 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKeyMPs: One-Shot Vision-Language Guided Motion Generation by Sequencing DMPs for Occlusion-Rich Tasks
Apr 14, 2025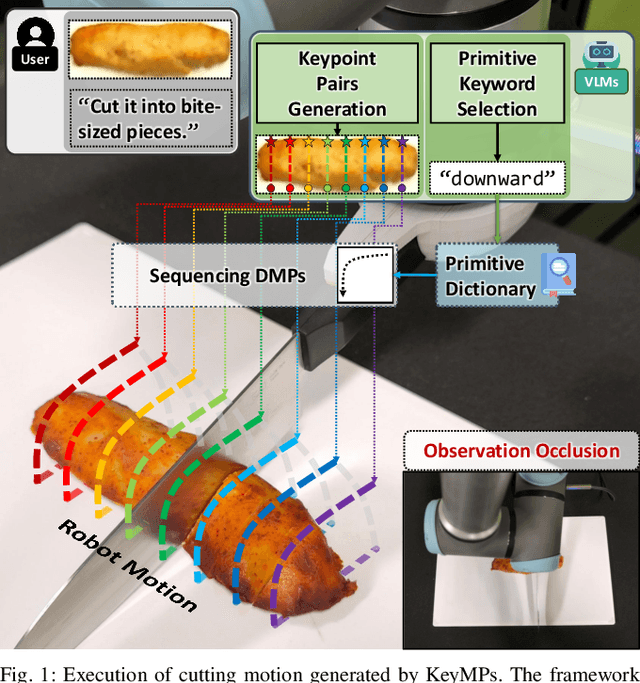
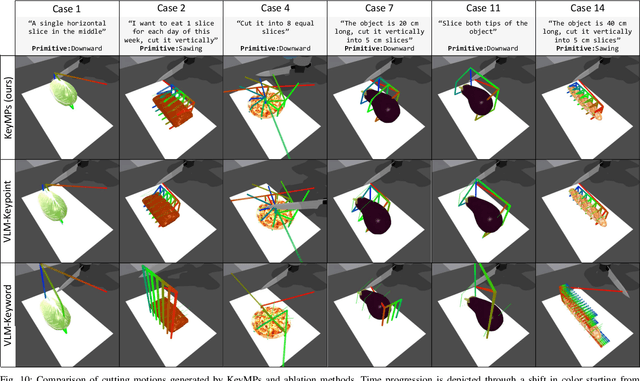
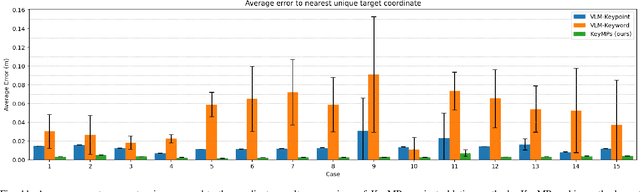
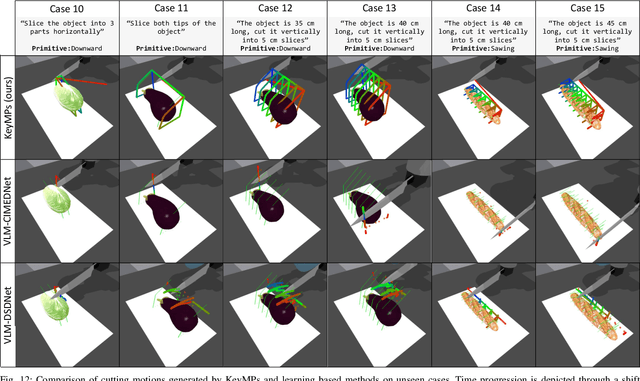
Dynamic Movement Primitives (DMPs) provide a flexible framework wherein smooth robotic motions are encoded into modular parameters. However, they face challenges in integrating multimodal inputs commonly used in robotics like vision and language into their framework. To fully maximize DMPs' potential, enabling them to handle multimodal inputs is essential. In addition, we also aim to extend DMPs' capability to handle object-focused tasks requiring one-shot complex motion generation, as observation occlusion could easily happen mid-execution in such tasks (e.g., knife occlusion in cake icing, hand occlusion in dough kneading, etc.). A promising approach is to leverage Vision-Language Models (VLMs), which process multimodal data and can grasp high-level concepts. However, they typically lack enough knowledge and capabilities to directly infer low-level motion details and instead only serve as a bridge between high-level instructions and low-level control. To address this limitation, we propose Keyword Labeled Primitive Selection and Keypoint Pairs Generation Guided Movement Primitives (KeyMPs), a framework that combines VLMs with sequencing of DMPs. KeyMPs use VLMs' high-level reasoning capability to select a reference primitive through keyword labeled primitive selection and VLMs' spatial awareness to generate spatial scaling parameters used for sequencing DMPs by generalizing the overall motion through keypoint pairs generation, which together enable one-shot vision-language guided motion generation that aligns with the intent expressed in the multimodal input. We validate our approach through an occlusion-rich manipulation task, specifically object cutting experiments in both simulated and real-world environments, demonstrating superior performance over other DMP-based methods that integrate VLMs support.
