 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Human Action Descriptor Based on Motion Coordination
Nov 20, 2019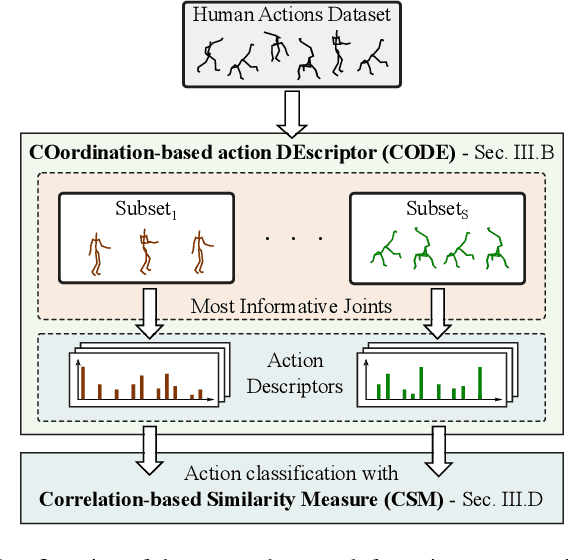
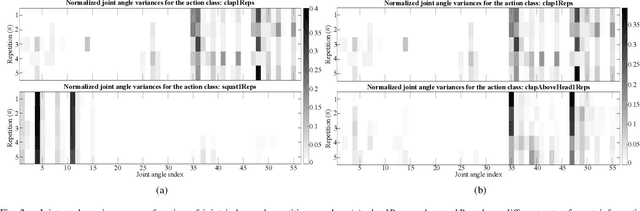
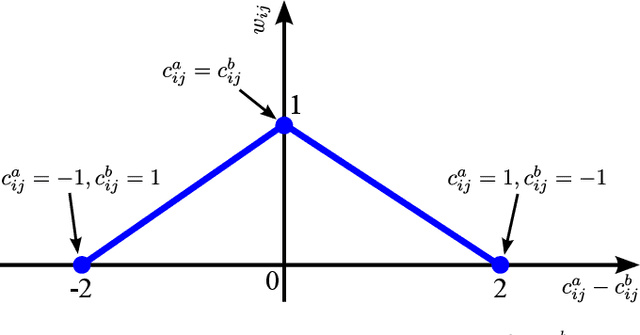
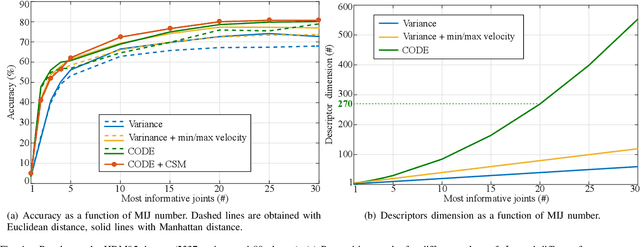
In this paper, we present a descriptor for human whole-body actions based on motion coordination. We exploit the principle, well known in neuromechanics, that humans move their joints in a coordinated fashion. Our coordination-based descriptor (CODE) is computed by two main steps. The first step is to identify the most informative joints which characterize the motion. The second step enriches the descriptor considering minimum and maximum joint velocities and the correlations between the most informative joints. In order to compute the distances between action descriptors, we propose a novel correlation-based similarity measure. The performance of CODE is tested on two public datasets, namely HDM05 and Berkeley MHAD, and compared with state-of-the-art approaches, showing recognition results.
A Preliminary Study on the Learning Informativeness of Data Subsets
Sep 28, 2015


Estimating the internal state of a robotic system is complex: this is performed from multiple heterogeneous sensor inputs and knowledge sources. Discretization of such inputs is done to capture saliences, represented as symbolic information, which often presents structure and recurrence. As these sequences are used to reason over complex scenarios, a more compact representation would aid exactness of technical cognitive reasoning capabilities, which are today constrained by computational complexity issues and fallback to representational heuristics or human intervention. Such problems need to be addressed to ensure timely and meaningful human-robot interaction. Our work is towards understanding the variability of learning informativeness when training on subsets of a given input dataset. This is in view of reducing the training size while retaining the majority of the symbolic learning potential. We prove the concept on human-written texts, and conjecture this work will reduce training data size of sequential instructions, while preserving semantic relations, when gathering information from large remote sources.
