 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning global control of underactuated systems with Model-Based Reinforcement Learning
Apr 09, 2025



This short paper describes our proposed solution for the third edition of the "AI Olympics with RealAIGym" competition, held at ICRA 2025. We employed Monte-Carlo Probabilistic Inference for Learning Control (MC-PILCO), an MBRL algorithm recognized for its exceptional data efficiency across various low-dimensional robotic tasks, including cart-pole, ball \& plate, and Furuta pendulum systems. MC-PILCO optimizes a system dynamics model using interaction data, enabling policy refinement through simulation rather than direct system data optimization. This approach has proven highly effective in physical systems, offering greater data efficiency than Model-Free (MF) alternatives. Notably, MC-PILCO has previously won the first two editions of this competition, demonstrating its robustness in both simulated and real-world environments. Besides briefly reviewing the algorithm, we discuss the most critical aspects of the MC-PILCO implementation in the tasks at hand: learning a global policy for the pendubot and acrobot systems.
Reinforcement Learning for Robust Athletic Intelligence: Lessons from the 2nd 'AI Olympics with RealAIGym' Competition
Mar 19, 2025In the field of robotics many different approaches ranging from classical planning over optimal control to reinforcement learning (RL) are developed and borrowed from other fields to achieve reliable control in diverse tasks. In order to get a clear understanding of their individual strengths and weaknesses and their applicability in real world robotic scenarios is it important to benchmark and compare their performances not only in a simulation but also on real hardware. The '2nd AI Olympics with RealAIGym' competition was held at the IROS 2024 conference to contribute to this cause and evaluate different controllers according to their ability to solve a dynamic control problem on an underactuated double pendulum system with chaotic dynamics. This paper describes the four different RL methods submitted by the participating teams, presents their performance in the swing-up task on a real double pendulum, measured against various criteria, and discusses their transferability from simulation to real hardware and their robustness to external disturbances.
Towards Autonomous Reinforcement Learning for Real-World Robotic Manipulation with Large Language Models
Mar 07, 2025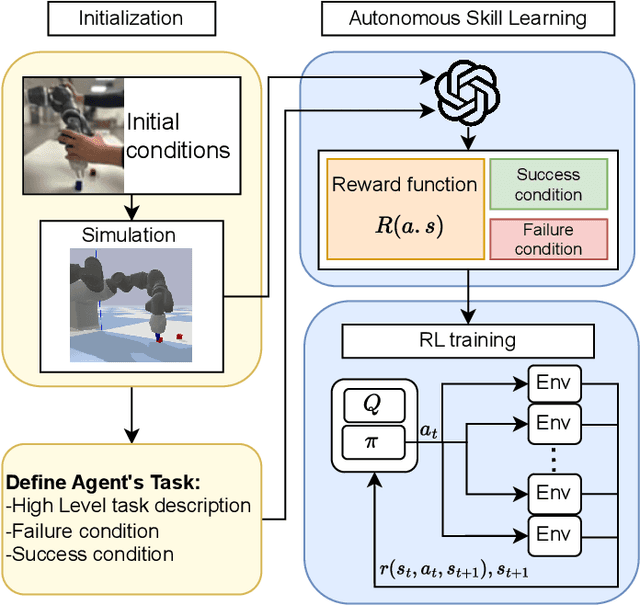
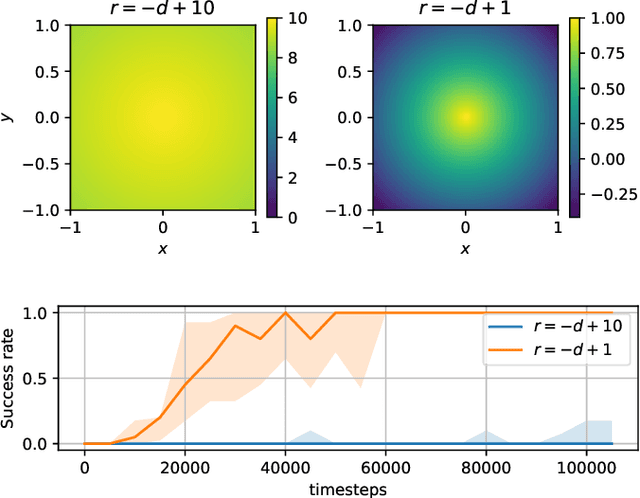
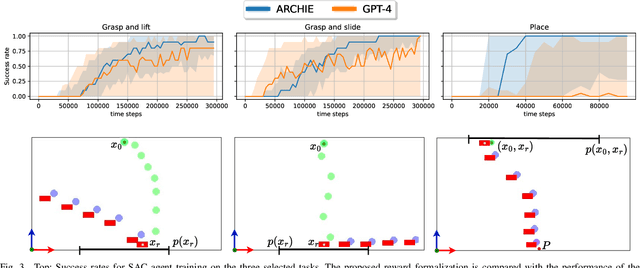
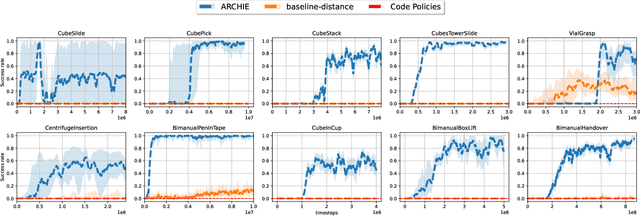
Recent advancements in Large Language Models (LLMs) and Visual Language Models (VLMs) have significantly impacted robotics, enabling high-level semantic motion planning applications. Reinforcement Learning (RL), a complementary paradigm, enables agents to autonomously optimize complex behaviors through interaction and reward signals. However, designing effective reward functions for RL remains challenging, especially in real-world tasks where sparse rewards are insufficient and dense rewards require elaborate design. In this work, we propose Autonomous Reinforcement learning for Complex HumanInformed Environments (ARCHIE), an unsupervised pipeline leveraging GPT-4, a pre-trained LLM, to generate reward functions directly from natural language task descriptions. The rewards are used to train RL agents in simulated environments, where we formalize the reward generation process to enhance feasibility. Additionally, GPT-4 automates the coding of task success criteria, creating a fully automated, one-shot procedure for translating human-readable text into deployable robot skills. Our approach is validated through extensive simulated experiments on single-arm and bi-manual manipulation tasks using an ABB YuMi collaborative robot, highlighting its practicality and effectiveness. Tasks are demonstrated on the real robot setup.
Data efficient Robotic Object Throwing with Model-Based Reinforcement Learning
Feb 08, 2025



