 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Structured Robot Policies from Vision-Language Models via Synthetic Neuro-Symbolic Supervision
Apr 03, 2026Vision-language models (VLMs) have recently demonstrated strong capabilities in mapping multimodal observations to robot behaviors. However, most current approaches rely on end-to-end visuomotor policies that remain opaque and difficult to analyze, limiting their use in safety-critical robotic applications. In contrast, classical robotic systems often rely on structured policy representations that provide interpretability, modularity, and reactive execution. This work investigates how foundation models can be specialized to generate structured robot policies grounded in multimodal perception, bridging high-dimensional learning and symbolic control. We propose a neuro-symbolic approach in which a VLM synthesizes executable Behavior Tree policies from visual observations, natural language instructions, and structured system specifications. To enable scalable supervision without manual annotation, we introduce an automated pipeline that generates a synthetic multimodal dataset of domain-randomized scenes paired with instruction-policy examples produced by a foundation model. Real-world experiments on two robotic manipulators show that structured policies learned entirely from synthetic supervision transfer successfully to physical systems. The results indicate that foundation models can be adapted to produce interpretable and structured robot policies, providing an alternative to opaque end-to-end approaches for multimodal robot decision making.
Active Cross-Modal Visuo-Tactile Perception of Deformable Linear Objects
Jan 20, 2026This paper presents a novel cross-modal visuo-tactile perception framework for the 3D shape reconstruction of deformable linear objects (DLOs), with a specific focus on cables subject to severe visual occlusions. Unlike existing methods relying predominantly on vision, whose performance degrades under varying illumination, background clutter, or partial visibility, the proposed approach integrates foundation-model-based visual perception with adaptive tactile exploration. The visual pipeline exploits SAM for instance segmentation and Florence for semantic refinement, followed by skeletonization, endpoint detection, and point-cloud extraction. Occluded cable segments are autonomously identified and explored with a tactile sensor, which provides local point clouds that are merged with the visual data through Euclidean clustering and topology-preserving fusion. A B-spline interpolation driven by endpoint-guided point sorting yields a smooth and complete reconstruction of the cable shape. Experimental validation using a robotic manipulator equipped with an RGB-D camera and a tactile pad demonstrates that the proposed framework accurately reconstructs both simple and highly curved single or multiple cable configurations, even when large portions are occluded. These results highlight the potential of foundation-model-enhanced cross-modal perception for advancing robotic manipulation of deformable objects.
Real2Sim based on Active Perception with automatically VLM-generated Behavior Trees
Jan 13, 2026Constructing an accurate simulation model of real-world environments requires reliable estimation of physical parameters such as mass, geometry, friction, and contact surfaces. Traditional real-to-simulation (Real2Sim) pipelines rely on manual measurements or fixed, pre-programmed exploration routines, which limit their adaptability to varying tasks and user intents. This paper presents a Real2Sim framework that autonomously generates and executes Behavior Trees for task-specific physical interactions to acquire only the parameters required for a given simulation objective, without relying on pre-defined task templates or expert-designed exploration routines. Given a high-level user request, an incomplete simulation description, and an RGB observation of the scene, a vision-language model performs multi-modal reasoning to identify relevant objects, infer required physical parameters, and generate a structured Behavior Tree composed of elementary robotic actions. The resulting behavior is executed on a torque-controlled Franka Emika Panda, enabling compliant, contact-rich interactions for parameter estimation. The acquired measurements are used to automatically construct a physics-aware simulation. Experimental results on the real manipulator demonstrate estimation of object mass, surface height, and friction-related quantities across multiple scenarios, including occluded objects and incomplete prior models. The proposed approach enables interpretable, intent-driven, and autonomously Real2Sim pipelines, bridging high-level reasoning with physically-grounded robotic interaction.
