an event as a triplet of subject, predicate, and object. The event is categorized as new with respect to the discourse context and whether it can be inferred through commonsense reasoning. We annotated a publicly available corpus of narratives with the new events at sentence level using human annotators. We present the annotation protocol and a study aiming at validating the quality of the annotation and the difficulty of the task. We publish the annotated dataset, annotation materials, and machine learning baseline models for the task of new event extraction for narrative understanding.
ARTA: Collection and Classification of Ambiguous Requests and Thoughtful Actions
Jun 15, 2021



Human-assisting systems such as dialogue systems must take thoughtful, appropriate actions not only for clear and unambiguous user requests, but also for ambiguous user requests, even if the users themselves are not aware of their potential requirements. To construct such a dialogue agent, we collected a corpus and developed a model that classifies ambiguous user requests into corresponding system actions. In order to collect a high-quality corpus, we asked workers to input antecedent user requests whose pre-defined actions could be regarded as thoughtful. Although multiple actions could be identified as thoughtful for a single user request, annotating all combinations of user requests and system actions is impractical. For this reason, we fully annotated only the test data and left the annotation of the training data incomplete. In order to train the classification model on such training data, we applied the positive/unlabeled (PU) learning method, which assumes that only a part of the data is labeled with positive examples. The experimental results show that the PU learning method achieved better performance than the general positive/negative (PN) learning method to classify thoughtful actions given an ambiguous user request.
Conversational Response Re-ranking Based on Event Causality and Role Factored Tensor Event Embedding
Jun 24, 2019


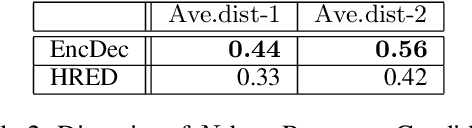
We propose a novel method for selecting coherent and diverse responses for a given dialogue context. The proposed method re-ranks response candidates generated from conversational models by using event causality relations between events in a dialogue history and response candidates (e.g., ``be stressed out'' precedes ``relieve stress''). We use distributed event representation based on the Role Factored Tensor Model for a robust matching of event causality relations due to limited event causality knowledge of the system. Experimental results showed that the proposed method improved coherency and dialogue continuity of system responses.