 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContinual Visual Anomaly Detection on the Edge: Benchmark and Efficient Solutions
Apr 07, 2026Visual Anomaly Detection (VAD) is a critical task for many applications including industrial inspection and healthcare. While VAD has been extensively studied, two key challenges remain largely unaddressed in conjunction: edge deployment, where computational resources are severely constrained, and continual learning, where models must adapt to evolving data distributions without forgetting previously acquired knowledge. Our benchmark provides guidance for the selection of the optimal backbone and VAD method under joint efficiency and adaptability constraints, characterizing the trade-offs between memory footprint, inference cost, and detection performance. Studying these challenges in isolation is insufficient, as methods designed for one setting make assumptions that break down when the other constraint is simultaneously imposed. In this work, we propose the first comprehensive benchmark for VAD on the edge in the continual learning scenario, evaluating seven VAD models across three lightweight backbone architectures. Furthermore, we propose Tiny-Dinomaly, a lightweight adaptation of the Dinomaly model built on the DINO foundation model that achieves 13x smaller memory footprint and 20x lower computational cost while improving Pixel F1 by 5 percentage points. Finally, we introduce targeted modifications to PatchCore and PaDiM to improve their efficiency in the continual learning setting.
AdapTS: Lightweight Teacher-Student Approach for Multi-Class and Continual Visual Anomaly Detection
Mar 18, 2026Visual Anomaly Detection (VAD) is crucial for industrial inspection, yet most existing methods are limited to single-category scenarios, failing to address the multi-class and continual learning demands of real-world environments. While Teacher-Student (TS) architectures are efficient, they remain unexplored for the Continual Setting. To bridge this gap, we propose AdapTS, a unified TS framework designed for multi-class and continual settings, optimized for edge deployment. AdapTS eliminates the need for two different architectures by utilizing a single shared frozen backbone and injecting lightweight trainable adapters into the student pathway. Training is enhanced via a segmentation-guided objective and synthetic Perlin noise, while a prototype-based task identification mechanism dynamically selects adapters at inference with 99\% accuracy. Experiments on MVTec AD and VisA demonstrate that AdapTS matches the performance of existing TS methods across multi-class and continual learning scenarios, while drastically reducing memory overhead. Our lightest variant, AdapTS-S, requires only 8 MB of additional memory, 13x less than STFPM (95 MB), 48x less than RD4AD (360 MB), and 149x less than DeSTSeg (1120 MB), making it a highly scalable solution for edge deployment in complex industrial environments.
VAD4Space: Visual Anomaly Detection for Planetary Surface Imagery
Mar 14, 2026Space missions generate massive volumes of high-resolution orbital and surface imagery that far exceed the capacity for manual inspection. Detecting rare phenomena is scientifically critical, yet traditional supervised learning struggles due to scarce labeled examples and closed-world assumptions that prevent discovery of genuinely novel observations. In this work, we investigate Visual Anomaly Detection (VAD) as a framework for automated discovery in planetary exploration. We present the first empirical evaluation of state-of-the-art feature-based VAD methods on real planetary imagery, encompassing both orbital lunar data and Mars rover surface imagery. To support this evaluation, we introduce two benchmarks: (i) a lunar dataset derived from Lunar Reconnaissance Orbiter Camera Narrow Angle imagery, comprising of fresh and degraded craters as anomalies alongside normal terrain; and (ii) a Mars surface dataset designed to reflect the characteristics of rover-acquired imagery. We evaluate multiple VAD approaches with a focus on computationally efficient, edge-oriented solutions suitable for onboard deployment, applicable to both orbital platforms surveying the lunar surface and surface rovers operating on Mars. Our results demonstrate that feature-based VAD methods can effectively identify rare planetary surface phenomena while remaining feasible for resource-constrained environments. By grounding anomaly detection in planetary science, this work establishes practical benchmarks and highlights the potential of open-world perception systems to support a range of mission-critical applications, including tactical planning, landing site selection, hazard detection, bandwidth-aware data prioritization, and the discovery of unanticipated geological processes.
