 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCalib3R: A 3D Foundation Model for Multi-Camera to Robot Calibration and 3D Metric-Scaled Scene Reconstruction
Sep 10, 2025Robots often rely on RGB images for tasks like manipulation and navigation. However, reliable interaction typically requires a 3D scene representation that is metric-scaled and aligned with the robot reference frame. This depends on accurate camera-to-robot calibration and dense 3D reconstruction, tasks usually treated separately, despite both relying on geometric correspondences from RGB data. Traditional calibration needs patterns, while RGB-based reconstruction yields geometry with an unknown scale in an arbitrary frame. Multi-camera setups add further complexity, as data must be expressed in a shared reference frame. We present Calib3R, a patternless method that jointly performs camera-to-robot calibration and metric-scaled 3D reconstruction via unified optimization. Calib3R handles single- and multi-camera setups on robot arms or mobile robots. It builds on the 3D foundation model MASt3R to extract pointmaps from RGB images, which are combined with robot poses to reconstruct a scaled 3D scene aligned with the robot. Experiments on diverse datasets show that Calib3R achieves accurate calibration with less than 10 images, outperforming target-less and marker-based methods.
Data efficient Robotic Object Throwing with Model-Based Reinforcement Learning
Feb 08, 2025



Pick-and-place (PnP) operations, featuring object grasping and trajectory planning, are fundamental in industrial robotics applications. Despite many advancements in the field, PnP is limited by workspace constraints, reducing flexibility. Pick-and-throw (PnT) is a promising alternative where the robot throws objects to target locations, leveraging extrinsic resources like gravity to improve efficiency and expand the workspace. However, PnT execution is complex, requiring precise coordination of high-speed movements and object dynamics. Solutions to the PnT problem are categorized into analytical and learning-based approaches. Analytical methods focus on system modeling and trajectory generation but are time-consuming and offer limited generalization. Learning-based solutions, in particular Model-Free Reinforcement Learning (MFRL), offer automation and adaptability but require extensive interaction time. This paper introduces a Model-Based Reinforcement Learning (MBRL) framework, MC-PILOT, which combines data-driven modeling with policy optimization for efficient and accurate PnT tasks. MC-PILOT accounts for model uncertainties and release errors, demonstrating superior performance in simulations and real-world tests with a Franka Emika Panda manipulator. The proposed approach generalizes rapidly to new targets, offering advantages over analytical and Model-Free methods.
MEMROC: Multi-Eye to Mobile RObot Calibration
Oct 11, 2024This paper presents MEMROC (Multi-Eye to Mobile RObot Calibration), a novel motion-based calibration method that simplifies the process of accurately calibrating multiple cameras relative to a mobile robot's reference frame. MEMROC utilizes a known calibration pattern to facilitate accurate calibration with a lower number of images during the optimization process. Additionally, it leverages robust ground plane detection for comprehensive 6-DoF extrinsic calibration, overcoming a critical limitation of many existing methods that struggle to estimate the complete camera pose. The proposed method addresses the need for frequent recalibration in dynamic environments, where cameras may shift slightly or alter their positions due to daily usage, operational adjustments, or vibrations from mobile robot movements. MEMROC exhibits remarkable robustness to noisy odometry data, requiring minimal calibration input data. This combination makes it highly suitable for daily operations involving mobile robots. A comprehensive set of experiments on both synthetic and real data proves MEMROC's efficiency, surpassing existing state-of-the-art methods in terms of accuracy, robustness, and ease of use. To facilitate further research, we have made our code publicly available at https://github.com/davidea97/MEMROC.git.
