 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFully Dynamic Rebalancing in Dockless Bike-Sharing Systems via Deep Reinforcement Learning
May 14, 2026This paper proposes a fully dynamic Deep Reinforcement Learning (DRL) method for rebalancing dockless bike-sharing systems, overcoming the limitations of periodic, system-wide interventions. We model the service through a graph-based simulator and cast rebalancing as a Markov decision process. A DRL agent routes a single truck in real time, executing localized pick-up, drop-off, and charging actions guided by spatiotemporal criticality scores. Experiments on real-world data show significant reductions in availability failures with a minimal fleet size, while limiting spatial inequality and mobility deserts. Our approach demonstrates the value of learning-based rebalancing for efficient and reliable shared micromobility.
Balancing Efficiency and Fairness in Traffic Light Control through Deep Reinforcement Learning
May 11, 2026Urban traffic congestion presents a significant challenge for modern cities, which impacts mobility and sustainability. Traditional traffic light control systems often fail to adapt to dynamic conditions, leading to inefficiencies. This paper proposes a novel deep reinforcement learning agent for traffic light control that addresses this limitation by explicitly integrating fairness considerations for both vehicular and pedestrian traffic. Unlike prior work, our approach dynamically balances these flows based on real-time demand, moving beyond systems focused solely on vehicles. Experimental results demonstrate that our agent effectively reduces congestion while ensuring equitable service for both the categories of road users. This research contributes to a practical and adaptable solution for intelligent traffic management within the framework of smart cities, paving the way for more efficient and inclusive urban mobility.
Recurrent Deep Reinforcement Learning for Chemotherapy Control under Partial Observability
May 04, 2026Chemotherapy dose optimization can be formulated as a dynamic treatment regime, requiring sequential decisions under uncertainty that must balance tumor suppression against toxicity. However, most reinforcement learning approaches assume full observability of the patient state, a condition rarely met in clinical practice. We investigate whether memory-augmented policies can improve chemotherapy control under partial observability. To this end, we employ a recurrent TD3-based approach with separate LSTM actor-critic networks and evaluate it on the AhnChemoEnv benchmark from DTR-Bench, considering both off-policy and on-policy recurrent architectures against feed-forward TD3 and Soft Actor-Critic. Pharmacokinetic and pharmacodynamic variability are held fixed to isolate hidden-state uncertainty and observation noise and to avoid confounding effects from inter-patient variability. Across ten random seeds, recurrence yields modest benefit under full observability but substantially stronger and more stable performance under partial observability, with more consistent tumor suppression and improved normal-cell preservation. These findings indicate that memory-based policies are particularly beneficial when clinically relevant state information is incomplete or noisy.
AD4AD: Benchmarking Visual Anomaly Detection Models for Safer Autonomous Driving
Apr 16, 2026The reliability of a machine vision system for autonomous driving depends heavily on its training data distribution. When a vehicle encounters significantly different conditions, such as atypical obstacles, its perceptual capabilities can degrade substantially. Unlike many domains where errors carry limited consequences, failures in autonomous driving translate directly into physical risk for passengers, pedestrians, and other road users. To address this challenge, we explore Visual Anomaly Detection (VAD) as a solution. VAD enables the identification of anomalous objects not present during training, allowing the system to alert the driver when an unfamiliar situation is detected. Crucially, VAD models produce pixel-level anomaly maps that can guide driver attention to specific regions of concern without requiring any prior assumptions about the nature or form of the hazard. We benchmark eight state-of-the-art VAD methods on AnoVox, the largest synthetic dataset for anomaly detection in autonomous driving. In particular, we evaluate performance across four backbone architectures spanning from large networks to lightweight ones such as MobileNet and DeiT-Tiny. Our results demonstrate that VAD transfers effectively to road scenes. Notably, Tiny-Dinomaly achieves the best accuracy-efficiency trade-off for edge deployment, matching full-scale localization performance at a fraction of the memory cost. This study represents a concrete step toward safer, more responsible deployment of autonomous vehicles, ultimately improving protection for passengers, pedestrians, and all road users.
Continual Visual Anomaly Detection on the Edge: Benchmark and Efficient Solutions
Apr 07, 2026Visual Anomaly Detection (VAD) is a critical task for many applications including industrial inspection and healthcare. While VAD has been extensively studied, two key challenges remain largely unaddressed in conjunction: edge deployment, where computational resources are severely constrained, and continual learning, where models must adapt to evolving data distributions without forgetting previously acquired knowledge. Our benchmark provides guidance for the selection of the optimal backbone and VAD method under joint efficiency and adaptability constraints, characterizing the trade-offs between memory footprint, inference cost, and detection performance. Studying these challenges in isolation is insufficient, as methods designed for one setting make assumptions that break down when the other constraint is simultaneously imposed. In this work, we propose the first comprehensive benchmark for VAD on the edge in the continual learning scenario, evaluating seven VAD models across three lightweight backbone architectures. Furthermore, we propose Tiny-Dinomaly, a lightweight adaptation of the Dinomaly model built on the DINO foundation model that achieves 13x smaller memory footprint and 20x lower computational cost while improving Pixel F1 by 5 percentage points. Finally, we introduce targeted modifications to PatchCore and PaDiM to improve their efficiency in the continual learning setting.