Pick-and-place (PnP) operations, featuring object grasping and trajectory planning, are fundamental in industrial robotics applications. Despite many advancements in the field, PnP is limited by workspace constraints, reducing flexibility. Pick-and-throw (PnT) is a promising alternative where the robot throws objects to target locations, leveraging extrinsic resources like gravity to improve efficiency and expand the workspace. However, PnT execution is complex, requiring precise coordination of high-speed movements and object dynamics. Solutions to the PnT problem are categorized into analytical and learning-based approaches. Analytical methods focus on system modeling and trajectory generation but are time-consuming and offer limited generalization. Learning-based solutions, in particular Model-Free Reinforcement Learning (MFRL), offer automation and adaptability but require extensive interaction time. This paper introduces a Model-Based Reinforcement Learning (MBRL) framework, MC-PILOT, which combines data-driven modeling with policy optimization for efficient and accurate PnT tasks. MC-PILOT accounts for model uncertainties and release errors, demonstrating superior performance in simulations and real-world tests with a Franka Emika Panda manipulator. The proposed approach generalizes rapidly to new targets, offering advantages over analytical and Model-Free methods.
Edge Delayed Deep Deterministic Policy Gradient: efficient continuous control for edge scenarios
Dec 09, 2024Deep Reinforcement Learning is gaining increasing attention thanks to its capability to learn complex policies in high-dimensional settings. Recent advancements utilize a dual-network architecture to learn optimal policies through the Q-learning algorithm. However, this approach has notable drawbacks, such as an overestimation bias that can disrupt the learning process and degrade the performance of the resulting policy. To address this, novel algorithms have been developed that mitigate overestimation bias by employing multiple Q-functions. Edge scenarios, which prioritize privacy, have recently gained prominence. In these settings, limited computational resources pose a significant challenge for complex Machine Learning approaches, making the efficiency of algorithms crucial for their performance. In this work, we introduce a novel Reinforcement Learning algorithm tailored for edge scenarios, called Edge Delayed Deep Deterministic Policy Gradient (EdgeD3). EdgeD3 enhances the Deep Deterministic Policy Gradient (DDPG) algorithm, achieving significantly improved performance with $25\%$ less Graphics Process Unit (GPU) time while maintaining the same memory usage. Additionally, EdgeD3 consistently matches or surpasses the performance of state-of-the-art methods across various benchmarks, all while using $30\%$ fewer computational resources and requiring $30\%$ less memory.
Learning control of underactuated double pendulum with Model-Based Reinforcement Learning
Sep 09, 2024



