 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIndustrial-Grade Robust Robot Vision for Screw Detection and Removal under Uneven Conditions
Mar 31, 2026As the amount of used home appliances is expected to increase despite the decreasing labor force in Japan, there is a need to automate disassembling processes at recycling plants. The automation of disassembling air conditioner outdoor units, however, remains a challenge due to unit size variations and exposure to dirt and rust. To address these challenges, this study proposes an automated system that integrates a task-specific two-stage detection method and a lattice-based local calibration strategy. This approach achieved a screw detection recall of 99.8% despite severe degradation and ensured a manipulation accuracy of +/-0.75 mm without pre-programmed coordinates. In real-world validation with 120 units, the system attained a disassembly success rate of 78.3% and an average cycle time of 193 seconds, confirming its feasibility for industrial application.
Generalizable task-oriented object grasping through LLM-guided ontology and similarity-based planning
Mar 27, 2026Task-oriented grasping (TOG) is more challenging than simple object grasping because it requires precise identification of object parts and careful selection of grasping areas to ensure effective and robust manipulation. While recent approaches have trained large-scale vision-language models to integrate part-level object segmentation with task-aware grasp planning, their instability in part recognition and grasp inference limits their ability to generalize across diverse objects and tasks. To address this issue, we introduce a novel, geometry-centric strategy for more generalizable TOG that does not rely on semantic features from visual recognition, effectively overcoming the viewpoint sensitivity of model-based approaches. Our main proposals include: 1) an object-part-task ontology for functional part selection based on intuitive human commands, constructed using a Large Language Model (LLM); 2) a sampling-based geometric analysis method for identifying the selected object part from observed point clouds, incorporating multiple point distribution and distance metrics; and 3) a similarity matching framework for imitative grasp planning, utilizing similar known objects with pre-existing segmentation and grasping knowledge as references to guide the planning for unknown targets. We validate the high accuracy of our approach in functional part selection, identification, and grasp generation through real-world experiments. Additionally, we demonstrate the method's generalization capabilities to novel-category objects by extending existing ontological knowledge, showcasing its adaptability to a broad range of objects and tasks.
Affordance-Guided Enveloping Grasp Demonstration Toward Non-destructive Disassembly of Pinch-Infeasible Mating Parts
Mar 22, 2026Robotic disassembly of complex mating components often renders pinch grasping infeasible, necessitating multi-fingered enveloping grasps. However, visual occlusions and geometric constraints complicate teaching appropriate grasp motions when relying solely on 2D camera feeds. To address this, we propose an affordance-guided teleoperation method that pre-generates enveloping grasp candidates via physics simulation. These Affordance Templates (ATs) are visualized with a color gradient reflecting grasp quality to augment operator perception. Simulations demonstrate the method's generality across various components. Real-robot experiments validate that AT-based visual augmentation enables operators to effectively select and teach enveloping grasp strategies for real-world disassembly, even under severe visual and geometric constraints.
Gait Generation Balancing Joint Load and Mobility for Legged Modular Robots with Easily Detachable Joints
Mar 05, 2026While modular robots offer versatility, excessive joint torque during locomotion poses a significant risk of mechanical failure, especially for detachable joints. To address this, we propose an optimization framework using the NSGA-III algorithm. Unlike conventional approaches that prioritize mobility alone, our method derives Pareto optimal solutions to minimize joint load while maintaining necessary locomotion speed and stability. Simulations and physical experiments demonstrate that our approach successfully generates gait motions for diverse environments, such as slopes and steps, ensuring structural integrity without compromising overall mobility.
Designing and Validating a Self-Aligning Tool Changer for Modular Reconfigurable Manipulation Robots
Mar 05, 2026Modular reconfigurable robots require reliable mechanisms for automated module exchange, but conventional rigid active couplings often fail due to inevitable positioning and orientational errors. To address this, we propose a misalignment-tolerant tool-changing system. The hardware features a motor-driven coupling utilizing passive self-alignment geometries, specifically chamfered receptacles and triangular lead-in guides, to robustly compensate for angular and lateral misalignments without complex force sensors. To make this autonomous exchange practically feasible, the mechanism is complemented by a compact rotating tool exchange station for efficient module storage. Real-world autonomous tool-picking experiments validate that the self-aligning features successfully absorb execution errors, enabling highly reliable robotic tool reconfiguration.