WasteGAN: Data Augmentation for Robotic Waste Sorting through Generative Adversarial Networks
Sep 25, 2024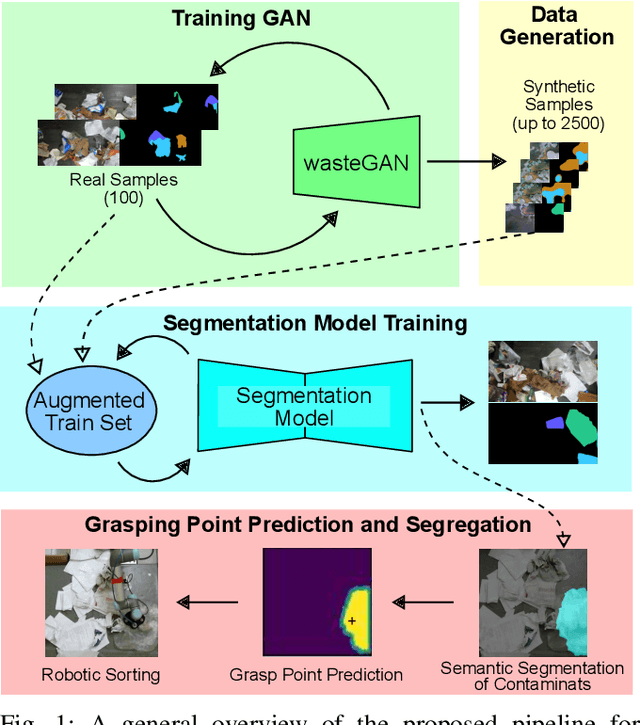
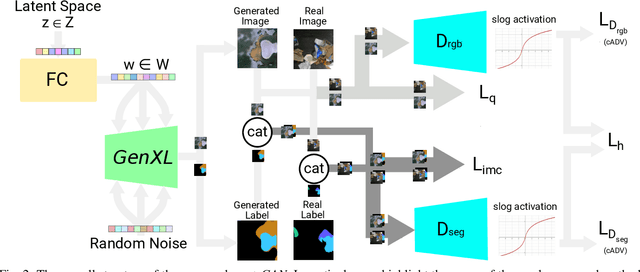
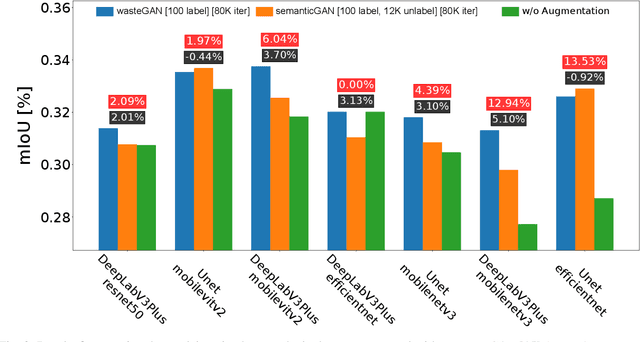
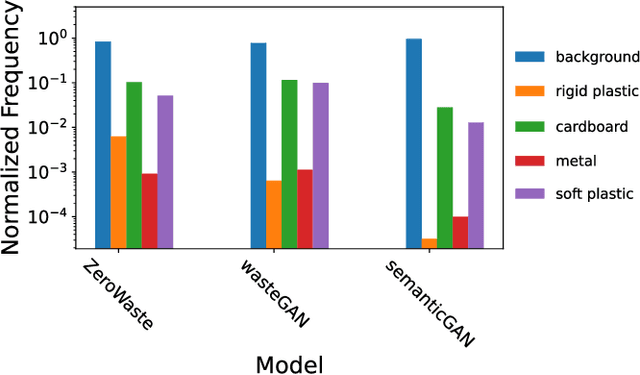
Robotic waste sorting poses significant challenges in both perception and manipulation, given the extreme variability of objects that should be recognized on a cluttered conveyor belt. While deep learning has proven effective in solving complex tasks, the necessity for extensive data collection and labeling limits its applicability in real-world scenarios like waste sorting. To tackle this issue, we introduce a data augmentation method based on a novel GAN architecture called wasteGAN. The proposed method allows to increase the performance of semantic segmentation models, starting from a very limited bunch of labeled examples, such as few as 100. The key innovations of wasteGAN include a novel loss function, a novel activation function, and a larger generator block. Overall, such innovations helps the network to learn from limited number of examples and synthesize data that better mirrors real-world distributions. We then leverage the higher-quality segmentation masks predicted from models trained on the wasteGAN synthetic data to compute semantic-aware grasp poses, enabling a robotic arm to effectively recognizing contaminants and separating waste in a real-world scenario. Through comprehensive evaluation encompassing dataset-based assessments and real-world experiments, our methodology demonstrated promising potential for robotic waste sorting, yielding performance gains of up to 5.8\% in picking contaminants. The project page is available at https://github.com/bach05/wasteGAN.git
DECAF: a Discrete-Event based Collaborative Human-Robot Framework for Furniture Assembly
Aug 28, 2024
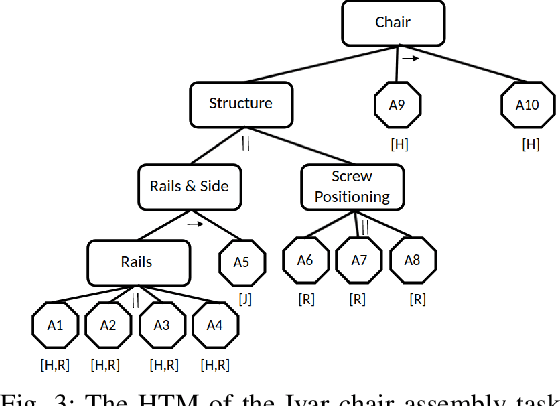
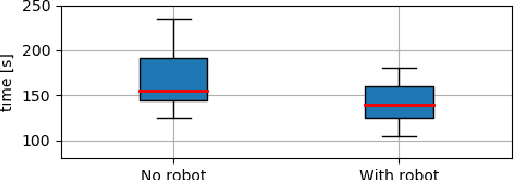
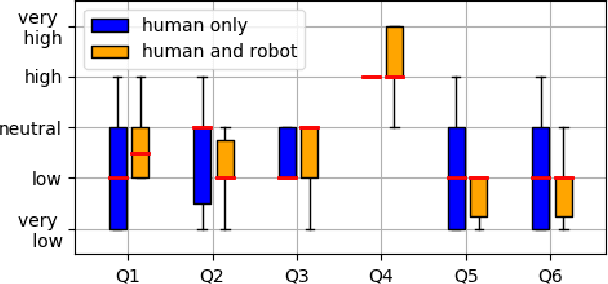
This paper proposes a task planning framework for collaborative Human-Robot scenarios, specifically focused on assembling complex systems such as furniture. The human is characterized as an uncontrollable agent, implying for example that the agent is not bound by a pre-established sequence of actions and instead acts according to its own preferences. Meanwhile, the task planner computes reactively the optimal actions for the collaborative robot to efficiently complete the entire assembly task in the least time possible. We formalize the problem as a Discrete Event Markov Decision Problem (DE-MDP), a comprehensive framework that incorporates a variety of asynchronous behaviors, human change of mind and failure recovery as stochastic events. Although the problem could theoretically be addressed by constructing a graph of all possible actions, such an approach would be constrained by computational limitations. The proposed formulation offers an alternative solution utilizing Reinforcement Learning to derive an optimal policy for the robot. Experiments where conducted both in simulation and on a real system with human subjects assembling a chair in collaboration with a 7-DoF manipulator.
