 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBayesian Disturbance Injection: Robust Imitation Learning of Flexible Policies for Robot Manipulation
Nov 07, 2022Humans demonstrate a variety of interesting behavioral characteristics when performing tasks, such as selecting between seemingly equivalent optimal actions, performing recovery actions when deviating from the optimal trajectory, or moderating actions in response to sensed risks. However, imitation learning, which attempts to teach robots to perform these same tasks from observations of human demonstrations, often fails to capture such behavior. Specifically, commonly used learning algorithms embody inherent contradictions between the learning assumptions (e.g., single optimal action) and actual human behavior (e.g., multiple optimal actions), thereby limiting robot generalizability, applicability, and demonstration feasibility. To address this, this paper proposes designing imitation learning algorithms with a focus on utilizing human behavioral characteristics, thereby embodying principles for capturing and exploiting actual demonstrator behavioral characteristics. This paper presents the first imitation learning framework, Bayesian Disturbance Injection (BDI), that typifies human behavioral characteristics by incorporating model flexibility, robustification, and risk sensitivity. Bayesian inference is used to learn flexible non-parametric multi-action policies, while simultaneously robustifying policies by injecting risk-sensitive disturbances to induce human recovery action and ensuring demonstration feasibility. Our method is evaluated through risk-sensitive simulations and real-robot experiments (e.g., table-sweep task, shaft-reach task and shaft-insertion task) using the UR5e 6-DOF robotic arm, to demonstrate the improved characterisation of behavior. Results show significant improvement in task performance, through improved flexibility, robustness as well as demonstration feasibility.
Deep Koopman with Control: Spectral Analysis of Soft Robot Dynamics
Oct 14, 2022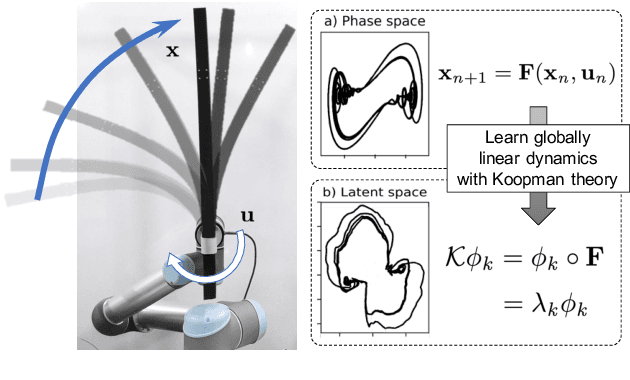
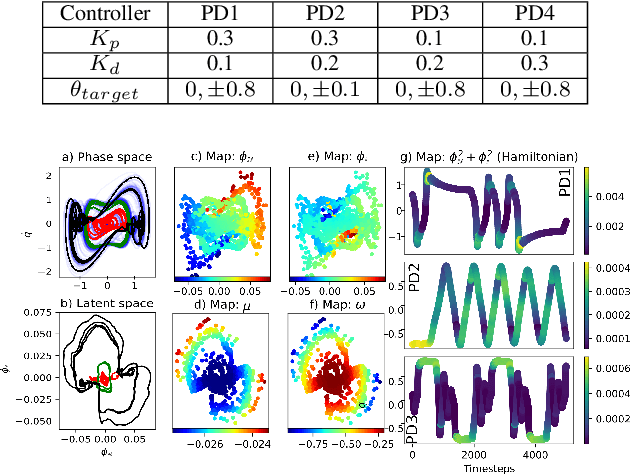
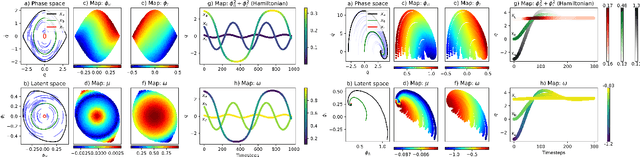

Soft robots are challenging to model and control as inherent non-linearities (e.g., elasticity and deformation), often requires complex explicit physics-based analytical modeling (e.g., a priori geometric definitions). While machine learning can be used to learn non-linear control models in a data-driven approach, these models often lack an intuitive internal physical interpretation and representation, limiting dynamical analysis. To address this, this paper presents an approach using Koopman operator theory and deep neural networks to provide a global linear description of the non-linear control systems. Specifically, by globally linearising dynamics, the Koopman operator is analyzed using spectral decomposition to characterises important physics-based interpretations, such as functional growths and oscillations. Experiments in this paper demonstrate this approach for controlling non-linear soft robotics, and shows model outputs are interpretable in the context of spectral analysis.