This report describes our proposed solution for the second AI Olympics competition held at IROS 2024. Our solution is based on a recent Model-Based Reinforcement Learning algorithm named MC-PILCO. Besides briefly reviewing the algorithm, we discuss the most critical aspects of the MC-PILCO implementation in the tasks at hand.
AI Olympics challenge with Evolutionary Soft Actor Critic
Sep 02, 2024

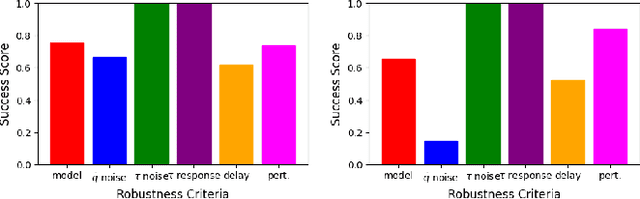

In the following report, we describe the solution we propose for the AI Olympics competition held at IROS 2024. Our solution is based on a Model-free Deep Reinforcement Learning approach combined with an evolutionary strategy. We will briefly describe the algorithms that have been used and then provide details of the approach
Exploiting Estimation Bias in Deep Double Q-Learning for Actor-Critic Methods
Feb 14, 2024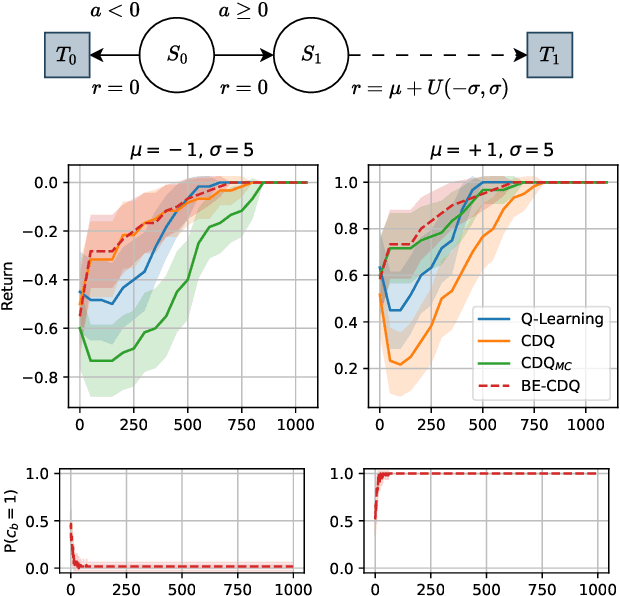

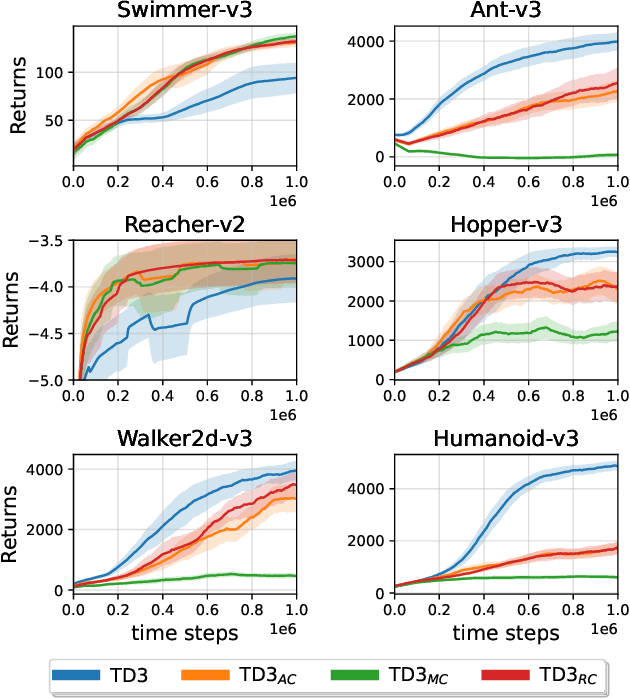

This paper introduces innovative methods in Reinforcement Learning (RL), focusing on addressing and exploiting estimation biases in Actor-Critic methods for continuous control tasks, using Deep Double Q-Learning. We propose two novel algorithms: Expectile Delayed Deep Deterministic Policy Gradient (ExpD3) and Bias Exploiting - Twin Delayed Deep Deterministic Policy Gradient (BE-TD3). ExpD3 aims to reduce overestimation bias with a single $Q$ estimate, offering a balance between computational efficiency and performance, while BE-TD3 is designed to dynamically select the most advantageous estimation bias during training. Our extensive experiments across various continuous control tasks demonstrate the effectiveness of our approaches. We show that these algorithms can either match or surpass existing methods like TD3, particularly in environments where estimation biases significantly impact learning. The results underline the importance of bias exploitation in improving policy learning in RL.