BEAC: Imitating Complex Exploration and Task-oriented Behaviors for Invisible Object Nonprehensile Manipulation
Mar 21, 2025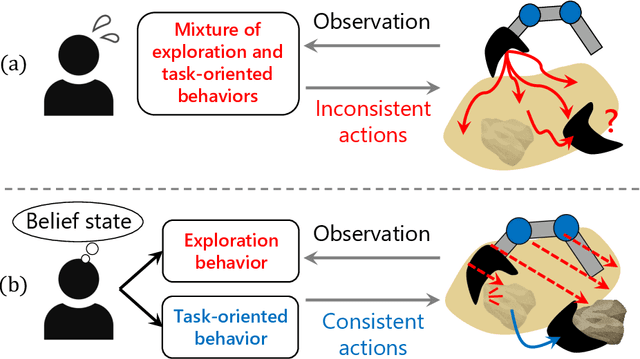
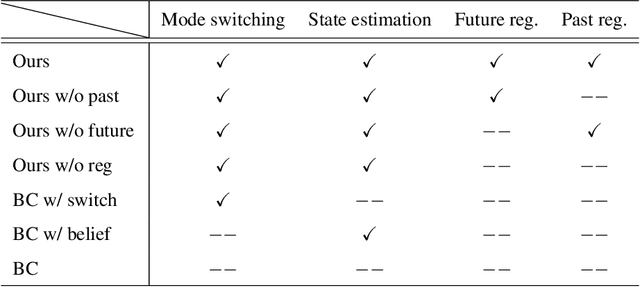
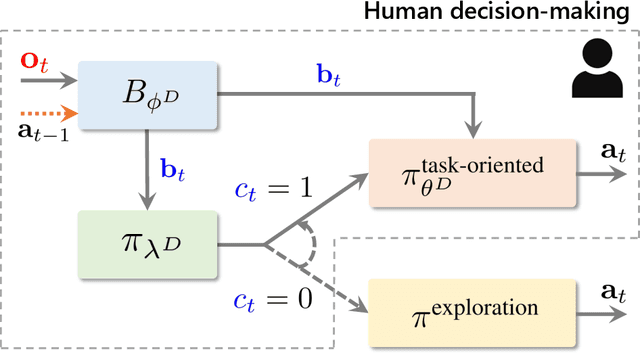
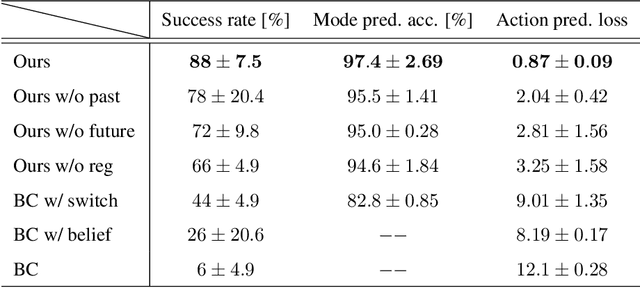
Applying imitation learning (IL) is challenging to nonprehensile manipulation tasks of invisible objects with partial observations, such as excavating buried rocks. The demonstrator must make such complex action decisions as exploring to find the object and task-oriented actions to complete the task while estimating its hidden state, perhaps causing inconsistent action demonstration and high cognitive load problems. For these problems, work in human cognitive science suggests that promoting the use of pre-designed, simple exploration rules for the demonstrator may alleviate the problems of action inconsistency and high cognitive load. Therefore, when performing imitation learning from demonstrations using such exploration rules, it is important to accurately imitate not only the demonstrator's task-oriented behavior but also his/her mode-switching behavior (exploratory or task-oriented behavior) under partial observation. Based on the above considerations, this paper proposes a novel imitation learning framework called Belief Exploration-Action Cloning (BEAC), which has a switching policy structure between a pre-designed exploration policy and a task-oriented action policy trained on the estimated belief states based on past history. In simulation and real robot experiments, we confirmed that our proposed method achieved the best task performance, higher mode and action prediction accuracies, while reducing the cognitive load in the demonstration indicated by a user study.