Disturbance-Injected Robust Imitation Learning with Task Achievement
May 09, 2022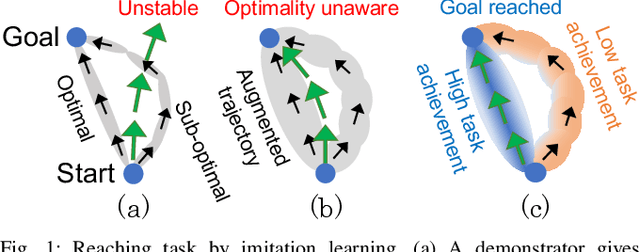

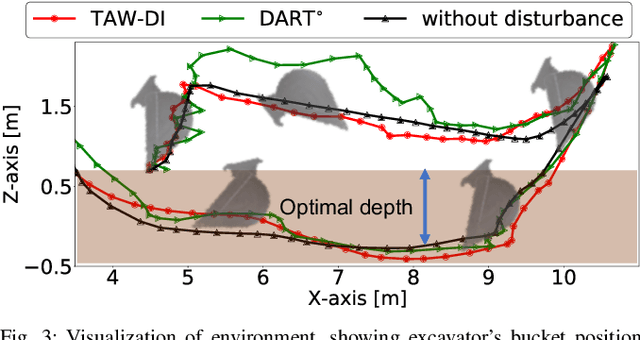
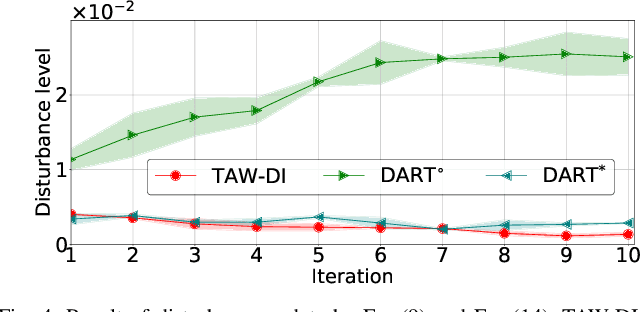
Robust imitation learning using disturbance injections overcomes issues of limited variation in demonstrations. However, these methods assume demonstrations are optimal, and that policy stabilization can be learned via simple augmentations. In real-world scenarios, demonstrations are often of diverse-quality, and disturbance injection instead learns sub-optimal policies that fail to replicate desired behavior. To address this issue, this paper proposes a novel imitation learning framework that combines both policy robustification and optimal demonstration learning. Specifically, this combinatorial approach forces policy learning and disturbance injection optimization to focus on mainly learning from high task achievement demonstrations, while utilizing low achievement ones to decrease the number of samples needed. The effectiveness of the proposed method is verified through experiments using an excavation task in both simulations and a real robot, resulting in high-achieving policies that are more stable and robust to diverse-quality demonstrations. In addition, this method utilizes all of the weighted sub-optimal demonstrations without eliminating them, resulting in practical data efficiency benefits.
Bayesian Disturbance Injection: Robust Imitation Learning of Flexible Policies
Mar 27, 2021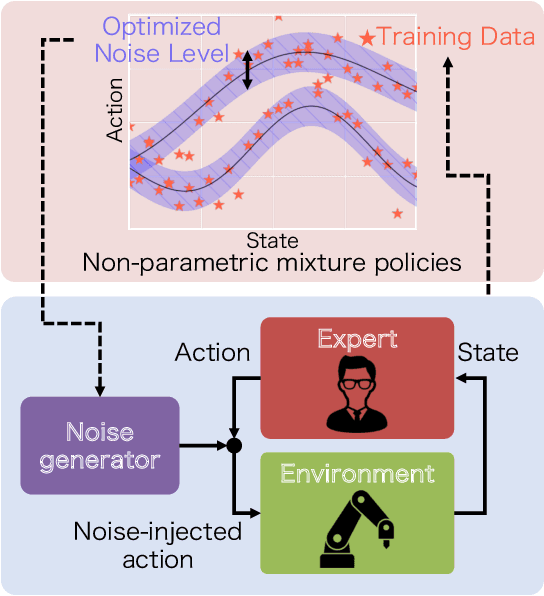
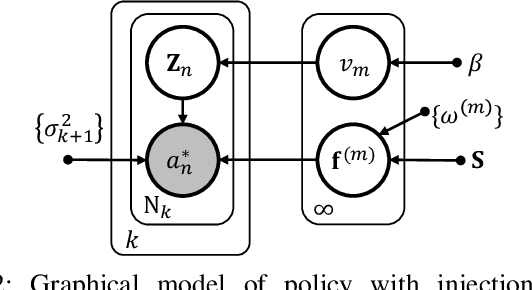

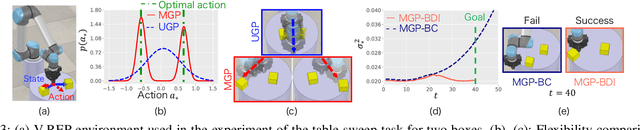
Scenarios requiring humans to choose from multiple seemingly optimal actions are commonplace, however standard imitation learning often fails to capture this behavior. Instead, an over-reliance on replicating expert actions induces inflexible and unstable policies, leading to poor generalizability in an application. To address the problem, this paper presents the first imitation learning framework that incorporates Bayesian variational inference for learning flexible non-parametric multi-action policies, while simultaneously robustifying the policies against sources of error, by introducing and optimizing disturbances to create a richer demonstration dataset. This combinatorial approach forces the policy to adapt to challenging situations, enabling stable multi-action policies to be learned efficiently. The effectiveness of our proposed method is evaluated through simulations and real-robot experiments for a table-sweep task using the UR3 6-DOF robotic arm. Results show that, through improved flexibility and robustness, the learning performance and control safety are better than comparison methods.
