 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTask-Relevant and Irrelevant Region-Aware Augmentation for Generalizable Vision-Based Imitation Learning in Agricultural Manipulation
Mar 05, 2026Vision-based imitation learning has shown promise for robotic manipulation; however, its generalization remains limited in practical agricultural tasks. This limitation stems from scarce demonstration data and substantial visual domain gaps caused by i) crop-specific appearance diversity and ii) background variations. To address this limitation, we propose Dual-Region Augmentation for Imitation Learning (DRAIL), a region-aware augmentation framework designed for generalizable vision-based imitation learning in agricultural manipulation. DRAIL explicitly separates visual observations into task-relevant and task-irrelevant regions. The task-relevant region is augmented in a domain-knowledge-driven manner to preserve essential visual characteristics, while the task-irrelevant region is aggressively randomized to suppress spurious background correlations. By jointly handling both sources of visual variation, DRAIL promotes learning policies that rely on task-essential features rather than incidental visual cues. We evaluate DRAIL on diffusion policy-based visuomotor controllers through robot experiments on artificial vegetable harvesting and real lettuce defective leaf picking preparation tasks. The results show consistent improvements in success rates under unseen visual conditions compared to baseline methods. Further attention analysis and representation generalization metrics indicate that the learned policies rely more on task-essential visual features, resulting in enhanced robustness and generalization.
Robotic System for Chemical Experiment Automation with Dual Demonstration of End-effector and Jig Operations
Jun 13, 2025While robotic automation has demonstrated remarkable performance, such as executing hundreds of experiments continuously over several days, it is challenging to design a program that synchronizes the robot's movements with the experimental jigs to conduct an experiment. We propose a concept that enables the automation of experiments by utilizing dual demonstrations of robot motions and jig operations by chemists in an experimental environment constructed to be controlled by a robot. To verify this concept, we developed a chemical-experiment-automation system consisting of jigs to assist the robot in experiments, a motion-demonstration interface, a jig-control interface, and a mobile manipulator. We validate the concept through polymer-synthesis experiments, focusing on critical liquid-handling tasks such as pipetting and dilution. The experimental results indicate high reproducibility of the demonstrated motions and robust task-success rates. This comprehensive concept not only simplifies the robot programming process for chemists but also provides a flexible and efficient solution to accommodate a wide range of experimental conditions, contributing significantly to the field of chemical experiment automation.
Feasibility-aware Imitation Learning from Observations through a Hand-mounted Demonstration Interface
Mar 12, 2025Imitation learning through a demonstration interface is expected to learn policies for robot automation from intuitive human demonstrations. However, due to the differences in human and robot movement characteristics, a human expert might unintentionally demonstrate an action that the robot cannot execute. We propose feasibility-aware behavior cloning from observation (FABCO). In the FABCO framework, the feasibility of each demonstration is assessed using the robot's pre-trained forward and inverse dynamics models. This feasibility information is provided as visual feedback to the demonstrators, encouraging them to refine their demonstrations. During policy learning, estimated feasibility serves as a weight for the demonstration data, improving both the data efficiency and the robustness of the learned policy. We experimentally validated FABCO's effectiveness by applying it to a pipette insertion task involving a pipette and a vial. Four participants assessed the impact of the feasibility feedback and the weighted policy learning in FABCO. Additionally, we used the NASA Task Load Index (NASA-TLX) to evaluate the workload induced by demonstrations with visual feedback.
Composite Gaussian Processes Flows for Learning Discontinuous Multimodal Policies
Feb 04, 2025Learning control policies for real-world robotic tasks often involve challenges such as multimodality, local discontinuities, and the need for computational efficiency. These challenges arise from the complexity of robotic environments, where multiple solutions may coexist. To address these issues, we propose Composite Gaussian Processes Flows (CGP-Flows), a novel semi-parametric model for robotic policy. CGP-Flows integrate Overlapping Mixtures of Gaussian Processes (OMGPs) with the Continuous Normalizing Flows (CNFs), enabling them to model complex policies addressing multimodality and local discontinuities. This hybrid approach retains the computational efficiency of OMGPs while incorporating the flexibility of CNFs. Experiments conducted in both simulated and real-world robotic tasks demonstrate that CGP-flows significantly improve performance in modeling control policies. In a simulation task, we confirmed that CGP-Flows had a higher success rate compared to the baseline method, and the success rate of GCP-Flow was significantly different from the success rate of other baselines in chi-square tests.