Towards Predicting First Daily Departure Times: a Gaussian Modeling Approach for Load Shift Forecasting
Jul 16, 2015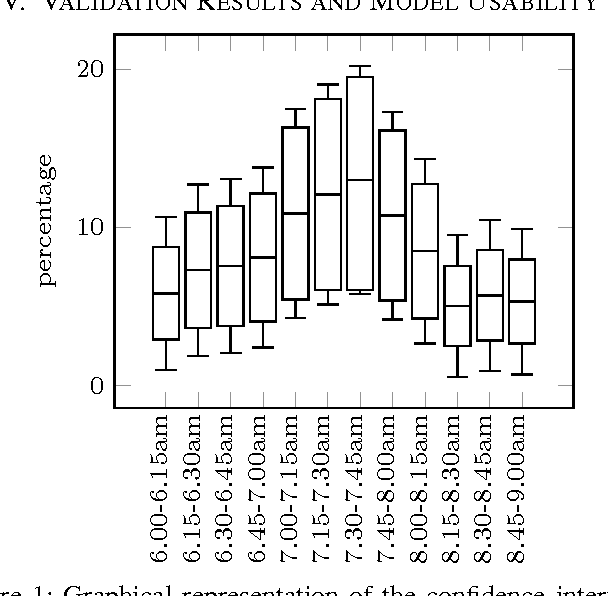
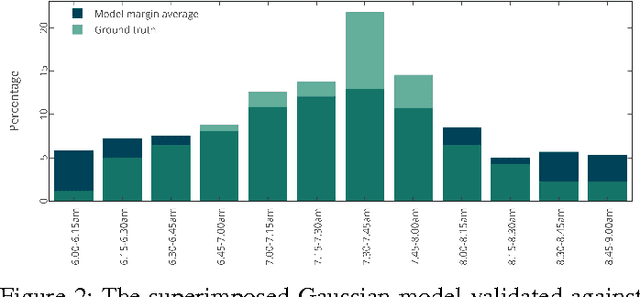
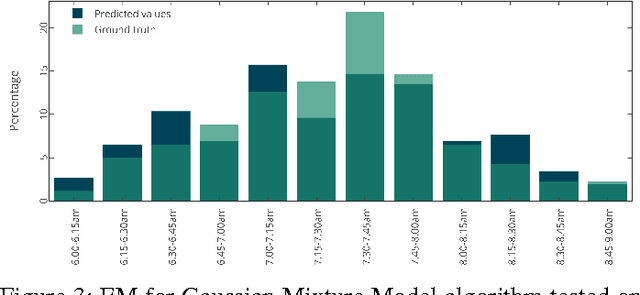
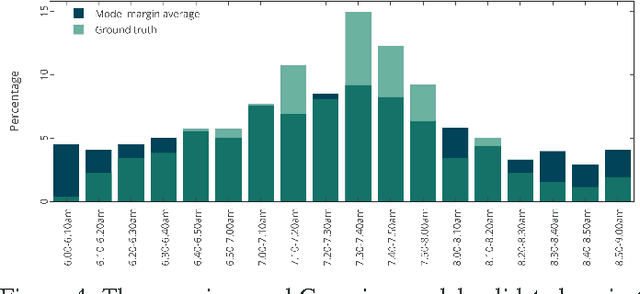
This work provides two statistical Gaussian forecasting methods for predicting First Daily Departure Times (FDDTs) of everyday use electric vehicles. This is important in smart grid applications to understand disconnection times of such mobile storage units, for instance to forecast storage of non dispatchable loads (e.g. wind and solar power). We provide a review of the relevant state-of-the-art driving behavior features towards FDDT prediction, to then propose an approximated Gaussian method which qualitatively forecasts how many vehicles will depart within a given time frame, by assuming that departure times follow a normal distribution. This method considers sampling sessions as Poisson distributions which are superimposed to obtain a single approximated Gaussian model. Given the Gaussian distribution assumption of the departure times, we also model the problem with Gaussian Mixture Models (GMM), in which the priorly set number of clusters represents the desired time granularity. Evaluation has proven that for the dataset tested, low error and high confidence ($\approx 95\%$) is possible for 15 and 10 minute intervals, and that GMM outperforms traditional modeling but is less generalizable across datasets, as it is a closer fit to the sampling data. Conclusively we discuss future possibilities and practical applications of the discussed model.
Towards Learning Object Affordance Priors from Technical Texts
Oct 30, 2014

Everyday activities performed by artificial assistants can potentially be executed naively and dangerously given their lack of common sense knowledge. This paper presents conceptual work towards obtaining prior knowledge on the usual modality (passive or active) of any given entity, and their affordance estimates, by extracting high-confidence ability modality semantic relations (X can Y relationship) from non-figurative texts, by analyzing co-occurrence of grammatical instances of subjects and verbs, and verbs and objects. The discussion includes an outline of the concept, potential and limitations, and possible feature and learning framework adoption.
Towards Structural Natural Language Formalization: Mapping Discourse to Controlled Natural Language
Dec 07, 2013
The author describes a conceptual study towards mapping grounded natural language discourse representation structures to instances of controlled language statements. This can be achieved via a pipeline of preexisting state of the art technologies, namely natural language syntax to semantic discourse mapping, and a reduction of the latter to controlled language discourse, given a set of previously learnt reduction rules. Concludingly a description on evaluation, potential and limitations for ontology-based reasoning is presented.