 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReinforcement Learning for Durable Algorithmic Recourse
Sep 26, 2025Algorithmic recourse seeks to provide individuals with actionable recommendations that increase their chances of receiving favorable outcomes from automated decision systems (e.g., loan approvals). While prior research has emphasized robustness to model updates, considerably less attention has been given to the temporal dynamics of recourse--particularly in competitive, resource-constrained settings where recommendations shape future applicant pools. In this work, we present a novel time-aware framework for algorithmic recourse, explicitly modeling how candidate populations adapt in response to recommendations. Additionally, we introduce a novel reinforcement learning (RL)-based recourse algorithm that captures the evolving dynamics of the environment to generate recommendations that are both feasible and valid. We design our recommendations to be durable, supporting validity over a predefined time horizon T. This durability allows individuals to confidently reapply after taking time to implement the suggested changes. Through extensive experiments in complex simulation environments, we show that our approach substantially outperforms existing baselines, offering a superior balance between feasibility and long-term validity. Together, these results underscore the importance of incorporating temporal and behavioral dynamics into the design of practical recourse systems.
Simple and Effective Specialized Representations for Fair Classifiers
May 16, 2025Fair classification is a critical challenge that has gained increasing importance due to international regulations and its growing use in high-stakes decision-making settings. Existing methods often rely on adversarial learning or distribution matching across sensitive groups; however, adversarial learning can be unstable, and distribution matching can be computationally intensive. To address these limitations, we propose a novel approach based on the characteristic function distance. Our method ensures that the learned representation contains minimal sensitive information while maintaining high effectiveness for downstream tasks. By utilizing characteristic functions, we achieve a more stable and efficient solution compared to traditional methods. Additionally, we introduce a simple relaxation of the objective function that guarantees fairness in common classification models with no performance degradation. Experimental results on benchmark datasets demonstrate that our approach consistently matches or achieves better fairness and predictive accuracy than existing methods. Moreover, our method maintains robustness and computational efficiency, making it a practical solution for real-world applications.
Replay Consolidation with Label Propagation for Continual Object Detection
Sep 09, 2024


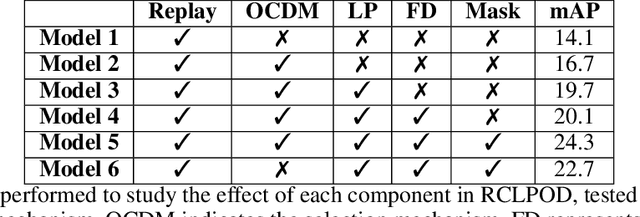
Object Detection is a highly relevant computer vision problem with many applications such as robotics and autonomous driving. Continual Learning~(CL) considers a setting where a model incrementally learns new information while retaining previously acquired knowledge. This is particularly challenging since Deep Learning models tend to catastrophically forget old knowledge while training on new data. In particular, Continual Learning for Object Detection~(CLOD) poses additional difficulties compared to CL for Classification. In CLOD, images from previous tasks may contain unknown classes that could reappear labeled in future tasks. These missing annotations cause task interference issues for replay-based approaches. As a result, most works in the literature have focused on distillation-based approaches. However, these approaches are effective only when there is a strong overlap of classes across tasks. To address the issues of current methodologies, we propose a novel technique to solve CLOD called Replay Consolidation with Label Propagation for Object Detection (RCLPOD). Based on the replay method, our solution avoids task interference issues by enhancing the buffer memory samples. Our method is evaluated against existing techniques in CLOD literature, demonstrating its superior performance on established benchmarks like VOC and COCO.
