 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReplaceable Bit-based Gripper for Picking Cluttered Food Items
Jan 01, 2026The food packaging industry goes through changes in food items and their weights quite rapidly. These items range from easy-to-pick, single-piece food items to flexible, long and cluttered ones. We propose a replaceable bit-based gripper system to tackle the challenge of weight-based handling of cluttered food items. The gripper features specialized food attachments(bits) that enhance its grasping capabilities, and a belt replacement system allows switching between different food items during packaging operations. It offers a wide range of control options, enabling it to grasp and drop specific weights of granular, cluttered, and entangled foods. We specifically designed bits for two flexible food items that differ in shape: ikura(salmon roe) and spaghetti. They represent the challenging categories of sticky, granular food and long, sticky, cluttered food, respectively. The gripper successfully picked up both spaghetti and ikura and demonstrated weight-specific dropping of these items with an accuracy over 80% and 95% respectively. The gripper system also exhibited quick switching between different bits, leading to the handling of a large range of food items.
A Flexible Field-Based Policy Learning Framework for Diverse Robotic Systems and Sensors
Dec 22, 2025We present a cross robot visuomotor learning framework that integrates diffusion policy based control with 3D semantic scene representations from D3Fields to enable category level generalization in manipulation. Its modular design supports diverse robot camera configurations including UR5 arms with Microsoft Azure Kinect arrays and bimanual manipulators with Intel RealSense sensors through a low latency control stack and intuitive teleoperation. A unified configuration layer enables seamless switching between setups for flexible data collection training and evaluation. In a grasp and lift block task the framework achieved an 80 percent success rate after only 100 demonstration episodes demonstrating robust skill transfer between platforms and sensing modalities. This design paves the way for scalable real world studies in cross robotic generalization.
Visual Prompting for Robotic Manipulation with Annotation-Guided Pick-and-Place Using ACT
Aug 12, 2025Robotic pick-and-place tasks in convenience stores pose challenges due to dense object arrangements, occlusions, and variations in object properties such as color, shape, size, and texture. These factors complicate trajectory planning and grasping. This paper introduces a perception-action pipeline leveraging annotation-guided visual prompting, where bounding box annotations identify both pickable objects and placement locations, providing structured spatial guidance. Instead of traditional step-by-step planning, we employ Action Chunking with Transformers (ACT) as an imitation learning algorithm, enabling the robotic arm to predict chunked action sequences from human demonstrations. This facilitates smooth, adaptive, and data-driven pick-and-place operations. We evaluate our system based on success rate and visual analysis of grasping behavior, demonstrating improved grasp accuracy and adaptability in retail environments.
Robust Instant Policy: Leveraging Student's t-Regression Model for Robust In-context Imitation Learning of Robot Manipulation
Jun 18, 2025Imitation learning (IL) aims to enable robots to perform tasks autonomously by observing a few human demonstrations. Recently, a variant of IL, called In-Context IL, utilized off-the-shelf large language models (LLMs) as instant policies that understand the context from a few given demonstrations to perform a new task, rather than explicitly updating network models with large-scale demonstrations. However, its reliability in the robotics domain is undermined by hallucination issues such as LLM-based instant policy, which occasionally generates poor trajectories that deviate from the given demonstrations. To alleviate this problem, we propose a new robust in-context imitation learning algorithm called the robust instant policy (RIP), which utilizes a Student's t-regression model to be robust against the hallucinated trajectories of instant policies to allow reliable trajectory generation. Specifically, RIP generates several candidate robot trajectories to complete a given task from an LLM and aggregates them using the Student's t-distribution, which is beneficial for ignoring outliers (i.e., hallucinations); thereby, a robust trajectory against hallucinations is generated. Our experiments, conducted in both simulated and real-world environments, show that RIP significantly outperforms state-of-the-art IL methods, with at least $26\%$ improvement in task success rates, particularly in low-data scenarios for everyday tasks. Video results available at https://sites.google.com/view/robustinstantpolicy.
Learning Bimanual Manipulation via Action Chunking and Inter-Arm Coordination with Transformers
Mar 18, 2025Robots that can operate autonomously in a human living environment are necessary to have the ability to handle various tasks flexibly. One crucial element is coordinated bimanual movements that enable functions that are difficult to perform with one hand alone. In recent years, learning-based models that focus on the possibilities of bimanual movements have been proposed. However, the high degree of freedom of the robot makes it challenging to reason about control, and the left and right robot arms need to adjust their actions depending on the situation, making it difficult to realize more dexterous tasks. To address the issue, we focus on coordination and efficiency between both arms, particularly for synchronized actions. Therefore, we propose a novel imitation learning architecture that predicts cooperative actions. We differentiate the architecture for both arms and add an intermediate encoder layer, Inter-Arm Coordinated transformer Encoder (IACE), that facilitates synchronization and temporal alignment to ensure smooth and coordinated actions. To verify the effectiveness of our architectures, we perform distinctive bimanual tasks. The experimental results showed that our model demonstrated a high success rate for comparison and suggested a suitable architecture for the policy learning of bimanual manipulation.
