 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSuctionPrompt: Visual-assisted Robotic Picking with a Suction Cup Using Vision-Language Models and Facile Hardware Design
Paper and Code
Oct 31, 2024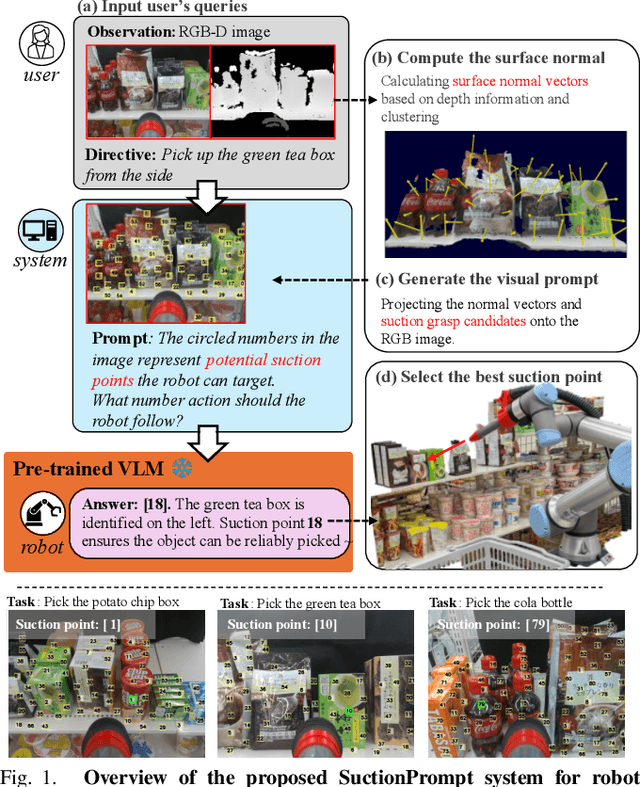
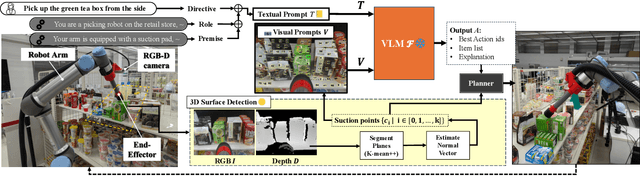
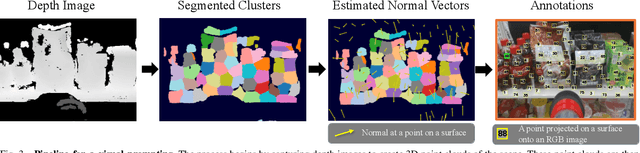
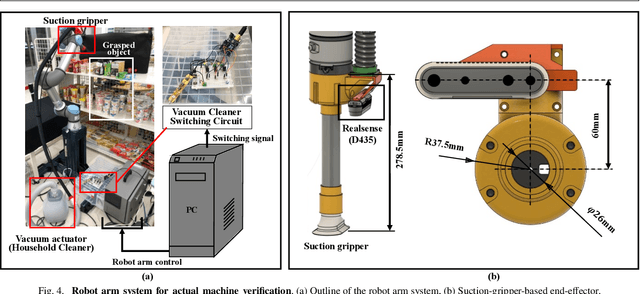
The development of large language models and vision-language models (VLMs) has resulted in the increasing use of robotic systems in various fields. However, the effective integration of these models into real-world robotic tasks is a key challenge. We developed a versatile robotic system called SuctionPrompt that utilizes prompting techniques of VLMs combined with 3D detections to perform product-picking tasks in diverse and dynamic environments. Our method highlights the importance of integrating 3D spatial information with adaptive action planning to enable robots to approach and manipulate objects in novel environments. In the validation experiments, the system accurately selected suction points 75.4%, and achieved a 65.0% success rate in picking common items. This study highlights the effectiveness of VLMs in robotic manipulation tasks, even with simple 3D processing.