Towards Autonomous Reinforcement Learning for Real-World Robotic Manipulation with Large Language Models
Mar 07, 2025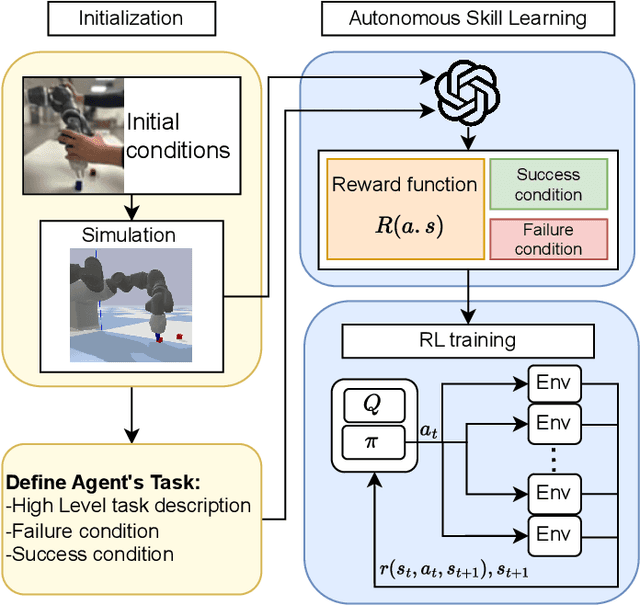
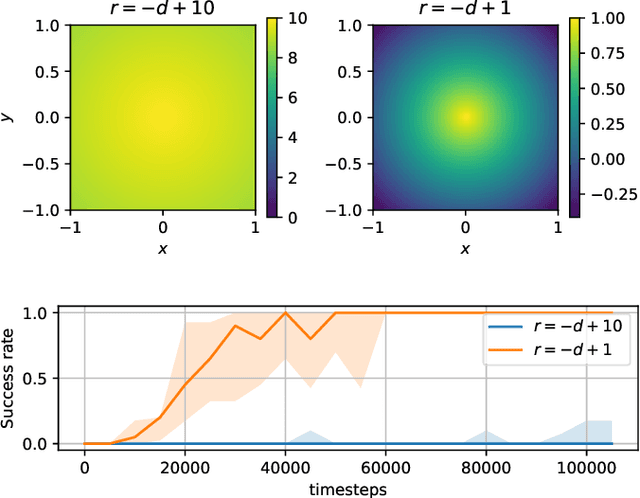
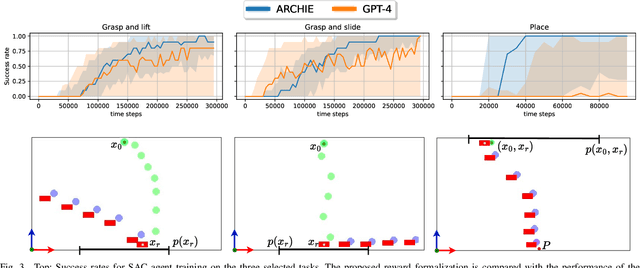
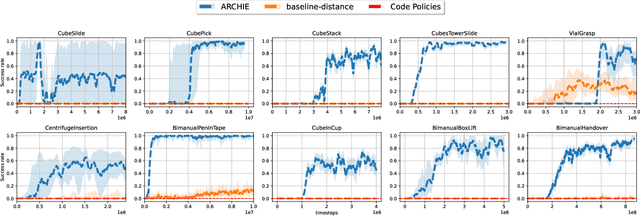
Recent advancements in Large Language Models (LLMs) and Visual Language Models (VLMs) have significantly impacted robotics, enabling high-level semantic motion planning applications. Reinforcement Learning (RL), a complementary paradigm, enables agents to autonomously optimize complex behaviors through interaction and reward signals. However, designing effective reward functions for RL remains challenging, especially in real-world tasks where sparse rewards are insufficient and dense rewards require elaborate design. In this work, we propose Autonomous Reinforcement learning for Complex HumanInformed Environments (ARCHIE), an unsupervised pipeline leveraging GPT-4, a pre-trained LLM, to generate reward functions directly from natural language task descriptions. The rewards are used to train RL agents in simulated environments, where we formalize the reward generation process to enhance feasibility. Additionally, GPT-4 automates the coding of task success criteria, creating a fully automated, one-shot procedure for translating human-readable text into deployable robot skills. Our approach is validated through extensive simulated experiments on single-arm and bi-manual manipulation tasks using an ABB YuMi collaborative robot, highlighting its practicality and effectiveness. Tasks are demonstrated on the real robot setup.