SuctionPrompt: Visual-assisted Robotic Picking with a Suction Cup Using Vision-Language Models and Facile Hardware Design
Oct 31, 2024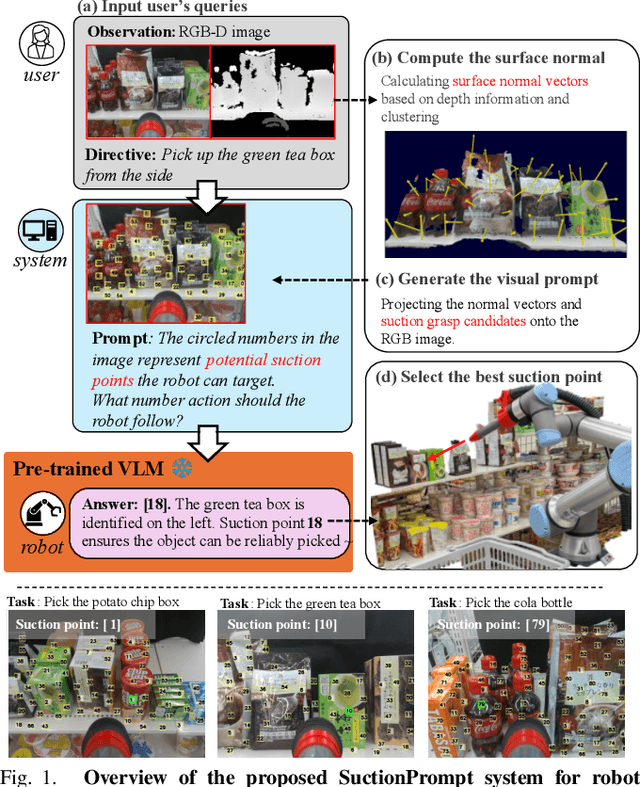
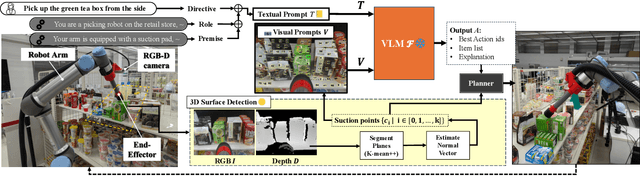
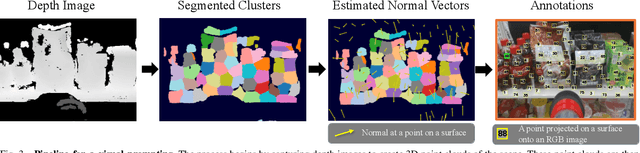
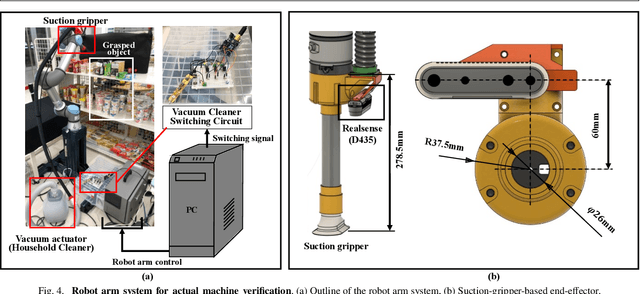
The development of large language models and vision-language models (VLMs) has resulted in the increasing use of robotic systems in various fields. However, the effective integration of these models into real-world robotic tasks is a key challenge. We developed a versatile robotic system called SuctionPrompt that utilizes prompting techniques of VLMs combined with 3D detections to perform product-picking tasks in diverse and dynamic environments. Our method highlights the importance of integrating 3D spatial information with adaptive action planning to enable robots to approach and manipulate objects in novel environments. In the validation experiments, the system accurately selected suction points 75.4%, and achieved a 65.0% success rate in picking common items. This study highlights the effectiveness of VLMs in robotic manipulation tasks, even with simple 3D processing.
