 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYUBI: Yielding Universal Bidigital Interface for Bimanual Dexterous Manipulation at Scale
Jun 08, 2026We introduce Yielding Universal Bidigital Interface (YUBI), a finger-aligned gripper designed to enable intuitive, ergonomic, and scalable data collection for bimanual dexterous manipulation. While handheld data collection systems such as Universal Manipulation Interface (UMI) enable affordable data collection, their bulky pistol-grip designs can pose ergonomic and usability challenges for fine-grained, dexterous manipulation tasks. To address this, YUBI presents a distinct design principle: yielding, finger-driven actuation that directly maps human finger movements to gripper jaw motion. Using the YUBI devices, we set up a data collection system with integrated VR-based 6 DoF tracking of the gripper, ensuring high-fidelity trajectory data acquisition. We curate a UMI-based dataset of unprecedented scale: 8,434 hours across 1.20M episodes and 119 tasks. Experiments show that YUBI offers advantages over the UMI gripper in versatility for complex bimanual tasks, dexterity, and operational efficiency. A single policy trained on the YUBI dataset transfers across multiple bimanual robots (UR, Franka, and ELEY) simply by mounting the gripper on each platform, confirming that the collected data are directly executable as policy supervision. We release the gripper hardware, data-collection software, and dataset as one integrated stack, offering the open community a reproducible path to large-scale data acquisition for advancing robotic foundation models.
A Flexible Field-Based Policy Learning Framework for Diverse Robotic Systems and Sensors
Dec 22, 2025We present a cross robot visuomotor learning framework that integrates diffusion policy based control with 3D semantic scene representations from D3Fields to enable category level generalization in manipulation. Its modular design supports diverse robot camera configurations including UR5 arms with Microsoft Azure Kinect arrays and bimanual manipulators with Intel RealSense sensors through a low latency control stack and intuitive teleoperation. A unified configuration layer enables seamless switching between setups for flexible data collection training and evaluation. In a grasp and lift block task the framework achieved an 80 percent success rate after only 100 demonstration episodes demonstrating robust skill transfer between platforms and sensing modalities. This design paves the way for scalable real world studies in cross robotic generalization.
Visual Prompting for Robotic Manipulation with Annotation-Guided Pick-and-Place Using ACT
Aug 12, 2025Robotic pick-and-place tasks in convenience stores pose challenges due to dense object arrangements, occlusions, and variations in object properties such as color, shape, size, and texture. These factors complicate trajectory planning and grasping. This paper introduces a perception-action pipeline leveraging annotation-guided visual prompting, where bounding box annotations identify both pickable objects and placement locations, providing structured spatial guidance. Instead of traditional step-by-step planning, we employ Action Chunking with Transformers (ACT) as an imitation learning algorithm, enabling the robotic arm to predict chunked action sequences from human demonstrations. This facilitates smooth, adaptive, and data-driven pick-and-place operations. We evaluate our system based on success rate and visual analysis of grasping behavior, demonstrating improved grasp accuracy and adaptability in retail environments.
Learning Bimanual Manipulation via Action Chunking and Inter-Arm Coordination with Transformers
Mar 18, 2025Robots that can operate autonomously in a human living environment are necessary to have the ability to handle various tasks flexibly. One crucial element is coordinated bimanual movements that enable functions that are difficult to perform with one hand alone. In recent years, learning-based models that focus on the possibilities of bimanual movements have been proposed. However, the high degree of freedom of the robot makes it challenging to reason about control, and the left and right robot arms need to adjust their actions depending on the situation, making it difficult to realize more dexterous tasks. To address the issue, we focus on coordination and efficiency between both arms, particularly for synchronized actions. Therefore, we propose a novel imitation learning architecture that predicts cooperative actions. We differentiate the architecture for both arms and add an intermediate encoder layer, Inter-Arm Coordinated transformer Encoder (IACE), that facilitates synchronization and temporal alignment to ensure smooth and coordinated actions. To verify the effectiveness of our architectures, we perform distinctive bimanual tasks. The experimental results showed that our model demonstrated a high success rate for comparison and suggested a suitable architecture for the policy learning of bimanual manipulation.
Attention-Guided Integration of CLIP and SAM for Precise Object Masking in Robotic Manipulation
Feb 26, 2025This paper introduces a novel pipeline to enhance the precision of object masking for robotic manipulation within the specific domain of masking products in convenience stores. The approach integrates two advanced AI models, CLIP and SAM, focusing on their synergistic combination and the effective use of multimodal data (image and text). Emphasis is placed on utilizing gradient-based attention mechanisms and customized datasets to fine-tune performance. While CLIP, SAM, and Grad- CAM are established components, their integration within this structured pipeline represents a significant contribution to the field. The resulting segmented masks, generated through this combined approach, can be effectively utilized as inputs for robotic systems, enabling more precise and adaptive object manipulation in the context of convenience store products.