Replanning Human-Robot Collaborative Tasks with Vision-Language Models via Semantic and Physical Dual-Correction
Feb 16, 2026Human-Robot Collaboration (HRC) plays an important role in assembly tasks by enabling robots to plan and adjust their motions based on interactive, real-time human instructions. However, such instructions are often linguistically ambiguous and underspecified, making it difficult to generate physically feasible and cooperative robot behaviors. To address this challenge, many studies have applied Vision-Language Models (VLMs) to interpret high-level instructions and generate corresponding actions. Nevertheless, VLM-based approaches still suffer from hallucinated reasoning and an inability to anticipate physical execution failures. To address these challenges, we propose an HRC framework that augments a VLM-based reasoning with a dual-correction mechanism: an internal correction model that verifies logical consistency and task feasibility prior to action execution, and an external correction model that detects and rectifies physical failures through post-execution feedback. Simulation ablation studies demonstrate that the proposed method improves the success rate compared to baselines without correction models. Our real-world experiments in collaborative assembly tasks supported by object fixation or tool preparation by an upper body humanoid robot further confirm the framewor's effectiveness in enabling interactive replanning across different collaborative tasks in response to human instructions, validating its practical feasibility.
Hierarchical Planning and Scheduling for Reconfigurable Multi-Robot Disassembly Systems under Structural Constraints
Sep 18, 2025This study presents a system integration approach for planning schedules, sequences, tasks, and motions for reconfigurable robots to automatically disassemble constrained structures in a non-destructive manner. Such systems must adapt their configuration and coordination to the target structure, but the large and complex search space makes them prone to local optima. To address this, we integrate multiple robot arms equipped with different types of tools, together with a rotary stage, into a reconfigurable setup. This flexible system is based on a hierarchical optimization method that generates plans meeting multiple preferred conditions under mandatory requirements within a realistic timeframe. The approach employs two many-objective genetic algorithms for sequence and task planning with motion evaluations, followed by constraint programming for scheduling. Because sequence planning has a much larger search space, we introduce a chromosome initialization method tailored to constrained structures to mitigate the risk of local optima. Simulation results demonstrate that the proposed method effectively solves complex problems in reconfigurable robotic disassembly.
Soft Regrasping Tool Inspired by Jamming Gripper
Sep 17, 2025

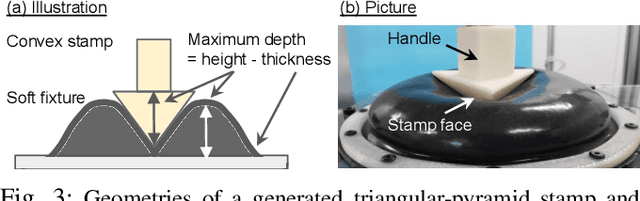

Regrasping on fixtures is a promising approach to reduce pose uncertainty in robotic assembly, but conventional rigid fixtures lack adaptability and require dedicated designs for each part. To overcome this limitation, we propose a soft jig inspired by the jamming transition phenomenon, which can be continuously deformed to accommodate diverse object geometries. By pressing a triangular-pyramid-shaped tool into the membrane and evacuating the enclosed air, a stable cavity is formed as a placement space. We further optimize the stamping depth to balance placement stability and gripper accessibility. In soft-jig-based regrasping, the key challenge lies in optimizing the cavity size to achieve precise dropping; once the part is reliably placed, subsequent grasping can be performed with reduced uncertainty. Accordingly, we conducted drop experiments on ten mechanical parts of varying shapes, which achieved placement success rates exceeding 80% for most objects and above 90% for cylindrical ones, while failures were mainly caused by geometric constraints and membrane properties. These results demonstrate that the proposed jig enables general-purpose, accurate, and repeatable regrasping, while also clarifying its current limitations and future potential as a practical alternative to rigid fixtures in assembly automation.
