 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Deep Neural Policies with Stability Guarantees
Mar 30, 2021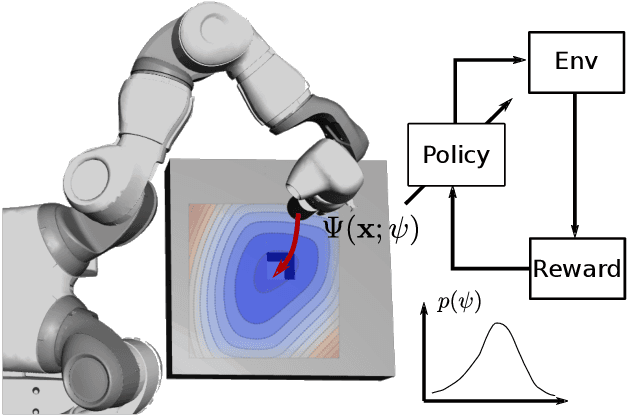
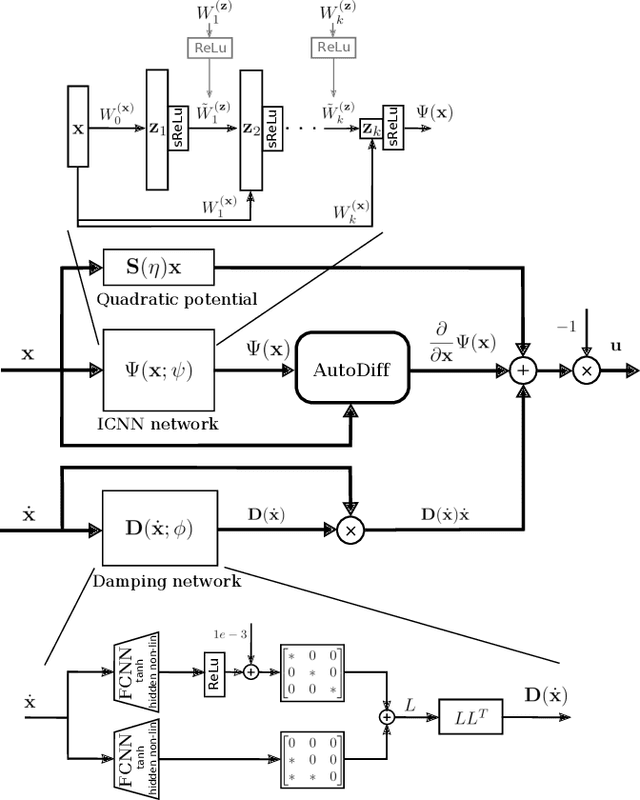

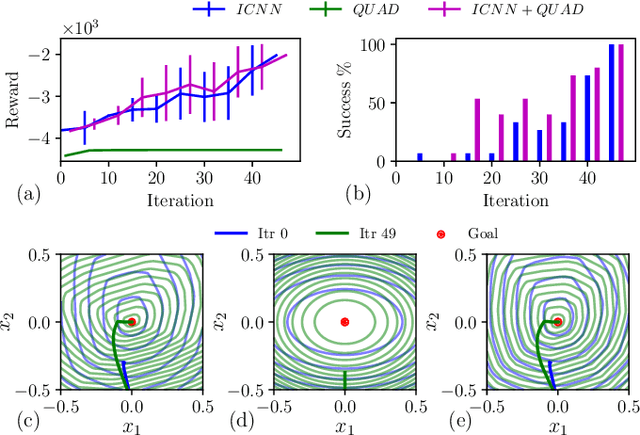
Reinforcement learning (RL) has been successfully used to solve various robotic control tasks. However, most of the existing works do not address the issue of control stability. This is in sharp contrast to the control theory community where the well-established norm is to prove stability whenever a control law is synthesized. What makes guaranteeing stability during RL difficult is threefold: non interpretable neural network policies, unknown system dynamics and random exploration. We contribute towards solving the stable RL problem in the context of robotic manipulation that may involve physical contact with the environment. Our solution is derived from physics-based prior that originates from Lagrangian mechanics and does not involve learning any dynamics model. We show how to parameterize the resulting $\textit{energy shaping}$ policy as a deep neural network that consists of a convex potential function and a velocity dependent damping component. Our experiments, that include a real-world peg insertion task by a 7-DOF robot, validate the proposed policy structure and demonstrate the benefits of stability in RL.
