 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSkelSplat: Robust Multi-view 3D Human Pose Estimation with Differentiable Gaussian Rendering
Nov 11, 2025Accurate 3D human pose estimation is fundamental for applications such as augmented reality and human-robot interaction. State-of-the-art multi-view methods learn to fuse predictions across views by training on large annotated datasets, leading to poor generalization when the test scenario differs. To overcome these limitations, we propose SkelSplat, a novel framework for multi-view 3D human pose estimation based on differentiable Gaussian rendering. Human pose is modeled as a skeleton of 3D Gaussians, one per joint, optimized via differentiable rendering to enable seamless fusion of arbitrary camera views without 3D ground-truth supervision. Since Gaussian Splatting was originally designed for dense scene reconstruction, we propose a novel one-hot encoding scheme that enables independent optimization of human joints. SkelSplat outperforms approaches that do not rely on 3D ground truth in Human3.6M and CMU, while reducing the cross-dataset error up to 47.8% compared to learning-based methods. Experiments on Human3.6M-Occ and Occlusion-Person demonstrate robustness to occlusions, without scenario-specific fine-tuning. Our project page is available here: https://skelsplat.github.io.
Dream to Manipulate: Compositional World Models Empowering Robot Imitation Learning with Imagination
Dec 19, 2024A world model provides an agent with a representation of its environment, enabling it to predict the causal consequences of its actions. Current world models typically cannot directly and explicitly imitate the actual environment in front of a robot, often resulting in unrealistic behaviors and hallucinations that make them unsuitable for real-world applications. In this paper, we introduce a new paradigm for constructing world models that are explicit representations of the real world and its dynamics. By integrating cutting-edge advances in real-time photorealism with Gaussian Splatting and physics simulators, we propose the first compositional manipulation world model, which we call DreMa. DreMa replicates the observed world and its dynamics, allowing it to imagine novel configurations of objects and predict the future consequences of robot actions. We leverage this capability to generate new data for imitation learning by applying equivariant transformations to a small set of demonstrations. Our evaluations across various settings demonstrate significant improvements in both accuracy and robustness by incrementing actions and object distributions, reducing the data needed to learn a policy and improving the generalization of the agents. As a highlight, we show that a real Franka Emika Panda robot, powered by DreMa's imagination, can successfully learn novel physical tasks from just a single example per task variation (one-shot policy learning). Our project page and source code can be found in https://leobarcellona.github.io/DreamToManipulate/
WasteGAN: Data Augmentation for Robotic Waste Sorting through Generative Adversarial Networks
Sep 25, 2024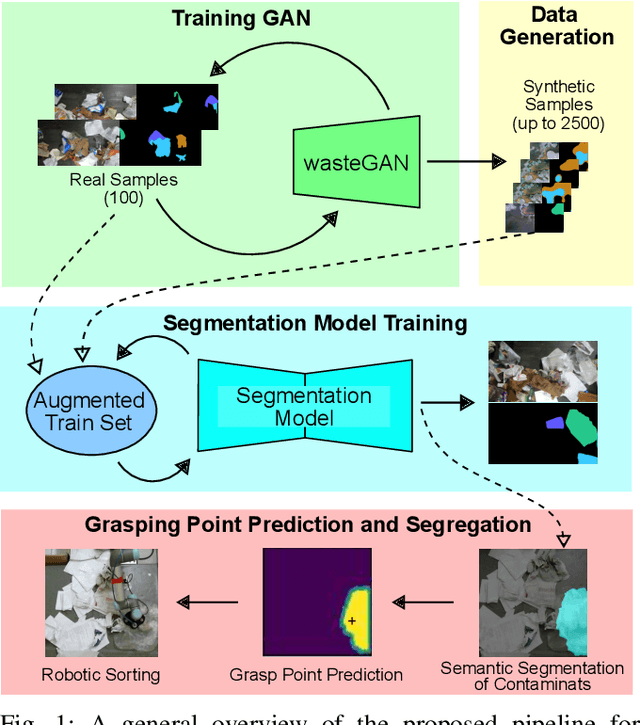
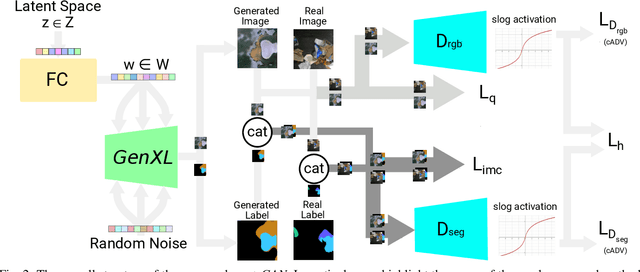
