 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Instant Policy: Leveraging Student's t-Regression Model for Robust In-context Imitation Learning of Robot Manipulation
Jun 18, 2025Imitation learning (IL) aims to enable robots to perform tasks autonomously by observing a few human demonstrations. Recently, a variant of IL, called In-Context IL, utilized off-the-shelf large language models (LLMs) as instant policies that understand the context from a few given demonstrations to perform a new task, rather than explicitly updating network models with large-scale demonstrations. However, its reliability in the robotics domain is undermined by hallucination issues such as LLM-based instant policy, which occasionally generates poor trajectories that deviate from the given demonstrations. To alleviate this problem, we propose a new robust in-context imitation learning algorithm called the robust instant policy (RIP), which utilizes a Student's t-regression model to be robust against the hallucinated trajectories of instant policies to allow reliable trajectory generation. Specifically, RIP generates several candidate robot trajectories to complete a given task from an LLM and aggregates them using the Student's t-distribution, which is beneficial for ignoring outliers (i.e., hallucinations); thereby, a robust trajectory against hallucinations is generated. Our experiments, conducted in both simulated and real-world environments, show that RIP significantly outperforms state-of-the-art IL methods, with at least $26\%$ improvement in task success rates, particularly in low-data scenarios for everyday tasks. Video results available at https://sites.google.com/view/robustinstantpolicy.
Leveraging Demonstrator-perceived Precision for Safe Interactive Imitation Learning of Clearance-limited Tasks
Feb 21, 2024



Interactive imitation learning is an efficient, model-free method through which a robot can learn a task by repetitively iterating an execution of a learning policy and a data collection by querying human demonstrations. However, deploying unmatured policies for clearance-limited tasks, like industrial insertion, poses significant collision risks. For such tasks, a robot should detect the collision risks and request intervention by ceding control to a human when collisions are imminent. The former requires an accurate model of the environment, a need that significantly limits the scope of IIL applications. In contrast, humans implicitly demonstrate environmental precision by adjusting their behavior to avoid collisions when performing tasks. Inspired by human behavior, this paper presents a novel interactive learning method that uses demonstrator-perceived precision as a criterion for human intervention called Demonstrator-perceived Precision-aware Interactive Imitation Learning (DPIIL). DPIIL captures precision by observing the speed-accuracy trade-off exhibited in human demonstrations and cedes control to a human to avoid collisions in states where high precision is estimated. DPIIL improves the safety of interactive policy learning and ensures efficiency without explicitly providing precise information of the environment. We assessed DPIIL's effectiveness through simulations and real-robot experiments that trained a UR5e 6-DOF robotic arm to perform assembly tasks. Our results significantly improved training safety, and our best performance compared favorably with other learning methods.