Progressive-Resolution Policy Distillation: Leveraging Coarse-Resolution Simulation for Time-Efficient Fine-Resolution Policy Learning
Dec 10, 2024



In earthwork and construction, excavators often encounter large rocks mixed with various soil conditions, requiring skilled operators. This paper presents a framework for achieving autonomous excavation using reinforcement learning (RL) through a rock excavation simulator. In the simulation, resolution can be defined by the particle size/number in the whole soil space. Fine-resolution simulations closely mimic real-world behavior but demand significant calculation time and challenging sample collection, while coarse-resolution simulations enable faster sample collection but deviate from real-world behavior. To combine the advantages of both resolutions, we explore using policies developed in coarse-resolution simulations for pre-training in fine-resolution simulations. To this end, we propose a novel policy learning framework called Progressive-Resolution Policy Distillation (PRPD), which progressively transfers policies through some middle-resolution simulations with conservative policy transfer to avoid domain gaps that could lead to policy transfer failure. Validation in a rock excavation simulator and nine real-world rock environments demonstrated that PRPD reduced sampling time to less than 1/7 while maintaining task success rates comparable to those achieved through policy learning in a fine-resolution simulation.
Deep Segmented DMP Networks for Learning Discontinuous Motions
Sep 01, 2023



Discontinuous motion which is a motion composed of multiple continuous motions with sudden change in direction or velocity in between, can be seen in state-aware robotic tasks. Such robotic tasks are often coordinated with sensor information such as image. In recent years, Dynamic Movement Primitives (DMP) which is a method for generating motor behaviors suitable for robotics has garnered several deep learning based improvements to allow associations between sensor information and DMP parameters. While the implementation of deep learning framework does improve upon DMP's inability to directly associate to an input, we found that it has difficulty learning DMP parameters for complex motion which requires large number of basis functions to reconstruct. In this paper we propose a novel deep learning network architecture called Deep Segmented DMP Network (DSDNet) which generates variable-length segmented motion by utilizing the combination of multiple DMP parameters predicting network architecture, double-stage decoder network, and number of segments predictor. The proposed method is evaluated on both artificial data (object cutting & pick-and-place) and real data (object cutting) where our proposed method could achieve high generalization capability, task-achievement, and data-efficiency compared to previous method on generating discontinuous long-horizon motions.