Latent Distillation for Continual Object Detection at the Edge
Sep 03, 2024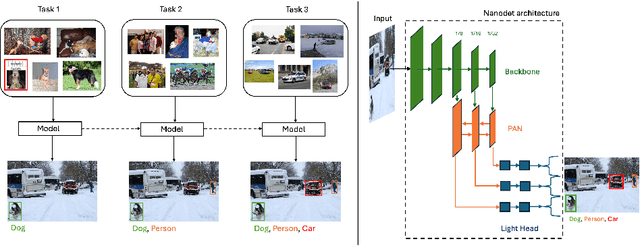
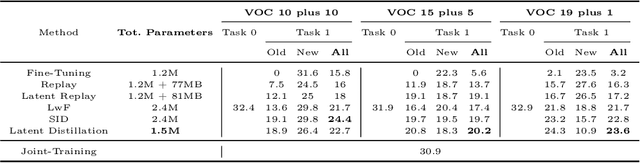
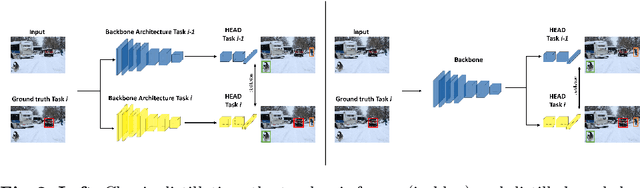
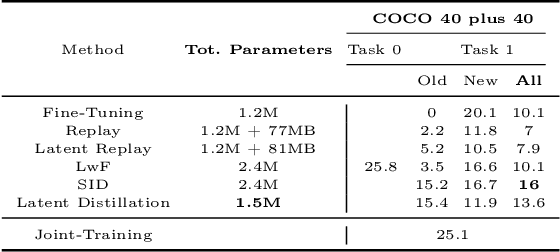
While numerous methods achieving remarkable performance exist in the Object Detection literature, addressing data distribution shifts remains challenging. Continual Learning (CL) offers solutions to this issue, enabling models to adapt to new data while maintaining performance on previous data. This is particularly pertinent for edge devices, common in dynamic environments like automotive and robotics. In this work, we address the memory and computation constraints of edge devices in the Continual Learning for Object Detection (CLOD) scenario. Specifically, (i) we investigate the suitability of an open-source, lightweight, and fast detector, namely NanoDet, for CLOD on edge devices, improving upon larger architectures used in the literature. Moreover, (ii) we propose a novel CL method, called Latent Distillation~(LD), that reduces the number of operations and the memory required by state-of-the-art CL approaches without significantly compromising detection performance. Our approach is validated using the well-known VOC and COCO benchmarks, reducing the distillation parameter overhead by 74\% and the Floating Points Operations~(FLOPs) by 56\% per model update compared to other distillation methods.
Multi-Label Continual Learning for the Medical Domain: A Novel Benchmark
Apr 11, 2024



Multi-label image classification in dynamic environments is a problem that poses significant challenges. Previous studies have primarily focused on scenarios such as Domain Incremental Learning and Class Incremental Learning, which do not fully capture the complexity of real-world applications. In this paper, we study the problem of classification of medical imaging in the scenario termed New Instances and New Classes, which combines the challenges of both new class arrivals and domain shifts in a single framework. Unlike traditional scenarios, it reflects the realistic nature of CL in domains such as medical imaging, where updates may introduce both new classes and changes in domain characteristics. To address the unique challenges posed by this complex scenario, we introduce a novel approach called Pseudo-Label Replay. This method aims to mitigate forgetting while adapting to new classes and domain shifts by combining the advantages of the Replay and Pseudo-Label methods and solving their limitations in the proposed scenario. We evaluate our proposed approach on a challenging benchmark consisting of two datasets, seven tasks, and nineteen classes, modeling a realistic Continual Learning scenario. Our experimental findings demonstrate the effectiveness of Pseudo-Label Replay in addressing the challenges posed by the complex scenario proposed. Our method surpasses existing approaches, exhibiting superior performance while showing minimal forgetting.
A Fairness-Oriented Reinforcement Learning Approach for the Operation and Control of Shared Micromobility Services
Mar 23, 2024As Machine Learning systems become increasingly popular across diverse application domains, including those with direct human implications, the imperative of equity and algorithmic fairness has risen to prominence in the Artificial Intelligence community. On the other hand, in the context of Shared Micromobility Systems, the exploration of fairness-oriented approaches remains limited. Addressing this gap, we introduce a pioneering investigation into the balance between performance optimization and algorithmic fairness in the operation and control of Shared Micromobility Services. Our study leverages the Q-Learning algorithm in Reinforcement Learning, benefiting from its convergence guarantees to ensure the robustness of our proposed approach. Notably, our methodology stands out for its ability to achieve equitable outcomes, as measured by the Gini index, across different station categories--central, peripheral, and remote. Through strategic rebalancing of vehicle distribution, our approach aims to maximize operator performance while simultaneously upholding fairness principles for users. In addition to theoretical insights, we substantiate our findings with a case study or simulation based on synthetic data, validating the efficacy of our approach. This paper underscores the critical importance of fairness considerations in shaping control strategies for Shared Micromobility Services, offering a pragmatic framework for enhancing equity in urban transportation systems.