Disturbance Injection under Partial Automation: Robust Imitation Learning for Long-horizon Tasks
Mar 22, 2023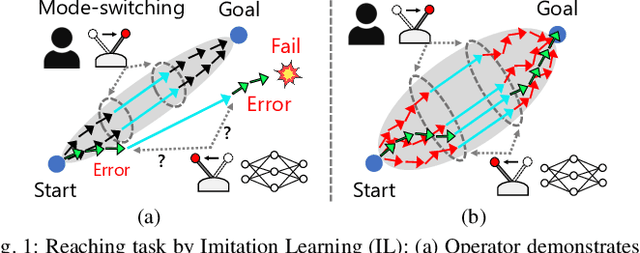
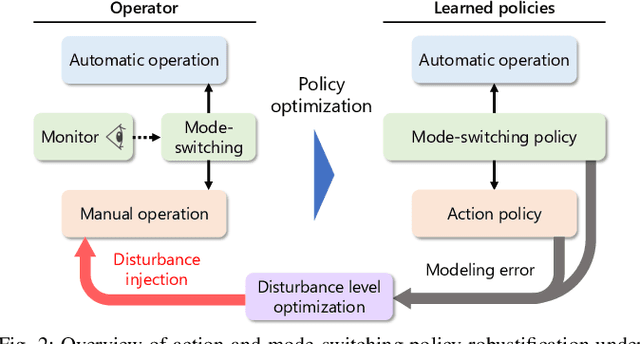
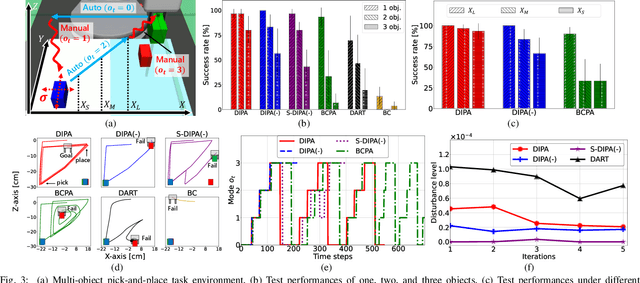
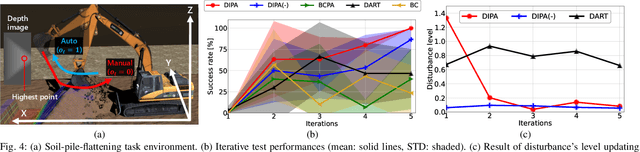
Partial Automation (PA) with intelligent support systems has been introduced in industrial machinery and advanced automobiles to reduce the burden of long hours of human operation. Under PA, operators perform manual operations (providing actions) and operations that switch to automatic/manual mode (mode-switching). Since PA reduces the total duration of manual operation, these two action and mode-switching operations can be replicated by imitation learning with high sample efficiency. To this end, this paper proposes Disturbance Injection under Partial Automation (DIPA) as a novel imitation learning framework. In DIPA, mode and actions (in the manual mode) are assumed to be observables in each state and are used to learn both action and mode-switching policies. The above learning is robustified by injecting disturbances into the operator's actions to optimize the disturbance's level for minimizing the covariate shift under PA. We experimentally validated the effectiveness of our method for long-horizon tasks in two simulations and a real robot environment and confirmed that our method outperformed the previous methods and reduced the demonstration burden.
Bayesian Disturbance Injection: Robust Imitation Learning of Flexible Policies for Robot Manipulation
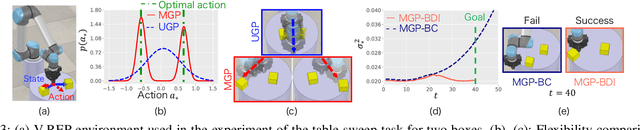
Nov 07, 2022Humans demonstrate a variety of interesting behavioral characteristics when performing tasks, such as selecting between seemingly equivalent optimal actions, performing recovery actions when deviating from the optimal trajectory, or moderating actions in response to sensed risks. However, imitation learning, which attempts to teach robots to perform these same tasks from observations of human demonstrations, often fails to capture such behavior. Specifically, commonly used learning algorithms embody inherent contradictions between the learning assumptions (e.g., single optimal action) and actual human behavior (e.g., multiple optimal actions), thereby limiting robot generalizability, applicability, and demonstration feasibility. To address this, this paper proposes designing imitation learning algorithms with a focus on utilizing human behavioral characteristics, thereby embodying principles for capturing and exploiting actual demonstrator behavioral characteristics. This paper presents the first imitation learning framework, Bayesian Disturbance Injection (BDI), that typifies human behavioral characteristics by incorporating model flexibility, robustification, and risk sensitivity. Bayesian inference is used to learn flexible non-parametric multi-action policies, while simultaneously robustifying policies by injecting risk-sensitive disturbances to induce human recovery action and ensuring demonstration feasibility. Our method is evaluated through risk-sensitive simulations and real-robot experiments (e.g., table-sweep task, shaft-reach task and shaft-insertion task) using the UR5e 6-DOF robotic arm, to demonstrate the improved characterisation of behavior. Results show significant improvement in task performance, through improved flexibility, robustness as well as demonstration feasibility.