AdapTS: Lightweight Teacher-Student Approach for Multi-Class and Continual Visual Anomaly Detection
Mar 18, 2026Visual Anomaly Detection (VAD) is crucial for industrial inspection, yet most existing methods are limited to single-category scenarios, failing to address the multi-class and continual learning demands of real-world environments. While Teacher-Student (TS) architectures are efficient, they remain unexplored for the Continual Setting. To bridge this gap, we propose AdapTS, a unified TS framework designed for multi-class and continual settings, optimized for edge deployment. AdapTS eliminates the need for two different architectures by utilizing a single shared frozen backbone and injecting lightweight trainable adapters into the student pathway. Training is enhanced via a segmentation-guided objective and synthetic Perlin noise, while a prototype-based task identification mechanism dynamically selects adapters at inference with 99\% accuracy. Experiments on MVTec AD and VisA demonstrate that AdapTS matches the performance of existing TS methods across multi-class and continual learning scenarios, while drastically reducing memory overhead. Our lightest variant, AdapTS-S, requires only 8 MB of additional memory, 13x less than STFPM (95 MB), 48x less than RD4AD (360 MB), and 149x less than DeSTSeg (1120 MB), making it a highly scalable solution for edge deployment in complex industrial environments.
VAD4Space: Visual Anomaly Detection for Planetary Surface Imagery
Mar 14, 2026Space missions generate massive volumes of high-resolution orbital and surface imagery that far exceed the capacity for manual inspection. Detecting rare phenomena is scientifically critical, yet traditional supervised learning struggles due to scarce labeled examples and closed-world assumptions that prevent discovery of genuinely novel observations. In this work, we investigate Visual Anomaly Detection (VAD) as a framework for automated discovery in planetary exploration. We present the first empirical evaluation of state-of-the-art feature-based VAD methods on real planetary imagery, encompassing both orbital lunar data and Mars rover surface imagery. To support this evaluation, we introduce two benchmarks: (i) a lunar dataset derived from Lunar Reconnaissance Orbiter Camera Narrow Angle imagery, comprising of fresh and degraded craters as anomalies alongside normal terrain; and (ii) a Mars surface dataset designed to reflect the characteristics of rover-acquired imagery. We evaluate multiple VAD approaches with a focus on computationally efficient, edge-oriented solutions suitable for onboard deployment, applicable to both orbital platforms surveying the lunar surface and surface rovers operating on Mars. Our results demonstrate that feature-based VAD methods can effectively identify rare planetary surface phenomena while remaining feasible for resource-constrained environments. By grounding anomaly detection in planetary science, this work establishes practical benchmarks and highlights the potential of open-world perception systems to support a range of mission-critical applications, including tactical planning, landing site selection, hazard detection, bandwidth-aware data prioritization, and the discovery of unanticipated geological processes.
MIRAGE: Model-agnostic Industrial Realistic Anomaly Generation and Evaluation for Visual Anomaly Detection
Mar 13, 2026Industrial visual anomaly detection (VAD) methods are typically trained on normal samples only, yet performance improves substantially when even limited anomalous data is available. Existing anomaly generation approaches either require real anomalous examples, demand expensive hardware, or produce synthetic defects that lack realism. We present MIRAGE (Model-agnostic Industrial Realistic Anomaly Generation and Evaluation), a fully automated pipeline for realistic anomalous image generation and pixel-level mask creation that requires no training and no anomalous images. Our pipeline accesses any generative model as a black box via API calls, uses a VLM for automatic defect prompt generation, and includes a CLIP-based quality filter to retain only well-aligned generated images. For mask generation at scale, we introduce a lightweight, training-free dual-branch semantic change detection module combining text-conditioned Grounding DINO features with fine-grained YOLOv26-Seg structural features. We benchmark four generation methods using Gemini 2.5 Flash Image (Nano Banana) as the generative backbone, evaluating performance on MVTec AD and VisA across two distinct tasks: (i) downstream anomaly segmentation and (ii) visual quality of the generated images, assessed via standard metrics (IS, IC-LPIPS) and a human perceptual study involving 31 participants and 1,550 pairwise votes. The results demonstrate that MIRAGE offers a scalable, accessible foundation for anomaly-aware industrial inspection that requires no real defect data. As a final contribution, we publicly release a large-scale dataset comprising 500 image-mask pairs per category for every MVTec AD and VisA class, over 13,000 pairs in total, alongside all generation prompts and pipeline code.