MIRAGE: Model-agnostic Industrial Realistic Anomaly Generation and Evaluation for Visual Anomaly Detection
Mar 13, 2026Industrial visual anomaly detection (VAD) methods are typically trained on normal samples only, yet performance improves substantially when even limited anomalous data is available. Existing anomaly generation approaches either require real anomalous examples, demand expensive hardware, or produce synthetic defects that lack realism. We present MIRAGE (Model-agnostic Industrial Realistic Anomaly Generation and Evaluation), a fully automated pipeline for realistic anomalous image generation and pixel-level mask creation that requires no training and no anomalous images. Our pipeline accesses any generative model as a black box via API calls, uses a VLM for automatic defect prompt generation, and includes a CLIP-based quality filter to retain only well-aligned generated images. For mask generation at scale, we introduce a lightweight, training-free dual-branch semantic change detection module combining text-conditioned Grounding DINO features with fine-grained YOLOv26-Seg structural features. We benchmark four generation methods using Gemini 2.5 Flash Image (Nano Banana) as the generative backbone, evaluating performance on MVTec AD and VisA across two distinct tasks: (i) downstream anomaly segmentation and (ii) visual quality of the generated images, assessed via standard metrics (IS, IC-LPIPS) and a human perceptual study involving 31 participants and 1,550 pairwise votes. The results demonstrate that MIRAGE offers a scalable, accessible foundation for anomaly-aware industrial inspection that requires no real defect data. As a final contribution, we publicly release a large-scale dataset comprising 500 image-mask pairs per category for every MVTec AD and VisA class, over 13,000 pairs in total, alongside all generation prompts and pipeline code.
ProDER: A Continual Learning Approach for Fault Prediction in Evolving Smart Grids
Nov 07, 2025As smart grids evolve to meet growing energy demands and modern operational challenges, the ability to accurately predict faults becomes increasingly critical. However, existing AI-based fault prediction models struggle to ensure reliability in evolving environments where they are required to adapt to new fault types and operational zones. In this paper, we propose a continual learning (CL) framework in the smart grid context to evolve the model together with the environment. We design four realistic evaluation scenarios grounded in class-incremental and domain-incremental learning to emulate evolving grid conditions. We further introduce Prototype-based Dark Experience Replay (ProDER), a unified replay-based approach that integrates prototype-based feature regularization, logit distillation, and a prototype-guided replay memory. ProDER achieves the best performance among tested CL techniques, with only a 0.045 accuracy drop for fault type prediction and 0.015 for fault zone prediction. These results demonstrate the practicality of CL for scalable, real-world fault prediction in smart grids.
Towards Continual Visual Anomaly Detection in the Medical Domain
Aug 25, 2025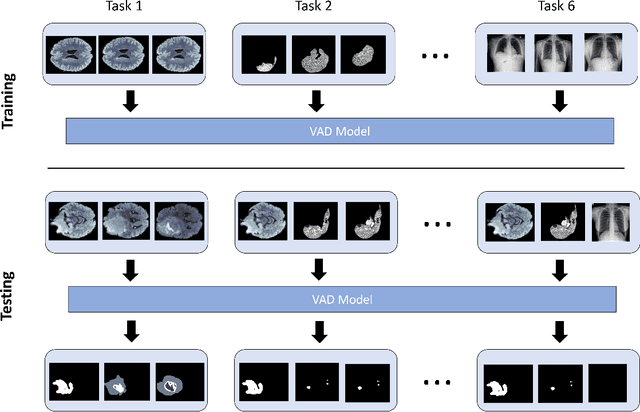
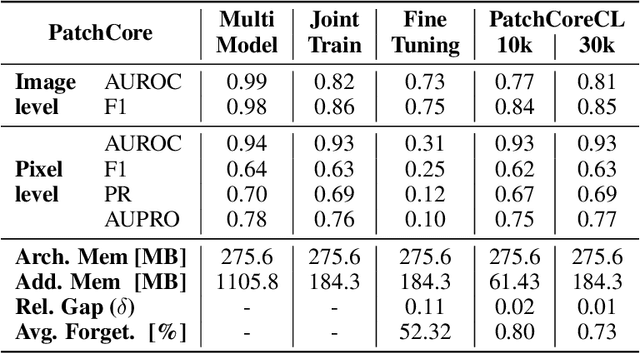
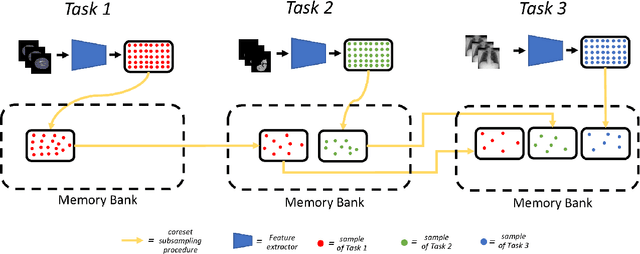
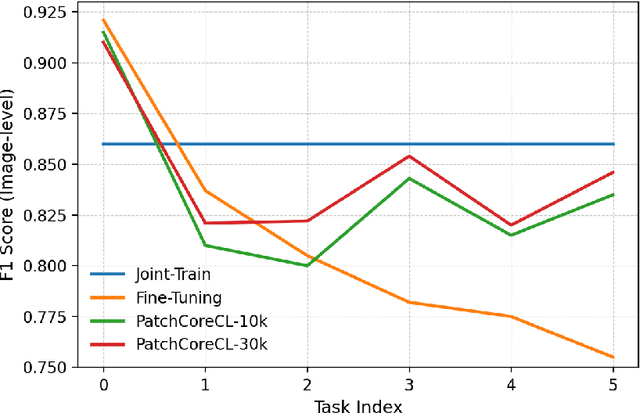
Visual Anomaly Detection (VAD) seeks to identify abnormal images and precisely localize the corresponding anomalous regions, relying solely on normal data during training. This approach has proven essential in domains such as manufacturing and, more recently, in the medical field, where accurate and explainable detection is critical. Despite its importance, the impact of evolving input data distributions over time has received limited attention, even though such changes can significantly degrade model performance. In particular, given the dynamic and evolving nature of medical imaging data, Continual Learning (CL) provides a natural and effective framework to incrementally adapt models while preserving previously acquired knowledge. This study explores for the first time the application of VAD models in a CL scenario for the medical field. In this work, we utilize a CL version of the well-established PatchCore model, called PatchCoreCL, and evaluate its performance using BMAD, a real-world medical imaging dataset with both image-level and pixel-level annotations. Our results demonstrate that PatchCoreCL is an effective solution, achieving performance comparable to the task-specific models, with a forgetting value less than a 1%, highlighting the feasibility and potential of CL for adaptive VAD in medical imaging.