Comparison between Behavior Trees and Finite State Machines
May 25, 2024



Behavior Trees (BTs) were first conceived in the computer games industry as a tool to model agent behavior, but they received interest also in the robotics community as an alternative policy design to Finite State Machines (FSMs). The advantages of BTs over FSMs had been highlighted in many works, but there is no thorough practical comparison of the two designs. Such a comparison is particularly relevant in the robotic industry, where FSMs have been the state-of-the-art policy representation for robot control for many years. In this work we shed light on this matter by comparing how BTs and FSMs behave when controlling a robot in a mobile manipulation task. The comparison is made in terms of reactivity, modularity, readability, and design. We propose metrics for each of these properties, being aware that while some are tangible and objective, others are more subjective and implementation dependent. The practical comparison is performed in a simulation environment with validation on a real robot. We find that although the robot's behavior during task solving is independent on the policy representation, maintaining a BT rather than an FSM becomes easier as the task increases in complexity.
A Framework for Learning Behavior Trees in Collaborative Robotic Applications
Mar 20, 2023



In modern industrial collaborative robotic applications, it is desirable to create robot programs automatically, intuitively, and time-efficiently. Moreover, robots need to be controlled by reactive policies to face the unpredictability of the environment they operate in. In this paper we propose a framework that combines a method that learns Behavior Trees (BTs) from demonstration with a method that evolves them with Genetic Programming (GP) for collaborative robotic applications. The main contribution of this paper is to show that by combining the two learning methods we obtain a method that allows non-expert users to semi-automatically, time-efficiently, and interactively generate BTs. We validate the framework with a series of manipulation experiments. The BT is fully learnt in simulation and then transferred to a real collaborative robot.
On the programming effort required to generate Behavior Trees and Finite State Machines for robotic applications
Sep 15, 2022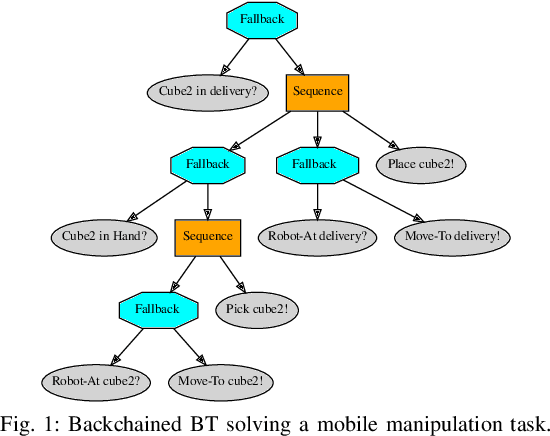
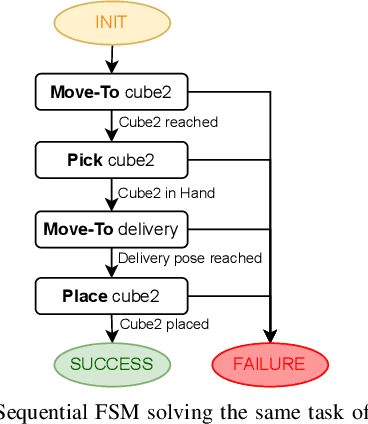
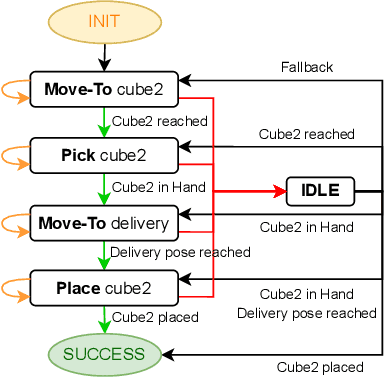

In this paper we provide a practical demonstration of how the modularity in a Behavior Tree (BT) decreases the effort in programming a robot task when compared to a Finite State Machine (FSM). In recent years the way to represent a task plan to control an autonomous agent has been shifting from the standard FSM towards BTs. Many works in the literature have highlighted and proven the benefits of such design compared to standard approaches, especially in terms of modularity, reactivity and human readability. However, these works have often failed in providing a tangible comparison in the implementation of those policies and the programming effort required to modify them. This is a relevant aspect in many robotic applications, where the design choice is dictated both by the robustness of the policy and by the time required to program it. In this work, we compare backward chained BTs with a fault-tolerant design of FSMs by evaluating the cost to modify them. We validate the analysis with a set of experiments in a simulation environment where a mobile manipulator solves an item fetching task.
