 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Stable Normalizing-Flow Control for Robotic Manipulation
Paper and Code
Oct 30, 2020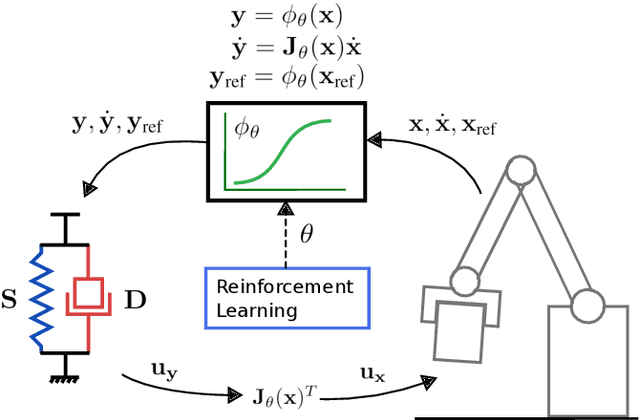


Reinforcement Learning (RL) of robotic manipulation skills, despite its impressive successes, stands to benefit from incorporating domain knowledge from control theory. One of the most important properties that is of interest is control stability. Ideally, one would like to achieve stability guarantees while staying within the framework of state-of-the-art deep RL algorithms. Such a solution does not exist in general, especially one that scales to complex manipulation tasks. We contribute towards closing this gap by introducing $\textit{normalizing-flow}$ control structure, that can be deployed in any latest deep RL algorithms. While stable exploration is not guaranteed, our method is designed to ultimately produce deterministic controllers with provable stability. In addition to demonstrating our method on challenging contact-rich manipulation tasks, we also show that it is possible to achieve considerable exploration efficiency--reduced state space coverage and actuation efforts--without losing learning efficiency.