Disturbance-Injected Robust Imitation Learning with Task Achievement
May 09, 2022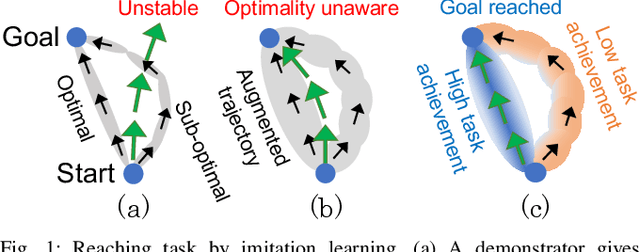

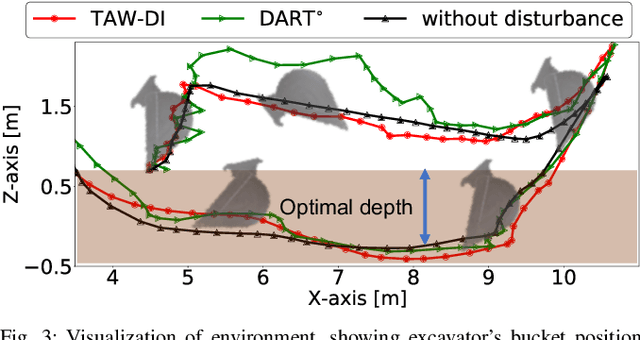
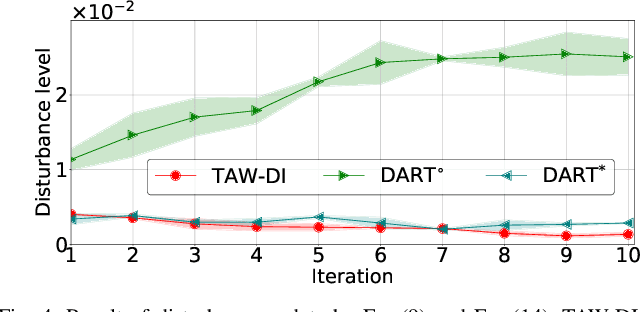
Robust imitation learning using disturbance injections overcomes issues of limited variation in demonstrations. However, these methods assume demonstrations are optimal, and that policy stabilization can be learned via simple augmentations. In real-world scenarios, demonstrations are often of diverse-quality, and disturbance injection instead learns sub-optimal policies that fail to replicate desired behavior. To address this issue, this paper proposes a novel imitation learning framework that combines both policy robustification and optimal demonstration learning. Specifically, this combinatorial approach forces policy learning and disturbance injection optimization to focus on mainly learning from high task achievement demonstrations, while utilizing low achievement ones to decrease the number of samples needed. The effectiveness of the proposed method is verified through experiments using an excavation task in both simulations and a real robot, resulting in high-achieving policies that are more stable and robust to diverse-quality demonstrations. In addition, this method utilizes all of the weighted sub-optimal demonstrations without eliminating them, resulting in practical data efficiency benefits.
Gaussian Process Self-triggered Policy Search in Weakly Observable Environments
May 07, 2022
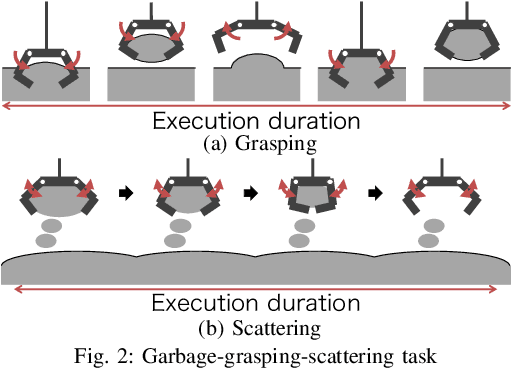
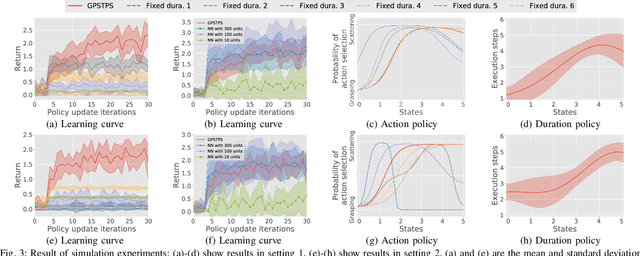

The environments of such large industrial machines as waste cranes in waste incineration plants are often weakly observable, where little information about the environmental state is contained in the observations due to technical difficulty or maintenance cost (e.g., no sensors for observing the state of the garbage to be handled). Based on the findings that skilled operators in such environments choose predetermined control strategies (e.g., grasping and scattering) and their durations based on sensor values, %thereby improving the robustness of their actions, we propose a novel non-parametric policy search algorithm: Gaussian process self-triggered policy search (GPSTPS). GPSTPS has two types of control policies: action and duration. A gating mechanism either maintains the action selected by the action policy for the duration specified by the duration policy or updates the action and duration by passing new observations to the policy; therefore, it is categorized as self-triggered. GPSTPS simultaneously learns both policies by trial and error based on sparse GP priors and variational learning to maximize the return. To verify the performance of our proposed method, we conducted experiments on garbage-grasping-scattering task for a waste crane with weak observations using a simulation and a robotic waste crane system. As experimental results, the proposed method acquired suitable policies to determine the action and duration based on the garbage's characteristics.