Learning Deep Neural Policies with Stability Guarantees
Mar 30, 2021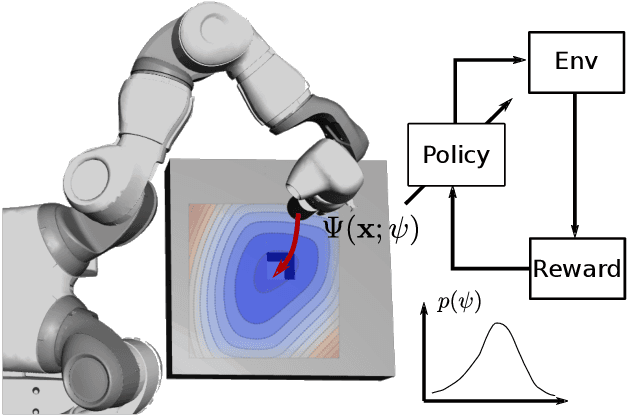
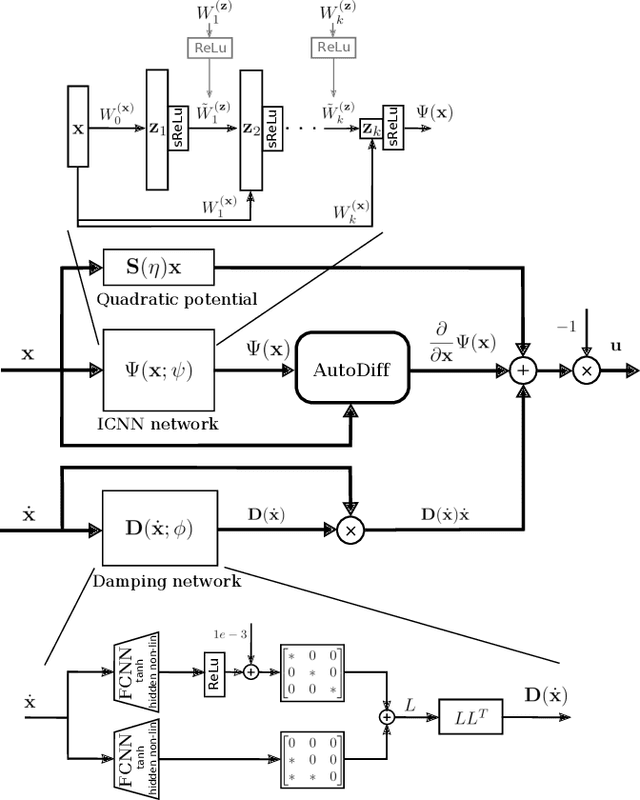

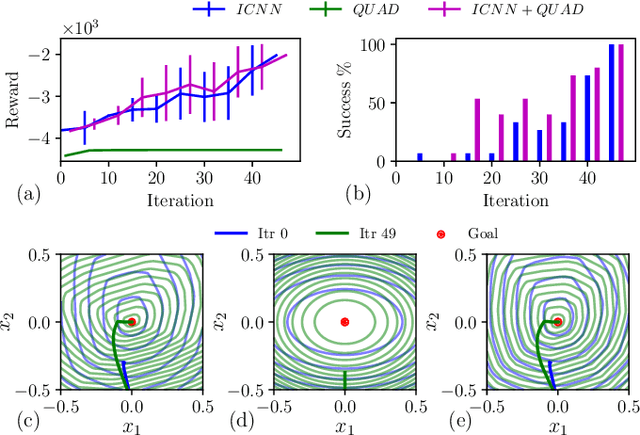
Reinforcement learning (RL) has been successfully used to solve various robotic control tasks. However, most of the existing works do not address the issue of control stability. This is in sharp contrast to the control theory community where the well-established norm is to prove stability whenever a control law is synthesized. What makes guaranteeing stability during RL difficult is threefold: non interpretable neural network policies, unknown system dynamics and random exploration. We contribute towards solving the stable RL problem in the context of robotic manipulation that may involve physical contact with the environment. Our solution is derived from physics-based prior that originates from Lagrangian mechanics and does not involve learning any dynamics model. We show how to parameterize the resulting $\textit{energy shaping}$ policy as a deep neural network that consists of a convex potential function and a velocity dependent damping component. Our experiments, that include a real-world peg insertion task by a 7-DOF robot, validate the proposed policy structure and demonstrate the benefits of stability in RL.