Disturbance Injection under Partial Automation: Robust Imitation Learning for Long-horizon Tasks
Mar 22, 2023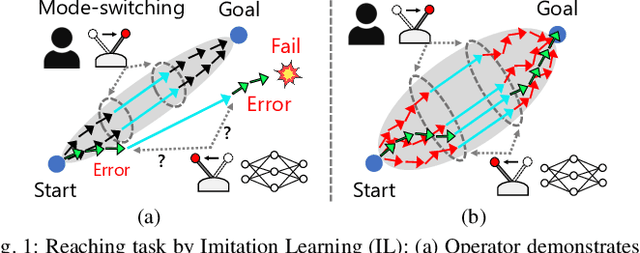
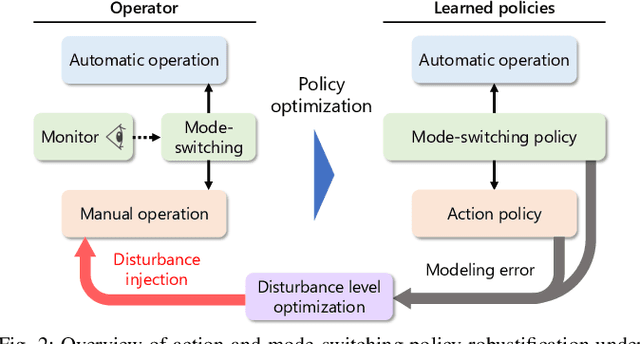
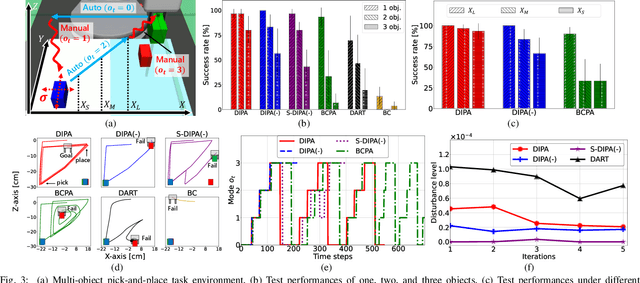
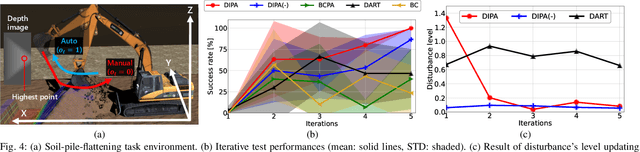
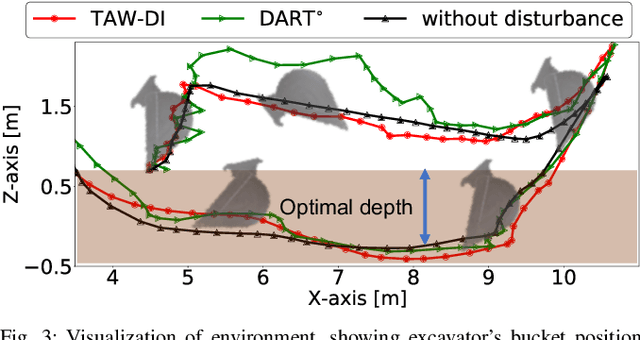
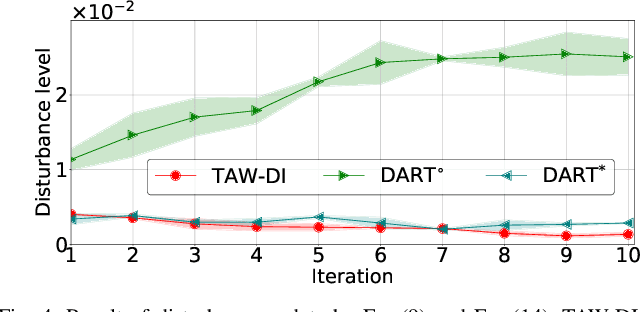
Partial Automation (PA) with intelligent support systems has been introduced in industrial machinery and advanced automobiles to reduce the burden of long hours of human operation. Under PA, operators perform manual operations (providing actions) and operations that switch to automatic/manual mode (mode-switching). Since PA reduces the total duration of manual operation, these two action and mode-switching operations can be replicated by imitation learning with high sample efficiency. To this end, this paper proposes Disturbance Injection under Partial Automation (DIPA) as a novel imitation learning framework. In DIPA, mode and actions (in the manual mode) are assumed to be observables in each state and are used to learn both action and mode-switching policies. The above learning is robustified by injecting disturbances into the operator's actions to optimize the disturbance's level for minimizing the covariate shift under PA. We experimentally validated the effectiveness of our method for long-horizon tasks in two simulations and a real robot environment and confirmed that our method outperformed the previous methods and reduced the demonstration burden.
Bayesian Disturbance Injection: Robust Imitation Learning of Flexible Policies for Robot Manipulation
Nov 07, 2022Humans demonstrate a variety of interesting behavioral characteristics when performing tasks, such as selecting between seemingly equivalent optimal actions, performing recovery actions when deviating from the optimal trajectory, or moderating actions in response to sensed risks. However, imitation learning, which attempts to teach robots to perform these same tasks from observations of human demonstrations, often fails to capture such behavior. Specifically, commonly used learning algorithms embody inherent contradictions between the learning assumptions (e.g., single optimal action) and actual human behavior (e.g., multiple optimal actions), thereby limiting robot generalizability, applicability, and demonstration feasibility. To address this, this paper proposes designing imitation learning algorithms with a focus on utilizing human behavioral characteristics, thereby embodying principles for capturing and exploiting actual demonstrator behavioral characteristics. This paper presents the first imitation learning framework, Bayesian Disturbance Injection (BDI), that typifies human behavioral characteristics by incorporating model flexibility, robustification, and risk sensitivity. Bayesian inference is used to learn flexible non-parametric multi-action policies, while simultaneously robustifying policies by injecting risk-sensitive disturbances to induce human recovery action and ensuring demonstration feasibility. Our method is evaluated through risk-sensitive simulations and real-robot experiments (e.g., table-sweep task, shaft-reach task and shaft-insertion task) using the UR5e 6-DOF robotic arm, to demonstrate the improved characterisation of behavior. Results show significant improvement in task performance, through improved flexibility, robustness as well as demonstration feasibility.
