 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCooking Task Planning using LLM and Verified by Graph Network
Mar 27, 2025



Cooking tasks remain a challenging problem for robotics due to their complexity. Videos of people cooking are a valuable source of information for such task, but introduces a lot of variability in terms of how to translate this data to a robotic environment. This research aims to streamline this process, focusing on the task plan generation step, by using a Large Language Model (LLM)-based Task and Motion Planning (TAMP) framework to autonomously generate cooking task plans from videos with subtitles, and execute them. Conventional LLM-based task planning methods are not well-suited for interpreting the cooking video data due to uncertainty in the videos, and the risk of hallucination in its output. To address both of these problems, we explore using LLMs in combination with Functional Object-Oriented Networks (FOON), to validate the plan and provide feedback in case of failure. This combination can generate task sequences with manipulation motions that are logically correct and executable by a robot. We compare the execution of the generated plans for 5 cooking recipes from our approach against the plans generated by a few-shot LLM-only approach for a dual-arm robot setup. It could successfully execute 4 of the plans generated by our approach, whereas only 1 of the plans generated by solely using the LLM could be executed.
Component Selection for Craft Assembly Tasks
Jul 19, 2024
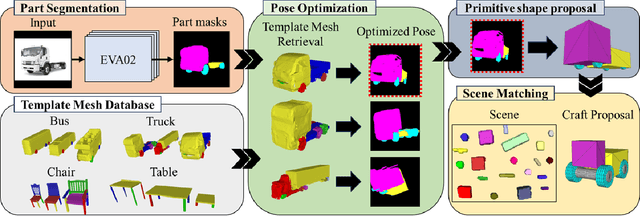


Inspired by traditional handmade crafts, where a person improvises assemblies based on the available objects, we formally introduce the Craft Assembly Task. It is a robotic assembly task that involves building an accurate representation of a given target object using the available objects, which do not directly correspond to its parts. In this work, we focus on selecting the subset of available objects for the final craft, when the given input is an RGB image of the target in the wild. We use a mask segmentation neural network to identify visible parts, followed by retrieving labelled template meshes. These meshes undergo pose optimization to determine the most suitable template. Then, we propose to simplify the parts of the transformed template mesh to primitive shapes like cuboids or cylinders. Finally, we design a search algorithm to find correspondences in the scene based on local and global proportions. We develop baselines for comparison that consider all possible combinations, and choose the highest scoring combination for common metrics used in foreground maps and mask accuracy. Our approach achieves comparable results to the baselines for two different scenes, and we show qualitative results for an implementation in a real-world scenario.