Variational Policy Search using Sparse Gaussian Process Priors for Learning Multimodal Optimal Actions
Jun 14, 2021



Policy search reinforcement learning has been drawing much attention as a method of learning a robot control policy. In particular, policy search using such non-parametric policies as Gaussian process regression can learn optimal actions with high-dimensional and redundant sensors as input. However, previous methods implicitly assume that the optimal action becomes unique for each state. This assumption can severely limit such practical applications as robot manipulations since designing a reward function that appears in only one optimal action for complex tasks is difficult. The previous methods might have caused critical performance deterioration because the typical non-parametric policies cannot capture the optimal actions due to their unimodality. We propose novel approaches in non-parametric policy searches with multiple optimal actions and offer two different algorithms commonly based on a sparse Gaussian process prior and variational Bayesian inference. The following are the key ideas: 1) multimodality for capturing multiple optimal actions and 2) mode-seeking for capturing one optimal action by ignoring the others. First, we propose a multimodal sparse Gaussian process policy search that uses multiple overlapped GPs as a prior. Second, we propose a mode-seeking sparse Gaussian process policy search that uses the student-t distribution for a likelihood function. The effectiveness of those algorithms is demonstrated through applications to object manipulation tasks with multiple optimal actions in simulations.
Bayesian Disturbance Injection: Robust Imitation Learning of Flexible Policies
Mar 27, 2021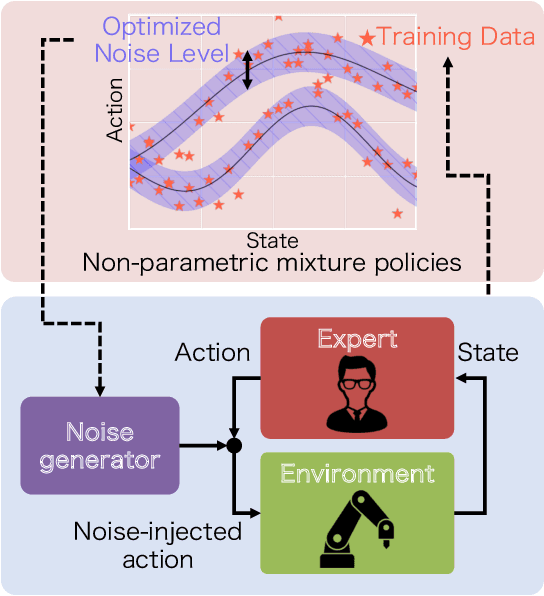
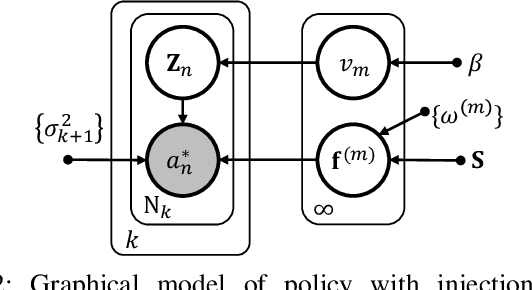

Scenarios requiring humans to choose from multiple seemingly optimal actions are commonplace, however standard imitation learning often fails to capture this behavior. Instead, an over-reliance on replicating expert actions induces inflexible and unstable policies, leading to poor generalizability in an application. To address the problem, this paper presents the first imitation learning framework that incorporates Bayesian variational inference for learning flexible non-parametric multi-action policies, while simultaneously robustifying the policies against sources of error, by introducing and optimizing disturbances to create a richer demonstration dataset. This combinatorial approach forces the policy to adapt to challenging situations, enabling stable multi-action policies to be learned efficiently. The effectiveness of our proposed method is evaluated through simulations and real-robot experiments for a table-sweep task using the UR3 6-DOF robotic arm. Results show that, through improved flexibility and robustness, the learning performance and control safety are better than comparison methods.