A Multi-Level Similarity Approach for Single-View Object Grasping: Matching, Planning, and Fine-Tuning
Jul 16, 2025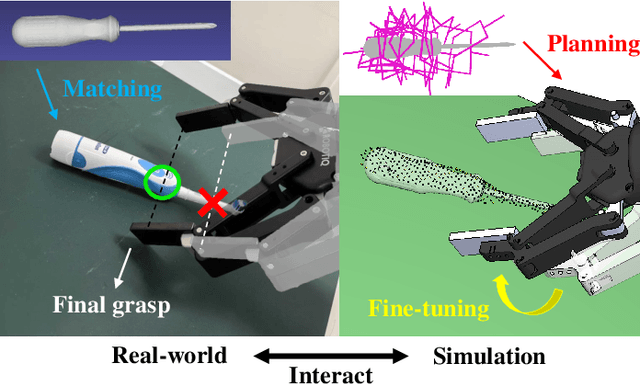


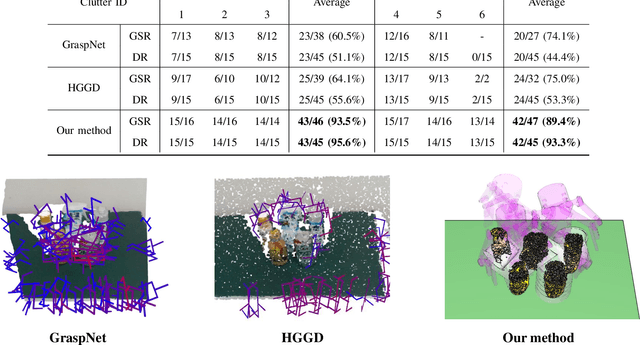
Grasping unknown objects from a single view has remained a challenging topic in robotics due to the uncertainty of partial observation. Recent advances in large-scale models have led to benchmark solutions such as GraspNet-1Billion. However, such learning-based approaches still face a critical limitation in performance robustness for their sensitivity to sensing noise and environmental changes. To address this bottleneck in achieving highly generalized grasping, we abandon the traditional learning framework and introduce a new perspective: similarity matching, where similar known objects are utilized to guide the grasping of unknown target objects. We newly propose a method that robustly achieves unknown-object grasping from a single viewpoint through three key steps: 1) Leverage the visual features of the observed object to perform similarity matching with an existing database containing various object models, identifying potential candidates with high similarity; 2) Use the candidate models with pre-existing grasping knowledge to plan imitative grasps for the unknown target object; 3) Optimize the grasp quality through a local fine-tuning process. To address the uncertainty caused by partial and noisy observation, we propose a multi-level similarity matching framework that integrates semantic, geometric, and dimensional features for comprehensive evaluation. Especially, we introduce a novel point cloud geometric descriptor, the C-FPFH descriptor, which facilitates accurate similarity assessment between partial point clouds of observed objects and complete point clouds of database models. In addition, we incorporate the use of large language models, introduce the semi-oriented bounding box, and develop a novel point cloud registration approach based on plane detection to enhance matching accuracy under single-view conditions. Videos are available at https://youtu.be/qQDIELMhQmk.
Cooking Task Planning using LLM and Verified by Graph Network
Mar 27, 2025



Cooking tasks remain a challenging problem for robotics due to their complexity. Videos of people cooking are a valuable source of information for such task, but introduces a lot of variability in terms of how to translate this data to a robotic environment. This research aims to streamline this process, focusing on the task plan generation step, by using a Large Language Model (LLM)-based Task and Motion Planning (TAMP) framework to autonomously generate cooking task plans from videos with subtitles, and execute them. Conventional LLM-based task planning methods are not well-suited for interpreting the cooking video data due to uncertainty in the videos, and the risk of hallucination in its output. To address both of these problems, we explore using LLMs in combination with Functional Object-Oriented Networks (FOON), to validate the plan and provide feedback in case of failure. This combination can generate task sequences with manipulation motions that are logically correct and executable by a robot. We compare the execution of the generated plans for 5 cooking recipes from our approach against the plans generated by a few-shot LLM-only approach for a dual-arm robot setup. It could successfully execute 4 of the plans generated by our approach, whereas only 1 of the plans generated by solely using the LLM could be executed.