Visual Imitation Learning of Non-Prehensile Manipulation Tasks with Dynamics-Supervised Models
Oct 25, 2024Unlike quasi-static robotic manipulation tasks like pick-and-place, dynamic tasks such as non-prehensile manipulation pose greater challenges, especially for vision-based control. Successful control requires the extraction of features relevant to the target task. In visual imitation learning settings, these features can be learnt by backpropagating the policy loss through the vision backbone. Yet, this approach tends to learn task-specific features with limited generalizability. Alternatively, learning world models can realize more generalizable vision backbones. Utilizing the learnt features, task-specific policies are subsequently trained. Commonly, these models are trained solely to predict the next RGB state from the current state and action taken. But only-RGB prediction might not fully-capture the task-relevant dynamics. In this work, we hypothesize that direct supervision of target dynamic states (Dynamics Mapping) can learn better dynamics-informed world models. Beside the next RGB reconstruction, the world model is also trained to directly predict position, velocity, and acceleration of environment rigid bodies. To verify our hypothesis, we designed a non-prehensile 2D environment tailored to two tasks: "Balance-Reaching" and "Bin-Dropping". When trained on the first task, dynamics mapping enhanced the task performance under different training configurations (Decoupled, Joint, End-to-End) and policy architectures (Feedforward, Recurrent). Notably, its most significant impact was for world model pretraining boosting the success rate from 21% to 85%. Although frozen dynamics-informed world models could generalize well to a task with in-domain dynamics, but poorly to a one with out-of-domain dynamics.
Component Selection for Craft Assembly Tasks
Jul 19, 2024
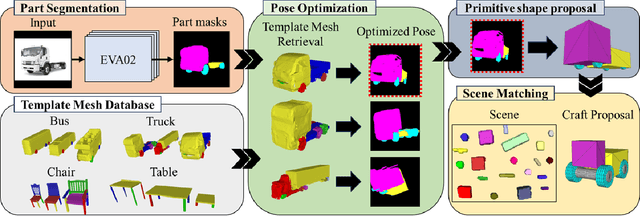


Inspired by traditional handmade crafts, where a person improvises assemblies based on the available objects, we formally introduce the Craft Assembly Task. It is a robotic assembly task that involves building an accurate representation of a given target object using the available objects, which do not directly correspond to its parts. In this work, we focus on selecting the subset of available objects for the final craft, when the given input is an RGB image of the target in the wild. We use a mask segmentation neural network to identify visible parts, followed by retrieving labelled template meshes. These meshes undergo pose optimization to determine the most suitable template. Then, we propose to simplify the parts of the transformed template mesh to primitive shapes like cuboids or cylinders. Finally, we design a search algorithm to find correspondences in the scene based on local and global proportions. We develop baselines for comparison that consider all possible combinations, and choose the highest scoring combination for common metrics used in foreground maps and mask accuracy. Our approach achieves comparable results to the baselines for two different scenes, and we show qualitative results for an implementation in a real-world scenario.
PEGASUS: Physically Enhanced Gaussian Splatting Simulation System for 6DOF Object Pose Dataset Generation
Jan 04, 2024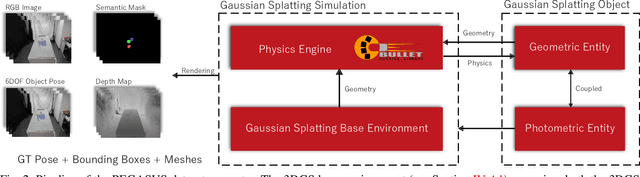


We introduce Physically Enhanced Gaussian Splatting Simulation System (PEGASUS) for 6DOF object pose dataset generation, a versatile dataset generator based on 3D Gaussian Splatting. Environment and object representations can be easily obtained using commodity cameras to reconstruct with Gaussian Splatting. PEGASUS allows the composition of new scenes by merging the respective underlying Gaussian Splatting point cloud of an environment with one or multiple objects. Leveraging a physics engine enables the simulation of natural object placement within a scene through interaction between meshes extracted for the objects and the environment. Consequently, an extensive amount of new scenes - static or dynamic - can be created by combining different environments and objects. By rendering scenes from various perspectives, diverse data points such as RGB images, depth maps, semantic masks, and 6DoF object poses can be extracted. Our study demonstrates that training on data generated by PEGASUS enables pose estimation networks to successfully transfer from synthetic data to real-world data. Moreover, we introduce the Ramen dataset, comprising 30 Japanese cup noodle items. This dataset includes spherical scans that captures images from both object hemisphere and the Gaussian Splatting reconstruction, making them compatible with PEGASUS.
NeuralLabeling: A versatile toolset for labeling vision datasets using Neural Radiance Fields
Sep 21, 2023



We present NeuralLabeling, a labeling approach and toolset for annotating a scene using either bounding boxes or meshes and generating segmentation masks, affordance maps, 2D bounding boxes, 3D bounding boxes, 6DOF object poses, depth maps and object meshes. NeuralLabeling uses Neural Radiance Fields (NeRF) as renderer, allowing labeling to be performed using 3D spatial tools while incorporating geometric clues such as occlusions, relying only on images captured from multiple viewpoints as input. To demonstrate the applicability of NeuralLabeling to a practical problem in robotics, we added ground truth depth maps to 30000 frames of transparent object RGB and noisy depth maps of glasses placed in a dishwasher captured using an RGBD sensor, yielding the Dishwasher30k dataset. We show that training a simple deep neural network with supervision using the annotated depth maps yields a higher reconstruction performance than training with the previously applied weakly supervised approach.