Multi-view Pose Fusion for Occlusion-Aware 3D Human Pose Estimation
Aug 28, 2024



Robust 3D human pose estimation is crucial to ensure safe and effective human-robot collaboration. Accurate human perception,however, is particularly challenging in these scenarios due to strong occlusions and limited camera viewpoints. Current 3D human pose estimation approaches are rather vulnerable in such conditions. In this work we present a novel approach for robust 3D human pose estimation in the context of human-robot collaboration. Instead of relying on noisy 2D features triangulation, we perform multi-view fusion on 3D skeletons provided by absolute monocular methods. Accurate 3D pose estimation is then obtained via reprojection error optimization, introducing limbs length symmetry constraints. We evaluate our approach on the public dataset Human3.6M and on a novel version Human3.6M-Occluded, derived adding synthetic occlusions on the camera views with the purpose of testing pose estimation algorithms under severe occlusions. We further validate our method on real human-robot collaboration workcells, in which we strongly surpass current 3D human pose estimation methods. Our approach outperforms state-of-the-art multi-view human pose estimation techniques and demonstrates superior capabilities in handling challenging scenarios with strong occlusions, representing a reliable and effective solution for real human-robot collaboration setups.
Multi-Camera Hand-Eye Calibration for Human-Robot Collaboration in Industrial Robotic Workcells
Jun 17, 2024



In industrial scenarios, effective human-robot collaboration relies on multi-camera systems to robustly monitor human operators despite the occlusions that typically show up in a robotic workcell. In this scenario, precise localization of the person in the robot coordinate system is essential, making the hand-eye calibration of the camera network critical. This process presents significant challenges when high calibration accuracy should be achieved in short time to minimize production downtime, and when dealing with extensive camera networks used for monitoring wide areas, such as industrial robotic workcells. Our paper introduces an innovative and robust multi-camera hand-eye calibration method, designed to optimize each camera's pose relative to both the robot's base and to each other camera. This optimization integrates two types of key constraints: i) a single board-to-end-effector transformation, and ii) the relative camera-to-camera transformations. We demonstrate the superior performance of our method through comprehensive experiments employing the METRIC dataset and real-world data collected on industrial scenarios, showing notable advancements over state-of-the-art techniques even using less than 10 images. Additionally, we release an open-source version of our multi-camera hand-eye calibration algorithm at https://github.com/davidea97/Multi-Camera-Hand-Eye-Calibration.git.
Show and Grasp: Few-shot Semantic Segmentation for Robot Grasping through Zero-shot Foundation Models
Apr 19, 2024



The ability of a robot to pick an object, known as robot grasping, is crucial for several applications, such as assembly or sorting. In such tasks, selecting the right target to pick is as essential as inferring a correct configuration of the gripper. A common solution to this problem relies on semantic segmentation models, which often show poor generalization to unseen objects and require considerable time and massive data to be trained. To reduce the need for large datasets, some grasping pipelines exploit few-shot semantic segmentation models, which are capable of recognizing new classes given a few examples. However, this often comes at the cost of limited performance and fine-tuning is required to be effective in robot grasping scenarios. In this work, we propose to overcome all these limitations by combining the impressive generalization capability reached by foundation models with a high-performing few-shot classifier, working as a score function to select the segmentation that is closer to the support set. The proposed model is designed to be embedded in a grasp synthesis pipeline. The extensive experiments using one or five examples show that our novel approach overcomes existing performance limitations, improving the state of the art both in few-shot semantic segmentation on the Graspnet-1B (+10.5% mIoU) and Ocid-grasp (+1.6% AP) datasets, and real-world few-shot grasp synthesis (+21.7% grasp accuracy). The project page is available at: https://leobarcellona.github.io/showandgrasp.github.io/