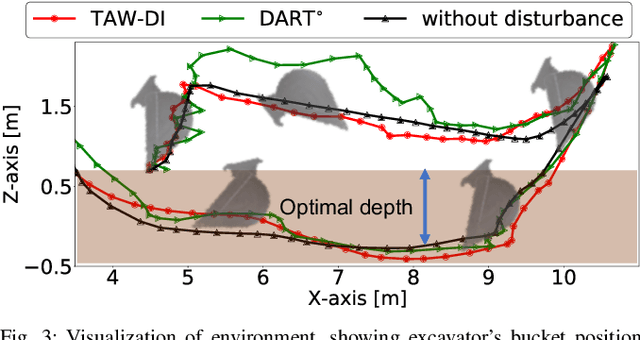
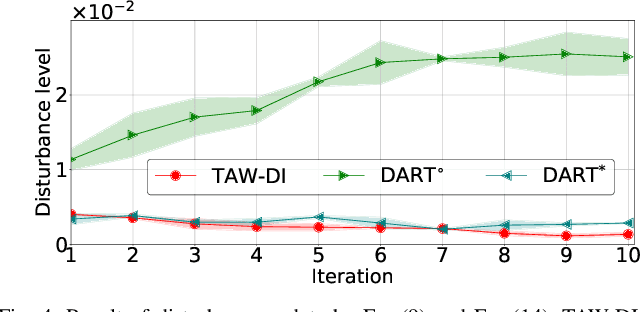
Disturbance Injection under Partial Automation: Robust Imitation Learning for Long-horizon Tasks
Mar 22, 2023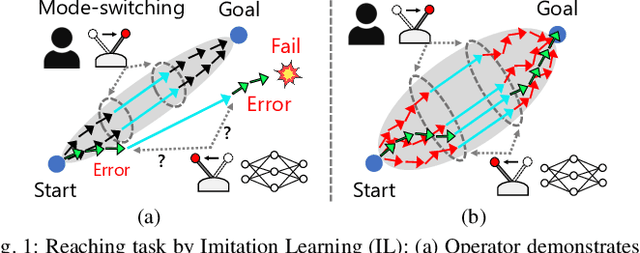
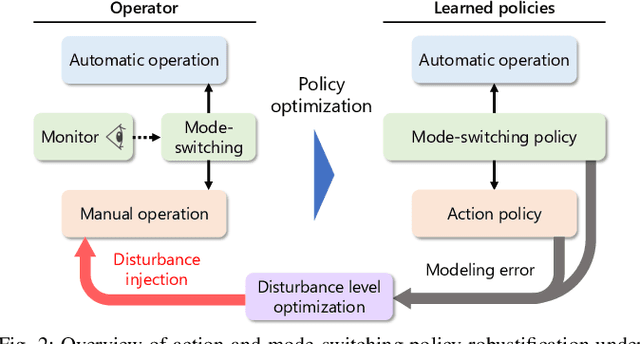
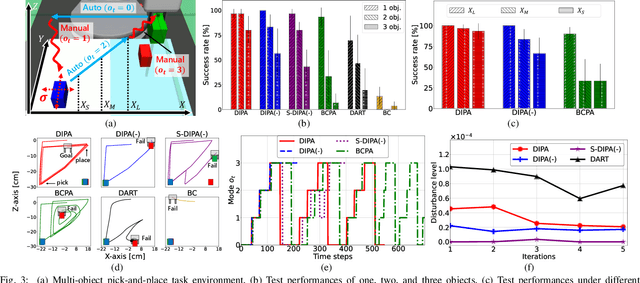
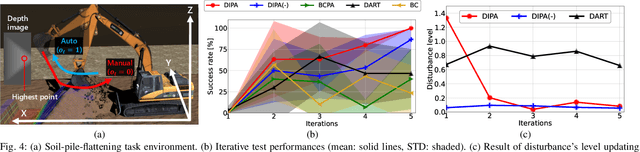
Partial Automation (PA) with intelligent support systems has been introduced in industrial machinery and advanced automobiles to reduce the burden of long hours of human operation. Under PA, operators perform manual operations (providing actions) and operations that switch to automatic/manual mode (mode-switching). Since PA reduces the total duration of manual operation, these two action and mode-switching operations can be replicated by imitation learning with high sample efficiency. To this end, this paper proposes Disturbance Injection under Partial Automation (DIPA) as a novel imitation learning framework. In DIPA, mode and actions (in the manual mode) are assumed to be observables in each state and are used to learn both action and mode-switching policies. The above learning is robustified by injecting disturbances into the operator's actions to optimize the disturbance's level for minimizing the covariate shift under PA. We experimentally validated the effectiveness of our method for long-horizon tasks in two simulations and a real robot environment and confirmed that our method outperformed the previous methods and reduced the demonstration burden.
Disturbance-Injected Robust Imitation Learning with Task Achievement
May 09, 2022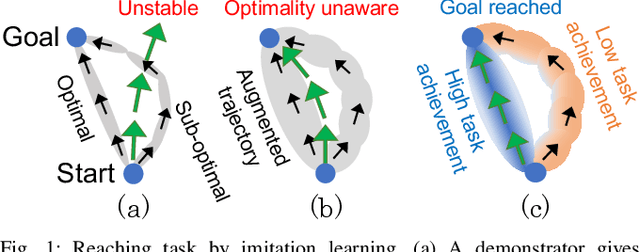

Robust imitation learning using disturbance injections overcomes issues of limited variation in demonstrations. However, these methods assume demonstrations are optimal, and that policy stabilization can be learned via simple augmentations. In real-world scenarios, demonstrations are often of diverse-quality, and disturbance injection instead learns sub-optimal policies that fail to replicate desired behavior. To address this issue, this paper proposes a novel imitation learning framework that combines both policy robustification and optimal demonstration learning. Specifically, this combinatorial approach forces policy learning and disturbance injection optimization to focus on mainly learning from high task achievement demonstrations, while utilizing low achievement ones to decrease the number of samples needed. The effectiveness of the proposed method is verified through experiments using an excavation task in both simulations and a real robot, resulting in high-achieving policies that are more stable and robust to diverse-quality demonstrations. In addition, this method utilizes all of the weighted sub-optimal demonstrations without eliminating them, resulting in practical data efficiency benefits.