Disturbance-Injected Robust Imitation Learning with Task Achievement
May 09, 2022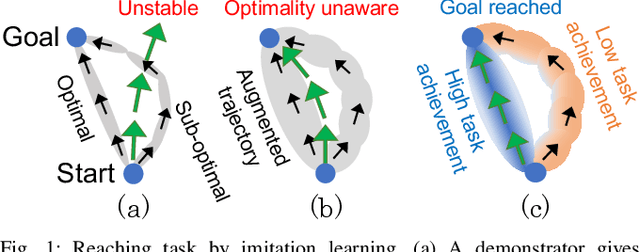

Robust imitation learning using disturbance injections overcomes issues of limited variation in demonstrations. However, these methods assume demonstrations are optimal, and that policy stabilization can be learned via simple augmentations. In real-world scenarios, demonstrations are often of diverse-quality, and disturbance injection instead learns sub-optimal policies that fail to replicate desired behavior. To address this issue, this paper proposes a novel imitation learning framework that combines both policy robustification and optimal demonstration learning. Specifically, this combinatorial approach forces policy learning and disturbance injection optimization to focus on mainly learning from high task achievement demonstrations, while utilizing low achievement ones to decrease the number of samples needed. The effectiveness of the proposed method is verified through experiments using an excavation task in both simulations and a real robot, resulting in high-achieving policies that are more stable and robust to diverse-quality demonstrations. In addition, this method utilizes all of the weighted sub-optimal demonstrations without eliminating them, resulting in practical data efficiency benefits.
Bayesian Disturbance Injection: Robust Imitation Learning of Flexible Policies
Mar 27, 2021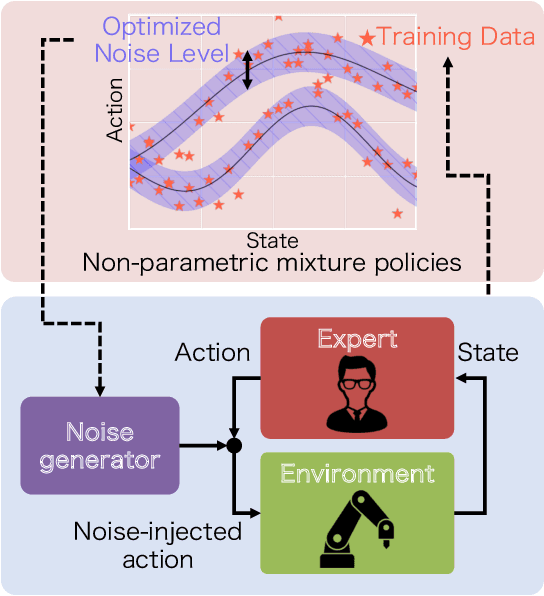
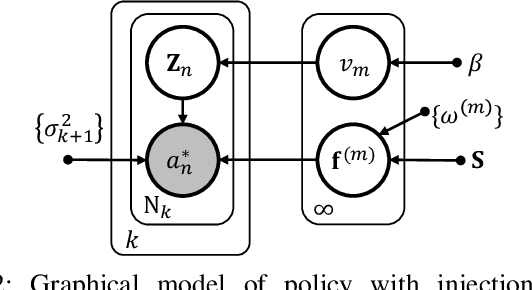

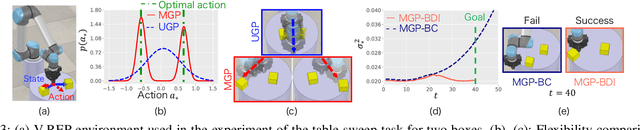
Scenarios requiring humans to choose from multiple seemingly optimal actions are commonplace, however standard imitation learning often fails to capture this behavior. Instead, an over-reliance on replicating expert actions induces inflexible and unstable policies, leading to poor generalizability in an application. To address the problem, this paper presents the first imitation learning framework that incorporates Bayesian variational inference for learning flexible non-parametric multi-action policies, while simultaneously robustifying the policies against sources of error, by introducing and optimizing disturbances to create a richer demonstration dataset. This combinatorial approach forces the policy to adapt to challenging situations, enabling stable multi-action policies to be learned efficiently. The effectiveness of our proposed method is evaluated through simulations and real-robot experiments for a table-sweep task using the UR3 6-DOF robotic arm. Results show that, through improved flexibility and robustness, the learning performance and control safety are better than comparison methods.