Learning Stable Normalizing-Flow Control for Robotic Manipulation
Oct 30, 2020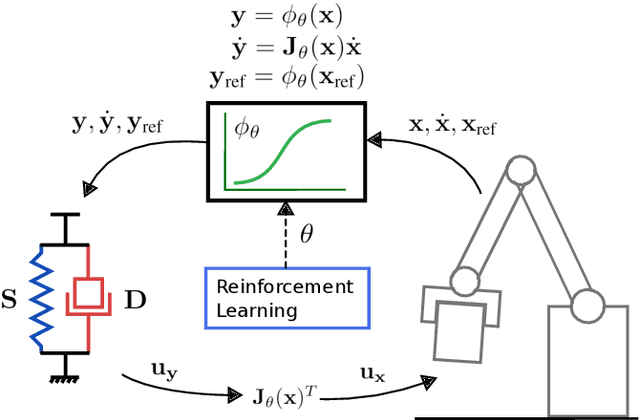
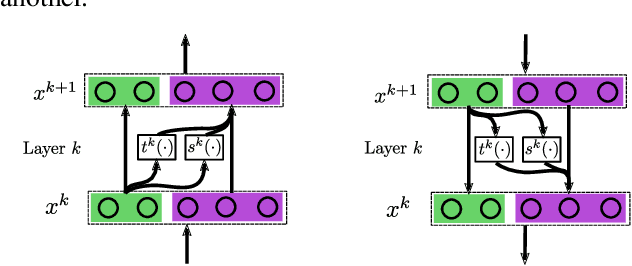


Reinforcement Learning (RL) of robotic manipulation skills, despite its impressive successes, stands to benefit from incorporating domain knowledge from control theory. One of the most important properties that is of interest is control stability. Ideally, one would like to achieve stability guarantees while staying within the framework of state-of-the-art deep RL algorithms. Such a solution does not exist in general, especially one that scales to complex manipulation tasks. We contribute towards closing this gap by introducing $\textit{normalizing-flow}$ control structure, that can be deployed in any latest deep RL algorithms. While stable exploration is not guaranteed, our method is designed to ultimately produce deterministic controllers with provable stability. In addition to demonstrating our method on challenging contact-rich manipulation tasks, we also show that it is possible to achieve considerable exploration efficiency--reduced state space coverage and actuation efforts--without losing learning efficiency.
Probabilistic Model Learning and Long-term Prediction for Contact-rich Manipulation Tasks
Sep 11, 2019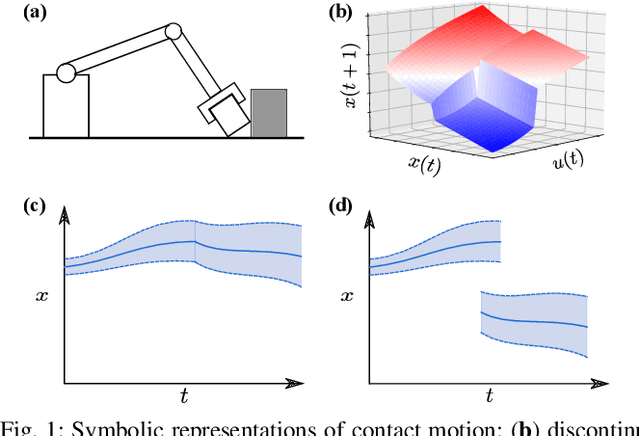
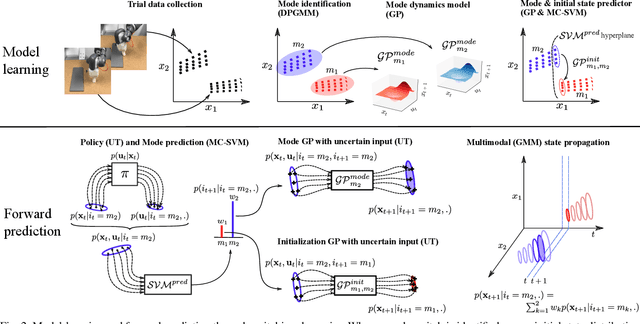
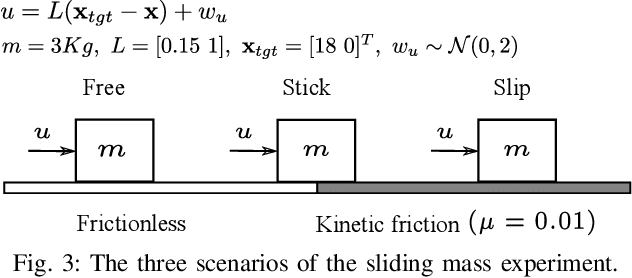
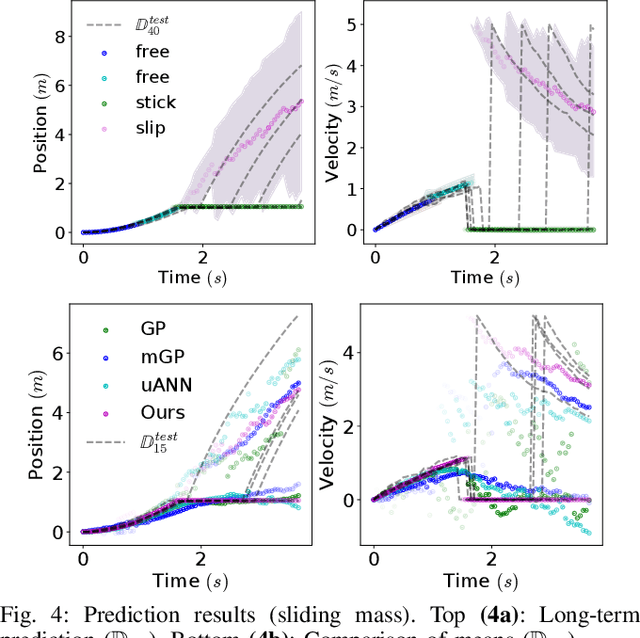
Learning dynamics models is an essential component of model-based reinforcement learning. The learned model can be used for multi-step ahead predictions of the state variable, a process referred to as long-term prediction. Due to the recursive nature of the predictions, the accuracy has to be good enough to prevent significant error buildup. Accurate model learning in contact-rich manipulation is challenging due to the presence of varying dynamics regimes and discontinuities. Another challenge is the discontinuity in state evolution caused by impacting conditions. Building on the approach of representing contact dynamics by a system of switching models, we present a solution that also supports discontinuous state evolution. We evaluate our method on a contact-rich motion task, involving a 7-DOF industrial robot, using a trajectory-centric policy and show that it can effectively propagate state distributions through discontinuities.