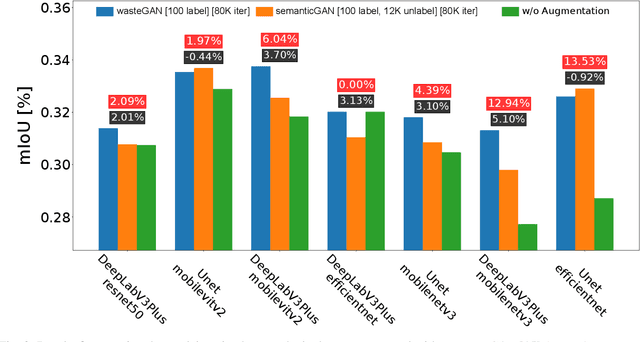
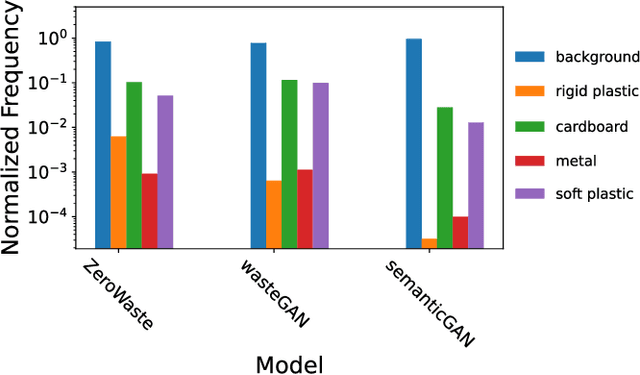
Robotic waste sorting poses significant challenges in both perception and manipulation, given the extreme variability of objects that should be recognized on a cluttered conveyor belt. While deep learning has proven effective in solving complex tasks, the necessity for extensive data collection and labeling limits its applicability in real-world scenarios like waste sorting. To tackle this issue, we introduce a data augmentation method based on a novel GAN architecture called wasteGAN. The proposed method allows to increase the performance of semantic segmentation models, starting from a very limited bunch of labeled examples, such as few as 100. The key innovations of wasteGAN include a novel loss function, a novel activation function, and a larger generator block. Overall, such innovations helps the network to learn from limited number of examples and synthesize data that better mirrors real-world distributions. We then leverage the higher-quality segmentation masks predicted from models trained on the wasteGAN synthetic data to compute semantic-aware grasp poses, enabling a robotic arm to effectively recognizing contaminants and separating waste in a real-world scenario. Through comprehensive evaluation encompassing dataset-based assessments and real-world experiments, our methodology demonstrated promising potential for robotic waste sorting, yielding performance gains of up to 5.8\% in picking contaminants. The project page is available at https://github.com/bach05/wasteGAN.git
Show and Grasp: Few-shot Semantic Segmentation for Robot Grasping through Zero-shot Foundation Models
Apr 19, 2024



The ability of a robot to pick an object, known as robot grasping, is crucial for several applications, such as assembly or sorting. In such tasks, selecting the right target to pick is as essential as inferring a correct configuration of the gripper. A common solution to this problem relies on semantic segmentation models, which often show poor generalization to unseen objects and require considerable time and massive data to be trained. To reduce the need for large datasets, some grasping pipelines exploit few-shot semantic segmentation models, which are capable of recognizing new classes given a few examples. However, this often comes at the cost of limited performance and fine-tuning is required to be effective in robot grasping scenarios. In this work, we propose to overcome all these limitations by combining the impressive generalization capability reached by foundation models with a high-performing few-shot classifier, working as a score function to select the segmentation that is closer to the support set. The proposed model is designed to be embedded in a grasp synthesis pipeline. The extensive experiments using one or five examples show that our novel approach overcomes existing performance limitations, improving the state of the art both in few-shot semantic segmentation on the Graspnet-1B (+10.5% mIoU) and Ocid-grasp (+1.6% AP) datasets, and real-world few-shot grasp synthesis (+21.7% grasp accuracy). The project page is available at: https://leobarcellona.github.io/showandgrasp.github.io/