Improving Task-Parameterised Movement Learning Generalisation with Frame-Weighted Trajectory Generation
Mar 04, 2019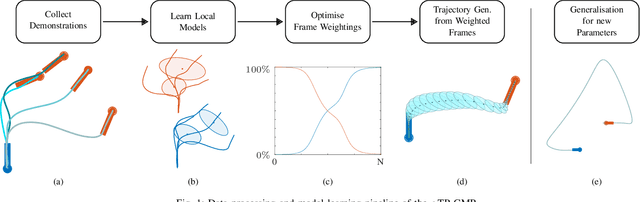
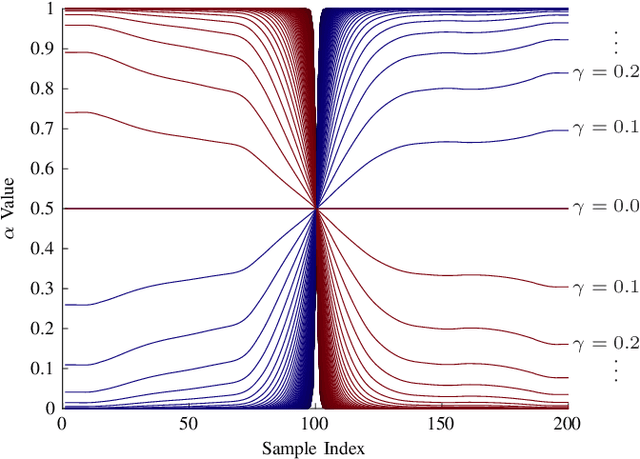
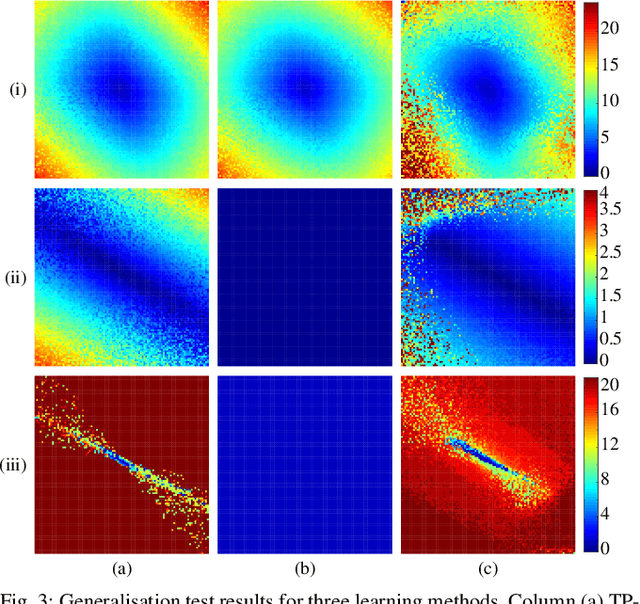

Learning from Demonstration depends on a robot learner generalising its learned model to unseen conditions, as it is not feasible for a person to provide a demonstration set that accounts for all possible variations in non-trivial tasks. While there are many learning methods that can handle interpolation of observed data effectively, extrapolation from observed data offers a much greater challenge. To address this problem of generalisation, this paper proposes a modified Task-Parameterised Gaussian Mixture Regression method that considers the relevance of task parameters during trajectory generation, as determined by variance in the data. The benefits of the proposed method are first explored using a simulated reaching task data set. Here it is shown that the proposed method offers far-reaching, low-error extrapolation abilities that are different in nature to existing learning methods. Data collected from novice users for a real-world manipulation task is then considered, where it is shown that the proposed method is able to effectively reduce grasping performance errors by ${\sim30\%}$ and extrapolate to unseen grasp targets under real-world conditions. These results indicate the proposed method serves to benefit novice users by placing less reliance on the user to provide high quality demonstration data sets.