MoViAD: Modular Visual Anomaly Detection
Jul 16, 2025VAD is a critical field in machine learning focused on identifying deviations from normal patterns in images, often challenged by the scarcity of anomalous data and the need for unsupervised training. To accelerate research and deployment in this domain, we introduce MoViAD, a comprehensive and highly modular library designed to provide fast and easy access to state-of-the-art VAD models, trainers, datasets, and VAD utilities. MoViAD supports a wide array of scenarios, including continual, semi-supervised, few-shots, noisy, and many more. In addition, it addresses practical deployment challenges through dedicated Edge and IoT settings, offering optimized models and backbones, along with quantization and compression utilities for efficient on-device execution and distributed inference. MoViAD integrates a selection of backbones, robust evaluation VAD metrics (pixel-level and image-level) and useful profiling tools for efficiency analysis. The library is designed for fast, effortless deployment, enabling machine learning engineers to easily use it for their specific setup with custom models, datasets, and backbones. At the same time, it offers the flexibility and extensibility researchers need to develop and experiment with new methods.
Domain Adaptation for Image Classification of Defects in Semiconductor Manufacturing
Jun 18, 2025In the semiconductor sector, due to high demand but also strong and increasing competition, time to market and quality are key factors in securing significant market share in various application areas. Thanks to the success of deep learning methods in recent years in the computer vision domain, Industry 4.0 and 5.0 applications, such as defect classification, have achieved remarkable success. In particular, Domain Adaptation (DA) has proven highly effective since it focuses on using the knowledge learned on a (source) domain to adapt and perform effectively on a different but related (target) domain. By improving robustness and scalability, DA minimizes the need for extensive manual re-labeling or re-training of models. This not only reduces computational and resource costs but also allows human experts to focus on high-value tasks. Therefore, we tested the efficacy of DA techniques in semi-supervised and unsupervised settings within the context of the semiconductor field. Moreover, we propose the DBACS approach, a CycleGAN-inspired model enhanced with additional loss terms to improve performance. All the approaches are studied and validated on real-world Electron Microscope images considering the unsupervised and semi-supervised settings, proving the usefulness of our method in advancing DA techniques for the semiconductor field.
Towards Scalable IoT Deployment for Visual Anomaly Detection via Efficient Compression
May 15, 2025Visual Anomaly Detection (VAD) is a key task in industrial settings, where minimizing operational costs is essential. Deploying deep learning models within Internet of Things (IoT) environments introduces specific challenges due to limited computational power and bandwidth of edge devices. This study investigates how to perform VAD effectively under such constraints by leveraging compact, efficient processing strategies. We evaluate several data compression techniques, examining the tradeoff between system latency and detection accuracy. Experiments on the MVTec AD benchmark demonstrate that significant compression can be achieved with minimal loss in anomaly detection performance compared to uncompressed data. Current results show up to 80% reduction in end-to-end inference time, including edge processing, transmission, and server computation.
Evaluating Modern Visual Anomaly Detection Approaches in Semiconductor Manufacturing: A Comparative Study
May 12, 2025Semiconductor manufacturing is a complex, multistage process. Automated visual inspection of Scanning Electron Microscope (SEM) images is indispensable for minimizing equipment downtime and containing costs. Most previous research considers supervised approaches, assuming a sufficient number of anomalously labeled samples. On the contrary, Visual Anomaly Detection (VAD), an emerging research domain, focuses on unsupervised learning, avoiding the costly defect collection phase while providing explanations of the predictions. We introduce a benchmark for VAD in the semiconductor domain by leveraging the MIIC dataset. Our results demonstrate the efficacy of modern VAD approaches in this field.