Learning Behavior Trees with Genetic Programming in Unpredictable Environments
Nov 06, 2020
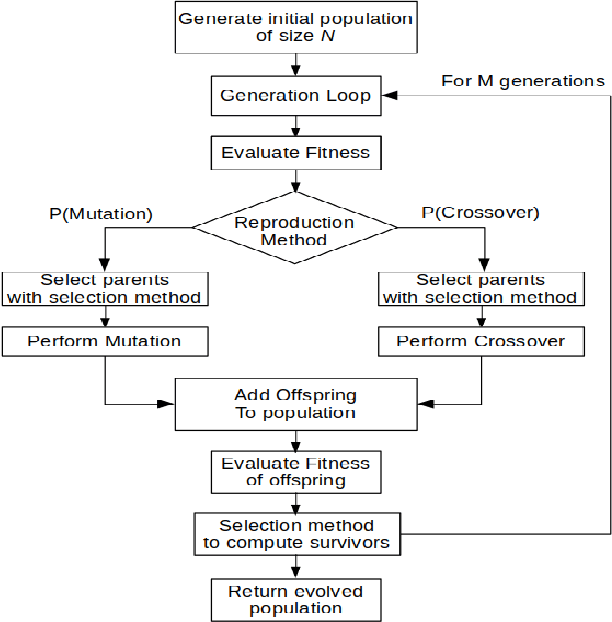
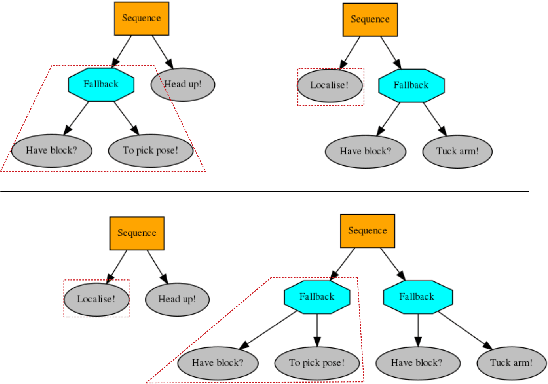

Modern industrial applications require robots to be able to operate in unpredictable environments, and programs to be created with a minimal effort, as there may be frequent changes to the task. In this paper, we show that genetic programming can be effectively used to learn the structure of a behavior tree (BT) to solve a robotic task in an unpredictable environment. Moreover, we propose to use a simple simulator for the learning and demonstrate that the learned BTs can solve the same task in a realistic simulator, reaching convergence without the need for task specific heuristics. The learned solution is tolerant to faults, making our method appealing for real robotic applications.
Learning Stable Normalizing-Flow Control for Robotic Manipulation
Oct 30, 2020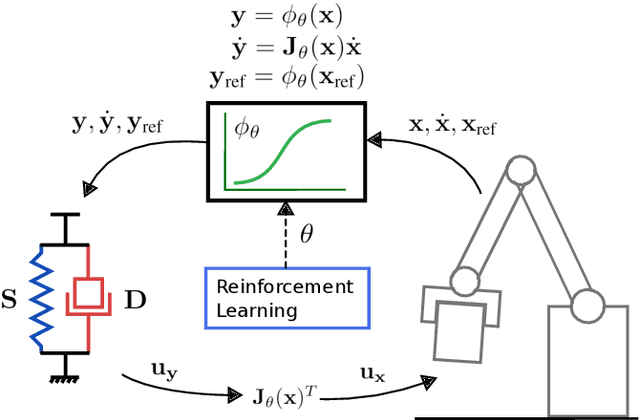


Reinforcement Learning (RL) of robotic manipulation skills, despite its impressive successes, stands to benefit from incorporating domain knowledge from control theory. One of the most important properties that is of interest is control stability. Ideally, one would like to achieve stability guarantees while staying within the framework of state-of-the-art deep RL algorithms. Such a solution does not exist in general, especially one that scales to complex manipulation tasks. We contribute towards closing this gap by introducing $\textit{normalizing-flow}$ control structure, that can be deployed in any latest deep RL algorithms. While stable exploration is not guaranteed, our method is designed to ultimately produce deterministic controllers with provable stability. In addition to demonstrating our method on challenging contact-rich manipulation tasks, we also show that it is possible to achieve considerable exploration efficiency--reduced state space coverage and actuation efforts--without losing learning efficiency.