SuctionPrompt: Visual-assisted Robotic Picking with a Suction Cup Using Vision-Language Models and Facile Hardware Design
Oct 31, 2024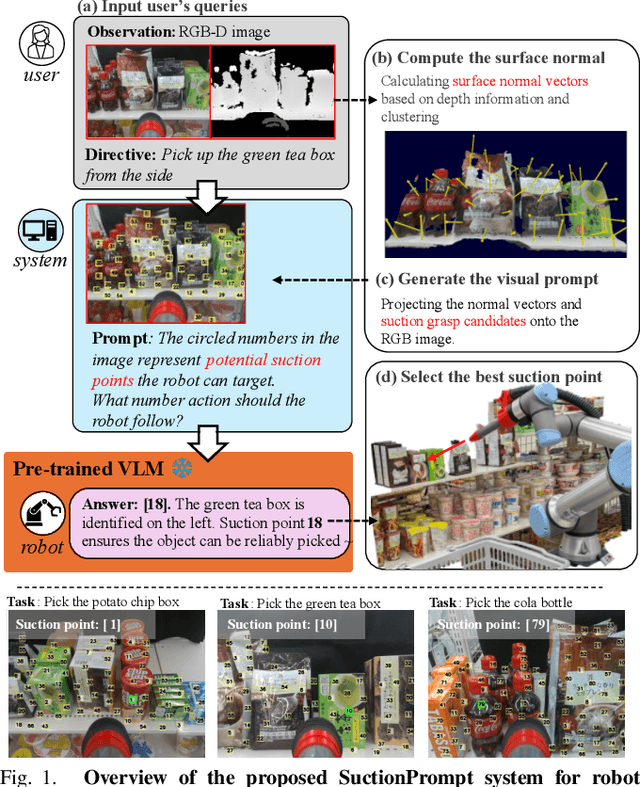
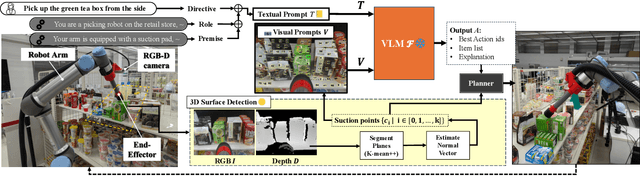
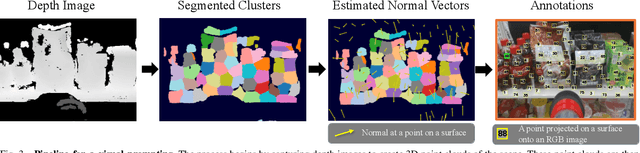
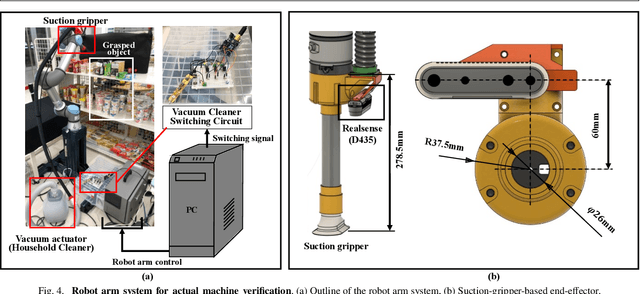
The development of large language models and vision-language models (VLMs) has resulted in the increasing use of robotic systems in various fields. However, the effective integration of these models into real-world robotic tasks is a key challenge. We developed a versatile robotic system called SuctionPrompt that utilizes prompting techniques of VLMs combined with 3D detections to perform product-picking tasks in diverse and dynamic environments. Our method highlights the importance of integrating 3D spatial information with adaptive action planning to enable robots to approach and manipulate objects in novel environments. In the validation experiments, the system accurately selected suction points 75.4%, and achieved a 65.0% success rate in picking common items. This study highlights the effectiveness of VLMs in robotic manipulation tasks, even with simple 3D processing.
Probabilistic Slide-support Manipulation Planning in Clutter
Jun 22, 2023



To safely and efficiently extract an object from the clutter, this paper presents a bimanual manipulation planner in which one hand of the robot is used to slide the target object out of the clutter while the other hand is used to support the surrounding objects to prevent the clutter from collapsing. Our method uses a neural network to predict the physical phenomena of the clutter when the target object is moved. We generate the most efficient action based on the Monte Carlo tree search.The grasping and sliding actions are planned to minimize the number of motion sequences to pick the target object. In addition, the object to be supported is determined to minimize the position change of surrounding objects. Experiments with a real bimanual robot confirmed that the robot could retrieve the target object, reducing the total number of motion sequences and improving safety.