Towards Batch-to-Streaming Deep Reinforcement Learning for Continuous Control
Mar 09, 2026State-of-the-art deep reinforcement learning (RL) methods have achieved remarkable performance in continuous control tasks, yet their computational complexity is often incompatible with the constraints of resource-limited hardware, due to their reliance on replay buffers, batch updates, and target networks. The emerging paradigm of streaming deep RL addresses this limitation through purely online updates, achieving strong empirical performance on standard benchmarks. In this work, we propose two novel streaming deep RL algorithms, Streaming Soft Actor-Critic (S2AC) and Streaming Deterministic Actor-Critic (SDAC), explicitly designed to be compatible with state-of-the-art batch RL methods, making them particularly suitable for on-device finetuning applications such as Sim2Real transfer. Both algorithms achieve performance comparable to state-of-the-art streaming baselines on standard benchmarks without requiring tedious hyperparameter tuning. Finally, we further investigate the practical challenges of transitioning from batch to streaming learning during finetuning and propose concrete strategies to tackle them.
Function Based Isolation Forest (FuBIF): A Unifying Framework for Interpretable Isolation-Based Anomaly Detection
Nov 08, 2025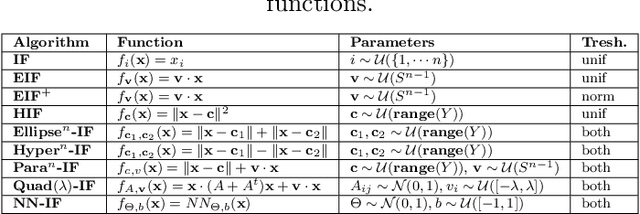
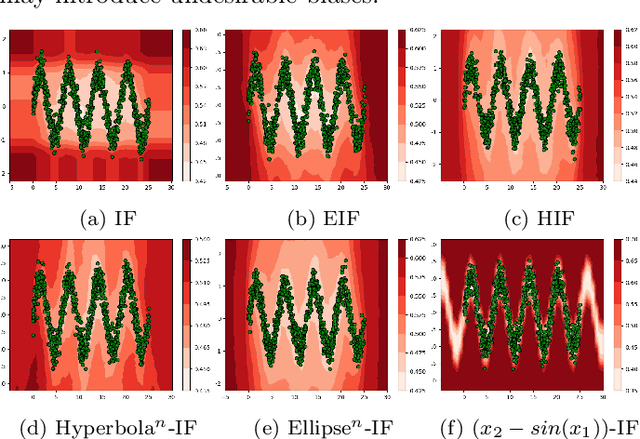
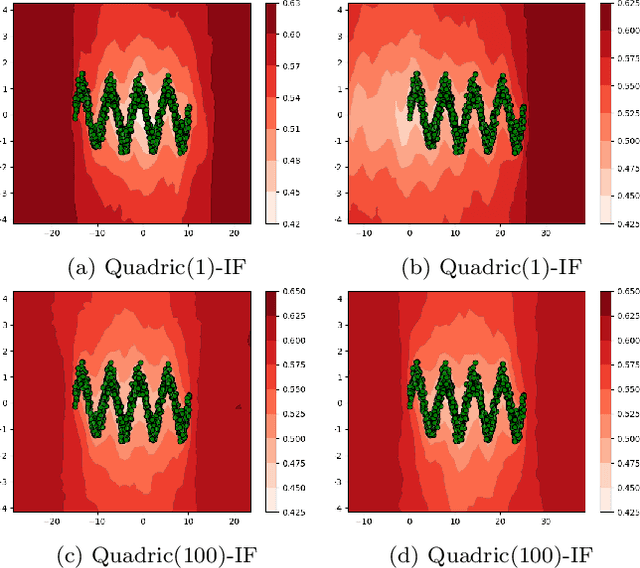
Anomaly Detection (AD) is evolving through algorithms capable of identifying outliers in complex datasets. The Isolation Forest (IF), a pivotal AD technique, exhibits adaptability limitations and biases. This paper introduces the Function-based Isolation Forest (FuBIF), a generalization of IF that enables the use of real-valued functions for dataset branching, significantly enhancing the flexibility of evaluation tree construction. Complementing this, the FuBIF Feature Importance (FuBIFFI) algorithm extends the interpretability in IF-based approaches by providing feature importance scores across possible FuBIF models. This paper details the operational framework of FuBIF, evaluates its performance against established methods, and explores its theoretical contributions. An open-source implementation is provided to encourage further research and ensure reproducibility.